Interesting, HTTPS is almost twice as slow as plain HTTP on my server (~72 ms vs. ~135 ms):
$ hyperfine -r 50 "curl -so /dev/null 'http://movq.de/blog/postings/2024-05-23/0/t/word11a.jpg.jpg'"
Benchmark 1: curl -so /dev/null 'http://movq.de/blog/postings/2024-05-23/0/t/word11a.jpg.jpg'
Time (mean ± σ): 72.7 ms ± 17.2 ms [User: 6.2 ms, System: 4.8 ms]
Range (min … max): 49.5 ms … 99.7 ms 50 runs
$ hyperfine -r 50 "curl -so /dev/null 'https://movq.de/blog/postings/2024-05-23/0/t/word11a.jpg.jpg'"
Benchmark 1: curl -so /dev/null 'https://movq.de/blog/postings/2024-05-23/0/t/word11a.jpg.jpg'
Time (mean ± σ): 135.5 ms ± 28.9 ms [User: 17.8 ms, System: 5.6 ms]
Range (min … max): 93.2 ms … 198.5 ms 50 runs
Ran 4.5 km (2.8 miles) at the lake, middle of the day, 31 degrees! I’m a glutton for punishment.
The newsletter feature coming with Mastodon 4.6 also looks very interesting. Could be a good starting point for users who don‘t want to create an account but follow users. Maybe then the next step is to eventually create an account.#mastodon
Version 4.6 of Mastodon Collections introduces lists of users to make it easier to find accounts on specific topics.https://maurice-renck.de/en/blog/2026/mastodon-collections
In Magic today, the Phyrexian Invasion failed in the first game, but the second game was EPIC!
I played my (unlisted) Dragons 2: Draconic Boogaloo deck, and…
Turn 1: Nothing special
Turn 2: Miirym (when a dragon enters, copy it)
Turn 3: Tiamat (choose 5 dragons from deck, put in hand)
Turn 4: Klauth (when dragons attack, create mana equal to their total power)
I attacked with all 5 dragons, which made 28 mana x2 = 56(!) mana.
Then (still turn 4) I played Scourge of Valkas (when a dragon enters, deal damage to target equal to number of dragons) + 5 other dragons, dealing 6 + 2 x (7+8+9+10+11+12+13+14+15+16+17) = 270(!) direct damage (more than double enough to kill the other 3 players).
Damn fine win, if I do say so myself.
Every now and then, I think that I have carefully proof-read my message enough times and hit the “Add message” button in tt. But then, in the message tree, I spot another missed typo. My process is then to go to my twtxt.txt and fix it by hand. However, I still have to clean up tt’s cache. This is rather tidious:
- Recall the
sqlitebrowser ~/.local/share/twtxt/tt2.sqlitefrom my shell history.
- Switch to the “Browse data” tab.
- Go to the
messagestable and wait a second or two until it’s loaded.
- Sort by the
created_atcolumn twice, so that I get descending order.
- Select the first message, which is typically the one in question.
- Find the “Remove currently selected row” button in the tool bar.
- Commit the changes.
- Close sqlitebrowser.
So, I finally implemented the removal of messages from the cache in tt. I can now hit d and confirm the removal. Bam! Should have done that ages ago!
https://lyse.isobeef.org/tmp/tt-confirm-message-removal.png
{kind=link}
Next up is the search, I think.
↳
In-reply-to
»
It was an easy patch, so menus have drop shadows now:
⤋ Read More
@movq@www.uninformativ.de Exactly! :-D
I just came across these two covers which stood out to me:
- https://www.youtube.com/watch?v=tVvhHydubR0
played a bit faster, and faster is almost always better
- https://www.youtube.com/watch?v=rpwGUx0Sz_4
a choire’s polyphony usually makes things automatically better
Installing OS/2Warp 4 in 86Box as we speak… Why? Because I can!
↳
In-reply-to
»
what is the user-agent name of the crawler that pulls the tweets here on twtxt.net? i am seeing getwtxt-ng/dev and twtstrm/0.4.0 in the logs
⤋ Read More
@klaxzy@klaxzy.net twtstrm/0.4.0 is from Eric. The getwtxt-ng/dev seems to be this.
what is the user-agent name of the crawler that pulls the tweets here on twtxt.net? i am seeing getwtxt-ng/dev and twtstrm/0.4.0 in the logs
↳
In-reply-to
»
Really nothing spectacular at all today, but yet we still got some red for less than five minutes: https://lyse.isobeef.org/abendhimmel-2026-04-27/ Azabache was hiding somewhere in the trees, I could hear him very well, but not lay my eye on him. The leaves are already covering him up perfectly now.
⤋ Read More
@lyse@lyse.isobeef.org 4 is a keeper! Wish it was landscape, perfect for a wall then. :-P
I won our only game of Magic for this week with my (yet-to-be published) “Bolas Triumphant” deck: 5 players over 3 hours, including 4 board wipes (one of which came from my Nicol Bolas, God-Pharaoh), and I even got to cast Omniscience via a Fae of Wishes. I can’t speak for everyone, but I know I had a good time. 😁
What do the Gopher Troopers think of the following? The Gopher protocol is a nearly-forgotten network protocol from the early 1990s, designed to serve and navigate text-based menus and documents over the Internet. While its far less common than HTTP/HTTPS today, there are still some security risks associated with Gopher and Gopher space. Lets break them down carefully: 1. Lack of Encryption Problem: Gopher was designed long before widespread use of SSL/TLS. All dataincluding credentials, file transfers, and menu selectionsis transmitted in plaintext. Impact: Anyone intercepting traffic (e.g., via a network sniffer, public Wi-Fi, or a compromised router) can read sensitive information, including usernames and passwords. 2. No Authentication or Access Control Problem: Gopher servers rarely implement robust authentication; access control is usually limited or non-existent. Impact: Unauthorized users might browse sensitive directories or download private files, particularly if servers are misconfigured. 3. Server Software Vulnerabilities Problem: Modern OSes can still run legacy Gopher servers, but the software is often unmaintained. Impact: Old software may contain buffer overflows, directory traversal bugs, or command injection vulnerabilities that attackers could exploit. 4. Malicious Gopher Links Problem: Gopher menus can contain links that point to scripts or other servers, similar to hyperlinks in HTTP. A client following a malicious link could inadvertently: Download malware Access sensitive internal network resources (server-side request forgery) Impact: Could serve as a vector for attacks if a user opens content from untrusted sources. 5. Legacy Protocol Weaknesses Problem: Gopher lacks modern web security mechanisms like: Content security policies Same-origin policies Cross-site request forgery protection Impact: If Gopher is bridged to other services (like modern browsers via gateways), old vulnerabilities may be exposed. 6. Information Leakage Problem: Gopher servers often provide directory listings without restriction. Impact: Sensitive files, backup directories, and internal documents may be exposed unintentionally. 7. Bridging Risks Problem: Some modern browsers access Gopher via gateways (HTTP-to-Gopher proxies). These bridges may: Expose sensitive internal resources to the gateway Introduce logging or tracking that wouldnt exist on pure Gopher Impact: Attacks could occur indirectly through insecure intermediaries. Key Takeaways Gopher is inherently insecure due to its design in a pre-HTTPS era. Main threats: eavesdropping, unauthorized access, malware delivery, and exploitation of unpatched server software. Safe practice: Use Gopher only in isolated, trusted environments, or through secure HTTP(S) gateways with proper sanitization.
Ezekiel 4:12 …words to live by
↳
In-reply-to
»
Just showelled 20cm of snow for half an hour, fuck me! I'm totally shattered. But it's worth it. Looks so beautiful. And all the disbelief and terror in the eyes of the people. Well, that's what our winters were like three decades ago. I'm just glad that I can work from home.
⤋ Read More
I’ve got sore muscles. The sticky snow couldn’t be pushed, it had to be laborously cleared shovel by shovel. :-D
In my lunch break, I went on a short stroll. Oh boy, walking through deep damp snow is exhausting! There were sections with easily 30 centimeters and more. Some big wind drifts had piled up. Despite melting off quickly in the 4°C, especially turning the trees brown again, the white landscape still looks so nice. I’m glad these road marking sticks finally came in handy for the snow plow guys. :-) The black and orange stripes are 30 cm high.
https://lyse.isobeef.org/waldspaziergang-2026-01-26/
That’s probably it. There’s no significant snowfall announced for the rest of the week and temperatures are supposed to stay in the 2-4°C range by day.
My mate and I went on a hike earlier. Yesterday, we had lovely 12°C. But today, it was down to at most 4°C. Oh well. At least the sun was out and and there was just a tiny bit of wind. We knew upfont that scarf, beanie and gloves were mandatory. Especially at the more windy sections like up top the hills. The view was absolutely terrible, but we made the best of it.
With the sun shining on us during our lunch break at a forest edge bench, we still enjoyed the lookout in 01. I brought some old carpet scraps to sit on and was happily surprised that they isolated even better than I had hoped for. Some hot tea helped us staying warm.
After five hours we returned just after sunset. I’m quite tired now, completely out of shape.
↳
In-reply-to
»
https://github.com/unix-v4-commentary/unix-v4-source-commentary
⤋ Read More
Wow, as I anticipated, this is waaay out of my capabilities to really understand it. But I’m quite happy to just have spotted a mistake in an explanatory comment in section 4.5.2 “The icode Array”. Of course, it should be /e + tc + /i + ni + t\0. Let’s hope that my e-mail with the patch actually makes it into Briam’s inbox. I fear GMail just hides it in the spam folder.
@eldersnake@we.loveprivacy.club
Steps to world domination:
- “Invent” “AI” (by using other people’s data).
- Get people hyped about it and ideally hooked on it.
- Only provide it as a cloud service. But hey, if you want to, you can run it locally!
- Buy all hardware available on the market, so that nobody but you can build more systems.
- All PCs of consumers and competitors are too weak now and can’t be upgraded anymore.
- Everybody depends on your cloud service! Win!
All of that is possible because corporations don’t have a “conscience” in capitalism. Nobody forces the RAM manufacturers to sell all their stuff to just one or two buyers, but since the only goal of that manufacturer is to make money, they do it.
The tt URLs View now automatically selects the first URL that I probably are going to open. In decreasing order, the URL types are:
- markdown media URLs (images, videos, etc.)
- markdown or plaintext URLs
- subjects
- mentions
I might differentiate between mentions of subscribed and unsubscribed feeds in the future. The odds of opening a new feed over an already existing one are higher.
Wishing everybody a good morning of the last sunday before Xmas. As we say here in Germany: einen schönen 4. Advent!
I just completed “Printing Department” - Day 4 - Advent of Code 2025 #AdventOfCode https://adventofcode.com/2025/day/4 – Again, I’m doing this in mu, a Go(ish) / Python(ish) dynamic langugage that I had to design and build first which has very few builtins and only a handful of types (ints, no flots). 🤣
↳
In-reply-to
»
Advent of Code 2025 starts tomorrow. 🥳🎄
⤋ Read More
Alright, Advent of Code is over:
https://www.uninformativ.de/blog/postings/2025-12-12/0/POSTING-en.html
It’s been quite the time sink, especially with the DOS games on top, but it was fun. 🥳
In case you’re wondering: All puzzles (except for part 2 of day 10) were doable in Python 1 on SuSE Linux 6.4 and ran in a finite time on the Pentium 133. Puzzle 10/2 might have been doable as well if I had better education. 🤣
↳
In-reply-to
»
Advent of Code 2025 starts tomorrow. 🥳🎄
⤋ Read More
FWIW, day 03 and day 04 where solved on SuSE Linux 6.4:
https://movq.de/v/faaa3c9567/day03.jpg
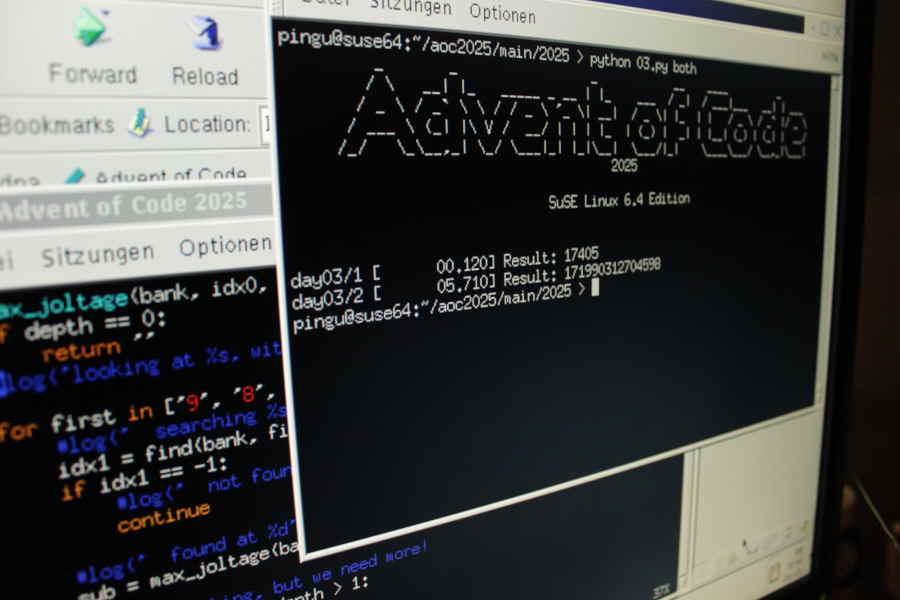{kind=link}
https://movq.de/v/faaa3c9567/day04%2Dv3.jpg
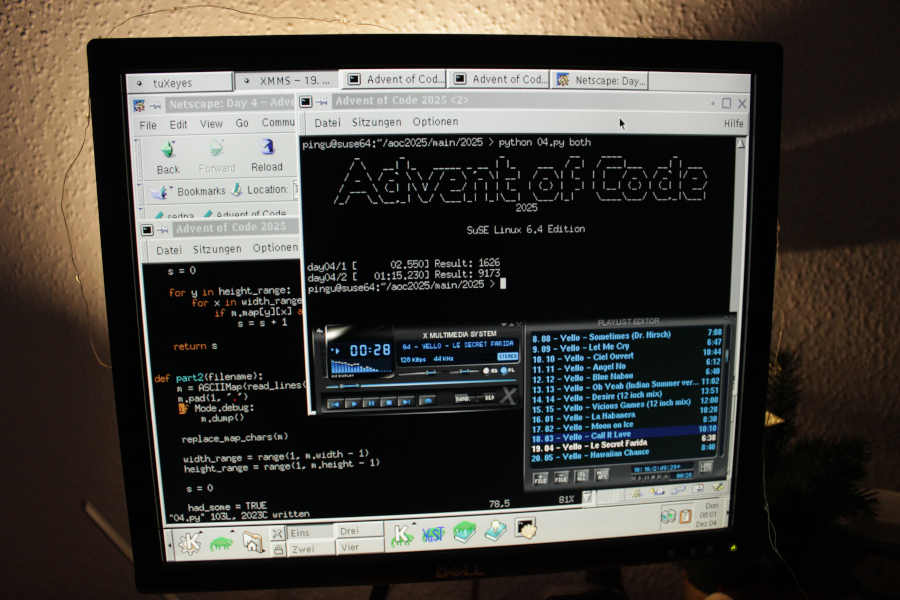{kind=link}
Performance really is an issue. Anything is fast on a modern machine with modern Python. But that old stuff, oof, it takes a while … 😅
Should have used C or Java. 🤪 Well, maybe I do have to fall back on that for later puzzles. We’ll see.
Advent of Code 2025 starts tomorrow. 🥳🎄
This year, I’m going to use Python 1 on SuSE Linux 6.4, writing the code on my trusty old Pentium 133 with its 64 MB of RAM. No idea if that old version of Python will be fast enough for later puzzles. We’ll see.
Arsenal 4-1 Tottenham
Better Technology, Worse Motivation: GenAI’s Mediocrity Trap
While generative AI (GenAI) promises productive efficiency, it can paradoxically lead to lower-quality work. We conducted an experiment with professional illustrators and found that AI assistance flattens the quality curve—it accelerates initial gains but sharply diminishes the returns on sustained effort. Faced with this, a significant number of professionals made a strategic choice: they sacrificed the final quality to save time.
From http://www.jin-li.org/uploads/1/1/4/5/114595093/ai_and_motivation.pdf
I haven’t read this and can’t vouch for it; seems vaguely AI-boostery. Still, the conclusions are interesting. This seems to be the picture that is emerging about generative AI generally: most people don’t like it and find that degrades the quality of work. Coders seem to like it and think that it helps them, but in fact it makes the slower, less productive, and more bug prone.
By all measures it’s a bad technology. We should just be honest about it. There is no need to make excuses for multi-trillion-dollar corporations.
↳
In-reply-to
»
@bender It's good enough ti iron out any bugs 🐛 Can I haz an account? 🙏
⤋ Read More
@prologic@twtxt.net I will share later my GoToSocial 10 lines (or less) config.yaml, and 4 lines Caddyfile, and you will see how easy it is.
↳
In-reply-to
»
And regarding those broken URLs: I once speculated that these bots operate on an old dataset, because I thought that my redirect rules actually were broken once and produced loops. But a) I cannot reproduce this today, and b) I cannot find anything related to that in my Git history, either. But it’s hard to tell, because I switched operating systems and webservers since then …
⤋ Read More
@lyse@lyse.isobeef.org Probably wouldn’t help, since almost every request comes from a different IP address. These are the hits on those weird /projects URLs since Sunday:
1 IP has 5 hits
1 IP has 4 hits
13 IPs have 3 hits
280 IPs have 2 hits
25543 IPs have 1 hit
The total number of hits has decreased now. Maybe the botnet has moved on …
↳
In-reply-to
»
There are no really good GUI toolkits for Linux, are there?
⤋ Read More
@movq@www.uninformativ.de Don’t you worry, this was meant as a joke. :-D
There was a time when I thought that Swing was actually really good. But having done some Qt/KDE later, I realized how much better that was. That were the late KDE 3 and early KDE 4 days, though. Not sure how it is today. But back then it felt Trolltech and the KDE folks put a hell lot more thought into their stuff. I was pleasantly surprised how natural it appeared and all the bits played together. Sure, there were the odd ends, but the overall design was a lot better in my opinion.
To be fair, I never used it from C++, always the Python bindings, which were considerably more comfortable (just alone the possibility to specify most attributes right away as kwargs in the constructor instead of calling tons of setters). And QtJambi, the Java binding, was also relatively nice. I never did a real project though, just played around with the latter.
↳
In-reply-to
»
@lyse it hasn't happened yet. It is this coming Saturday.
⤋ Read More
@bender@twtxt.net Hm, are we talking about different dates or are there different timezone offsets for this timezone abbreviation? With EDT being UTC-4, 2025-11-02T12:00:00Z is Sunday at 8:00 in the morning local time for you. Or were did I mess up here? :-?
@prologic@twtxt.net You want me to submit a reply with “I probably won’t show up”?
- Negativity bias increases clicks. 2) Extreme opinions increase sharing. 3) Out-group animosity increases engagement. 4) Moral-emotional language goes viral. All the sad young terminally online men | Hacker News
↳
In-reply-to
»
@lyse That looks like an older bug report. Which groff version is that (
⤋ Read More
groff --version)?
@movq@www.uninformativ.de It’s an ancient 1.22.4. :-)
Hey @itsericwoodward@itsericwoodward.com, I just wanna let you know that twtstrm/0.4.0 sends a broken User-Agent header. Instead of the URL, the nick is repeated.
↳
In-reply-to
»
@itsericwoodward any news about this? I am, at the very least, curious!
⤋ Read More
@bender@twtxt.net Thanks for asking!
So, I’ve been working on 2 main twtxt-related projects.
The first is small Node / express application that serves up a twtxt file while allowing its owner to add twts to it (or edit it outright), and I’ve been testing it on my site since the night I made that post. It’s still very much an MVP, and I’ve been intermittently adding features, improving security, and streamlining the code, with an eye to release it after I get an MVP done of project #2 (the reader).
But that’s where I’ve been struggling. The idea seems simple enough - another Node / express app (this one with a Vite-powered front-end) that reads a public twtxt file, parses the “follow” list, grabs (and parses) those twtxt files, and then creates a river of twts out of the result. The pieces work fine in seclusion (and with dummy data), but I keep running into weird issues when reading real-live twtxt files, so some twts come through, while others get lost in the ether. I’ll figure it out eventually, but for now, I’ve been spending far more time than I anticipated just trying to get it to work end-to-end.
On top of it, the 2 projects wound up turning into 4 (so far), as I’ve been spinning out little libraries to use across both apps (like https://jsr.io/@itsericwoodward/fluent-dom-esm, and a forthcoming twtxt helper library).
In the end, I’m hoping to have project 1 (the editor) into beta by the end of October, and project 2 (the reader) into beta sometime after that, but we’ll see.
I hope this has satisfied your curiosity, but if you’d like to know more, please reach out!
↳
In-reply-to
»
@itsericwoodward any news about this? I am, at the very least, curious!
⤋ Read More
@bender@twtxt.net Thanks for asking!
So, I’ve been working on 2 main twtxt-related projects.
The first is small Node / express application that serves up a twtxt file while allowing its owner to add twts to it (or edit it outright), and I’ve been testing it on my site since the night I made that post. It’s still very much an MVP, and I’ve been intermittently adding features, improving security, and streamlining the code, with an eye to release it after I get an MVP done of project #2 (the reader).
But that’s where I’ve been struggling. The idea seems simple enough - another Node / express app (this one with a Vite-powered front-end) that reads a public twtxt file, parses the “follow” list, grabs (and parses) those twtxt files, and then creates a river of twts out of the result. The pieces work fine in seclusion (and with dummy data), but I keep running into weird issues when reading real-live twtxt files, so some twts come through, while others get lost in the ether. I’ll figure it out eventually, but for now, I’ve been spending far more time than I anticipated just trying to get it to work end-to-end.
On top of it, the 2 projects wound up turning into 4 (so far), as I’ve been spinning out little libraries to use across both apps (like https://jsr.io/@itsericwoodward/fluent-dom-esm, and a forthcoming twtxt helper library).
In the end, I’m hoping to have project 1 (the editor) into beta by the end of October, and project 2 (the reader) into beta sometime after that, but we’ll see.
I hope this has satisfied your curiosity, but if you’d like to know more, please reach out!
↳
In-reply-to
»
Here is just a small list of things™ that I'm aware will break, some quite badly, others in minor ways:
⤋ Read More
@prologic@twtxt.net I know we won’t ever convince each other of the other’s favorite addressing scheme. :-D But I wanna address (haha) your concerns:
I don’t see any difference between the two schemes regarding link rot and migration. If the URL changes, both approaches are equally terrible as the feed URL is part of the hashed value and reference of some sort in the location-based scheme. It doesn’t matter.
The same is true for duplication and forks. Even today, the “cannonical URL” has to be chosen to build the hash. That’s exactly the same with location-based addressing. Why would a mirror only duplicate stuff with location- but not content-based addressing? I really fail to see that. Also, who is using mirrors or relays anyway? I don’t know of any such software to be honest.
If there is a spam feed, I just unfollow it. Done. Not a concern for me at all. Not the slightest bit. And the byte verification is THE source of all broken threads when the conversation start is edited. Yes, this can be viewed as a feature, but how many times was it actually a feature and not more behaving as an anti-feature in terms of user experience?
I don’t get your argument. If the feed in question is offline, one can simply look in local caches and see if there is a message at that particular time, just like looking up a hash. Where’s the difference? Except that the lookup key is longer or compound or whatever depending on the cache format.
Even a new hashing algorithm requires work on clients etc. It’s not that you get some backwards-compatibility for free. It just cannot be backwards-compatible in my opinion, no matter which approach we take. That’s why I believe some magic time for the switch causes the least amount of trouble. You leave the old world untouched and working.
If these are general concerns, I’m completely with you. But I don’t think that they only apply to location-based addressing. That’s how I interpreted your message. I could be wrong. Happy to read your explanations. :-)
↳
In-reply-to
»
@zvava @lyse I also think a location based reference might be better.
⤋ Read More
@prologic@twtxt.net I can see the issues mentioned, but I think some can be fixed.
The current hash relies on a
urlfield too, by specification, it will use the first# url = <URL>in the feed’s metadata if present, that too can be different from the fetching source, if that field changes it would break the existing hashes too, a better solution would be to use a non-URL key like# feed_id = <UNIQUE_RANDOM_STRING>with theurlas fallback.We can prevent duplications if the reference uses that same url field too or the client “collapse” any reference of all the urls defined in the metadata.
I agree that hashing based on content is good, but we still use the URL as part of the hashing, which is just a field in the feed, easily replicable by a bot, also noting that edits can also break the hash, for this issue an alternative solution (E.g. a private key not included in the feed) should be considered.
For offline reading the source would be downloaded already, the fetching of non followed feeds would fill the gap in the same way mentions does, maybe I’m missing some context on this one.
To prevent collisions there was a discussion on extending the hash (forgot if that was already fixed or not), but without a fallback that would break existing clients too, we should think of a parallel format that maintains current implementations unchanged, we are already backward compatible with the original that don’t use threads at all, a mention style format for that could be even more user-friendly for those clients.
We should also keep in mind that the current mention format is already location based (@<example https://example.com/twtxt.txt>) so I’m not that worried about threads working the same way.
Hope to see some other thought about this matter. 🤓
For some time I’ve been trying to spend a fair amount of my running or jumping time in Zone 5, the hardest. After a little research I’m learning that maybe I should be concentrating more on Zone 4 instead.
I’ve got a prototype of my hardcopy simulator going. I’m typing on the keyboard and the “display” goes to the printer:
https://movq.de/v/56feb53912/s.png
{kind=link}
https://movq.de/v/235c1eabac/MVI_8810.MOV.mp4
The biiiiiiiiiig problem is that the print head and plastic cover make it impossible to see what’s currently being printed, because this is not a typewriter. This means: In order to see what I just entered, I have to feed the paper back and forth and back and forth … it’s not ideal.
I got that idea of moving back/forth from Drew DeVault, who – as it turned out – did something similar a few years back. (I tried hard to read as little as possible of his blog post, because figuring things out myself is more fun. But that could mean I missed a great idea here or there.)
But hey, at least this is running on my Pentium 133 on SuSE Linux 6.4, printer connected with a parallel cable. 😍
(Also, yes, you can see the printouts of earlier tests and, yes, I used ed(1) wrong at one point. 🤪 And ls insisted on using colors …)
↳
In-reply-to
»
Bloody AI clowns:
⤋ Read More
Here’s an interesting thought/angle on this topic:
gemini://gemini.conman.org/boston/2025/08/21.1
A further check showed that all the network blocks are owned by one organization—Tencent [4]. I’m seriously thinking that the CCP (Chinese Communist Party) encourage this with maybe the hope of externalizing the cost of the Great Firewall [5] to the rest of the world.
↳
In-reply-to
»
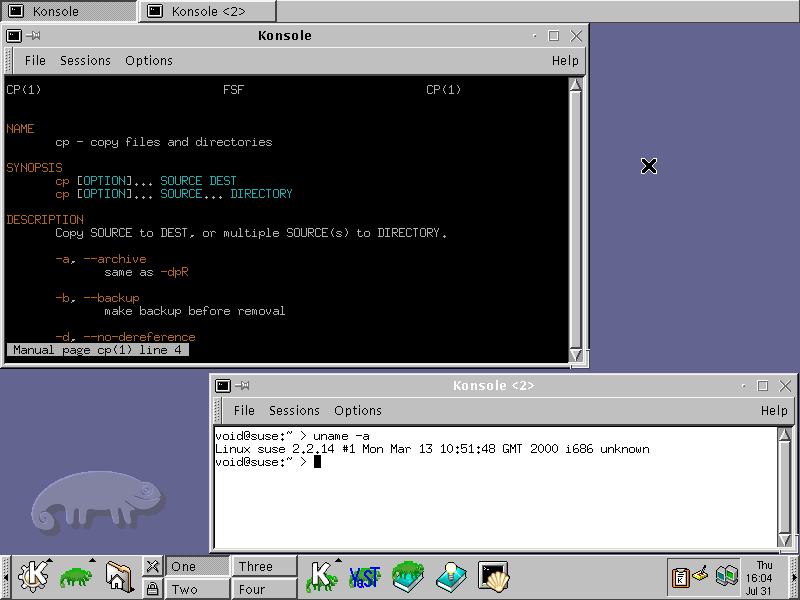
@lyse @kat Colorized manpages have been a thing for a very long time:
⤋ Read More
(Just for fun, SuSE Linux 6.4 from ~25 years ago: https://movq.de/v/dc62d0256c/s.png )
{kind=link}
↳
In-reply-to
»
Speaking of manpages:
⤋ Read More
@lyse@lyse.isobeef.org @kat@yarn.girlonthemoon.xyz Colorized manpages have been a thing for a very long time:
https://movq.de/v/81219d7f7a/s.png
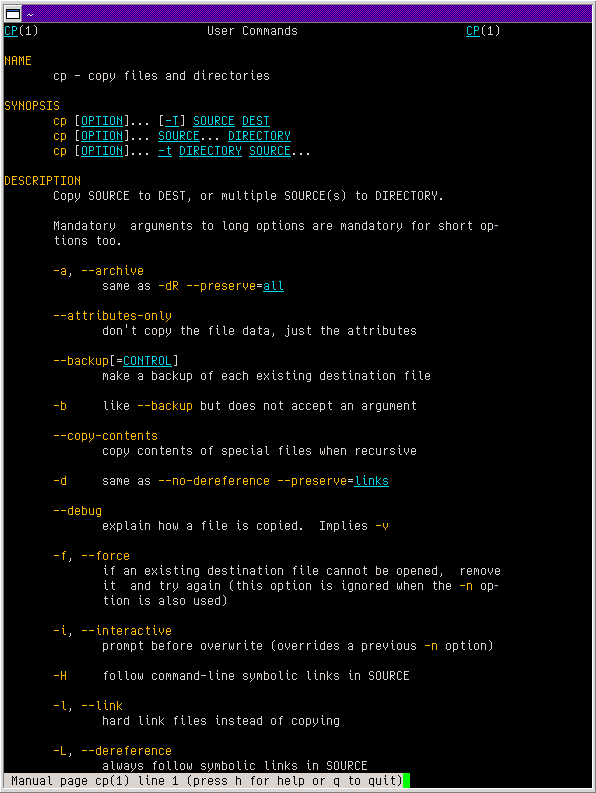{kind=link}
Problem is, hardly anybody knows this, because you configure this by … drumroll … overwriting TERMCAP entries of less in your ~/.bashrc:
export LESS_TERMCAP_md=$'\e[38;5;3m' # Bold
export LESS_TERMCAP_me=$'\e[0m' # End Bold
export LESS_TERMCAP_us=$'\e[4;38;5;6m' # Underline
export LESS_TERMCAP_ue=$'\e[0m' # End Underline
export GROFF_NO_SGR=1 # Needed since groff 1.23
↳
In-reply-to
»
wrote a script to make epic aesthetic half tone images and i was impressed with myself how fast i did it but to be fair i already had the commands noted down and i just had to script it lmfao
⤋ Read More
@kat@yarn.girlonthemoon.xyz https://snippets.4-walls.net/kat/890f9db00b1940679161d0348b28c339
↳
In-reply-to
»
Do I buy a new monitor or do I live with the burn-ins all the time? It’s getting annoying. When I edit images in GIMP, I have to double check if something is a pixel or a burn-in.
⤋ Read More
@lyse@lyse.isobeef.org 4 years. 🫤
i am having fun with dmenu
https://bytes.4-walls.net/kat/dotfiles/src/branch/main/config/.local/bin/dict
https://bytes.4-walls.net/kat/dotfiles/commit/b5ca2e0eaba3cbc0cf0898926ffcb0bb064d17c7
↳
In-reply-to
»
i wanna figure out more things to do with dmenu but i don't really know man the emoji picker is hard to beat
⤋ Read More
@kat@yarn.girlonthemoon.xyz NVM i stole other peoples code to make a dictionary lookup script https://bytes.4-walls.net/kat/dotfiles/src/branch/main/config/.local/bin/dict
↳
In-reply-to
»
Xfce does one thing very right: It stores its settings in plain-text XML files. This allows me to easily read, track, and maybe even distribute these settings to other machines.
⤋ Read More
@lyse@lyse.isobeef.org @kat@yarn.girlonthemoon.xyz I spent so much time in the past figuring out if something is a dict or a list in YAML, for example.
What are the types in this example?
items:
- part_no: A4786
descrip: Water Bucket (Filled)
price: 1.47
quantity: 4
- part_no: E1628
descrip: High Heeled "Ruby" Slippers
size: 8
price: 133.7
quantity: 1
items is a dict containing … a list of two other dicts? Right?
It is quite hard for me to grasp the structure of YAML docs. 😢
The big advantage of YAML (and JSON and TOML) is that it’s much easier to write code for those formats, than it is with XML. json.loads() and you’re done.
The WM_CLASS Property is used on X11 to assign rules to certain windows, e.g. “this is a GIMP window, it should appear on workspace number 16.” It consists of two fields, name and class.
Wayland (or rather, the XDG shell protocol – core Wayland knows nothing about this) only has a single field called app_id.
When you run X11 programs under Wayland, you use XWayland, which is baked into most compositors. Then you have to deal with all three fields.
Some compositors map name to app_id, others map class to app_id, and even others directly expose the original name and class.
Apparently, there is no consensus.
↳
In-reply-to
»
This aggressive auto-logout on my bank’s website …
⤋ Read More
@movq@www.uninformativ.de Yeah, it’s a shitshow. MS overconfirms all my prejudices constantly.
Ignoring e-mail after lunch works great, though. :-)
Our timetracking is offline for over a week because of reasons. The responsible bunglers are falling by the skin of their teeth: https://lyse.isobeef.org/tmp/timetracking.png
{kind=link}
- The error message neither includes the timeframe nor a link to an announcement article.
- The HTML page needs to download JS in order to display the fucking error message.
- Proper HTTP status codes are clearly only for big losers.
- Despite being down, heaps of resources are still fetched.
I find it really fascinating how one can screw up on so many levels. This is developed inhouse, I’m just so glad that we’re not a software engineering company. Oh wait. How embarrassing.
↳
In-reply-to
»
The lack of suckless-like simple, hackable software these days is appalling.
⤋ Read More
@prologic@twtxt.net Yeah, this really could use a proper definition or a “manifest”. 😅 Many of these ideas are not very wide spread. And I haven’t come across similar projects in all these years.
Let’s take the farbfeld image format as an example again. I think this captures the “spirit” quite well, because this isn’t even about code.
This is the entire farbfeld spec:
farbfeld is a lossless image format which is easy to parse, pipe and compress. It has the following format:
╔════════╤═════════════════════════════════════════════════════════╗
║ Bytes │ Description ║
╠════════╪═════════════════════════════════════════════════════════╣
║ 8 │ "farbfeld" magic value ║
╟────────┼─────────────────────────────────────────────────────────╢
║ 4 │ 32-Bit BE unsigned integer (width) ║
╟────────┼─────────────────────────────────────────────────────────╢
║ 4 │ 32-Bit BE unsigned integer (height) ║
╟────────┼─────────────────────────────────────────────────────────╢
║ [2222] │ 4x16-Bit BE unsigned integers [RGBA] / pixel, row-major ║
╚════════╧═════════════════════════════════════════════════════════╝
The RGB-data should be sRGB for best interoperability and not alpha-premultiplied.
(Now, I don’t know if your screen reader can work with this. Let me know if it doesn’t.)
I think these are some of the properties worth mentioning:
- The spec is extremely short. You can read this in under a minute and fully understand it. That alone is gold.
- There are no “knobs”: It’s just a single version, it’s not like there’s also an 8-bit color depth version and one for 16-bit and one for extra large images and one that supports layers and so on. This makes it much easier to implement a fully compliant program.
- Despite being so simple, it’s useful. I’ve used it in various programs, like my window manager, my status bars, some toy programs like “tuxeyes” (an Xeyes variant), or Advent of Code.
- The format does not include compression because it doesn’t need to. Just use something like bzip2 to get file sizes similar to PNG.
- It doesn’t cover every use case under the sun, but it does cover the most important ones (imho). They have discussed using something other than RGBA and decided it’s not worth the trouble.
- They refrained from adding extra baggage like metadata. It would have needlessly complicated things.