↳
In-reply-to
»
@lyse Oh wow, we’re talking about such a detailed level. 🤔
⤋ Read More
@movq@www.uninformativ.de Yeah, that would also be fine with me. I certainly do like the “arbitrary” in your comment.
While writing the article, I also thought about something like that:
date := time.Date(2026, 6, 19,
17, 0, 0, 0, time.UTC)
Or possibly:
date := time.Date(
2026, 6, 19,
17, 0, 0, 0, time.UTC,
)
But it’s four lines for a damn timestamp. I also contemplated whether a comment acting as a separator is all that’s needed:
date := time.Date(2026, 6, 19, /**/ 17, 0, 0, 0, time.UTC)
I might like that the most. Not entirely sure yet. It kinda feels like a hack, but still a little elegant. Add your comment on top and we’re golden. Maybe?
I deliberately excluded them as this only distracted from the points I wanted to make. And I also realized that this example was just not ideal at all. Perhaps I should add them nevertheless?
If I ever invented a programming language, a much more human readable timestamp representation of some sort, RFC 3339 or very close to that would be part of that language. Something along the lines of /pattern/ for regexes in certain languages.
I noticed that there are quite a few UI glitches in vim-classic – and quickly found the cause: It comes with outdated Unicode tables.
I have to admit that I wasn’t aware that there’s a new Unicode release every year:
https://en.wikipedia.org/wiki/Unicode#Versions
Look at this huge number of changes. Every program has to keep track of that, often through libraries but sometimes not (like in Vim’s case).
I use Unicode extensively, but this shit is extremely expensive …
My TUI framework is having the same problem. At the moment, this is all offloaded to wcwidth, but if that library was to become unmaintained, I’d have to track Unicode myself.
Gah!
The DOS days were simpler. CP437, end of story. (Yes, I know that’s a lie.)
↳
In-reply-to
»
@lyse Ah, you mean the categorization. Yeah, that would never work in Windows, at least not without having a centralized package manager (so there’s one authoritative source of which program belongs into which category).
⤋ Read More
@movq@www.uninformativ.de That’s right, way harder than centrally managed. They even didn’t reach concensus over the main folder: “Alle Programme, “Alle Programme (x86)”, “All Programs”, “All Programmes”, etc. Anyway.
For class 11 (or maybe already in 10, I don’t remember exactly) we could choose either between traditional maths class with a graphical calculator or “Mathe mit CAS”. There were two teachers in my entire school who were able to teach the latter. It was also fairly new at the time I believe. Certainly unheard of for a „allgemeinbildendes Gymnasium“, maybe the technical ones were already offering it for some time, not sure. It was clear to me that I would take the maths with CAS class.
Each kid had to buy their own Cassiopeia A-Something. I don’t know how much that thing was (definitely more expensive than a graphical calculator) and whether the school subsidized that in any form. But it was slow and underpowered as hell. We rarely used it in class nor for homework (most if not all had already a desktop at home). Typically, when we worked with the CAS, we sat down on the desktop computers. Our class took place in one of the two computer rooms. The desktops were placed on the three sides (left, right, back, facing the walls or windows) and the regular school desks were in the middle. Since there were more pupils than desktops, we always shared. Nowadays, we call it pair programming. ;-)
For the exams we had the “mandatory part” (Pflichtteil) without any tools. Once we finished that and handed the papers to our teacher, we were then allowed to boot up our Cassiopeias and work with them for the second part. Before the exam started, everyone had to show the teacher that they reset their small computer to factory settings. This second part was called „Wahlteil“. But you had to do it in order to pass. So, I never understood the choice of this term. Maybe it’s because the first part is the exact same for everyone (graphical calculator and CAS class), but the second part was definitely different for the two classes. Each suited to their tools.
After one or two exams, it became clear that the Cassiopeia was far from ideal. So, we took the second part at the desktop computers from then on. Our teacher unplugged the network cables himself to avoid cheating. Each computer had an “HDD Sheriff” running that reset the disk at startup. There was also an issue that the personal user accounts were affected by that. Sometimes all your data were lost. If you were lucky, they were still there. So, we saved our Maple project to local disk (if the computer didn’t crash in between, that was no problem) and at least eventually before leaving the classroom, we then also saved it on the server. For that, the teacher quickly plugged in the cable, we saved, and then the cable was unplugged again immediately. Oh, and everybody used their USB sticks, too.
All in all, this Cassiopeia A-* was quite a useless purchase. :-D I’m not sure if I still have it. At least I thought several times about giving it to the flea market. Don’t know if I did or not.
↳
In-reply-to
»
@lyse In what way was KDE 3’s menu organized? KDE 1 is the only KDE version I ever used. 😅 We’re talking about this one, right?
⤋ Read More
{kind=link}
@lyse@lyse.isobeef.org Ah, you mean the categorization. Yeah, that would never work in Windows, at least not without having a centralized package manager (so there’s one authoritative source of which program belongs into which category).
Oh wow, those Cassiopeias look pretty cool. Did you have one of those or one for each kid?
Speaking of UIs, this is how Thunderbird looks now:
So we continue to let every program make up its own UI style (and then we complain that “the Linux desktop” looks “messy” and “inconsistent”). I guess this uses GTK, but it doesn’t look like any other GTK program. Buttons, tabs, drop-downs, whatever, it’s all different. It even has its own subwindow system (i.e., popups that you can’t move).
I didn’t say this in the blog post, but I’m convinced that programmers these days absolutely positively hate everything that looks even remotely like Windows 95 or Motif – with a passion. I see that in my coworkers as well, they really can’t stand it. It’s an emotional thing.
↳
In-reply-to
»
@lyse Is it this one? https://github.com/rivo/tview It’s almost 10 years old but hasn’t seen a 1.0.0 release yet? 🤔
⤋ Read More
@lyse@lyse.isobeef.org Interesting approach. 🤔
The master branch should never be in a broken state (apart from bugs I don’t know about). Any intermediate state during the development of a larger feature will happen in a different branch.
I mean, yeah, but … I don’t know, I like having “traditional releases” as a second safety net when I write programs. I like to let things mature for a while and then I cut a new release. So it’s, like, “we have a bunch of new features and fixes here, and to the best of my knowledge this works fine now”. But maybe I’m just paranoid. 🤔
↳
In-reply-to
»
First draft of a file selection popup / widget:
⤋ Read More
@movq@www.uninformativ.de That is really cool! Maybe it would look nicer if the selected entry highlighted the whole row, not just the individual cells in that row without the column spacers. :-? But maybe I’m wrong. Everyone has their own taste.
And no, it’s not pointless at all. I find this really interesting. The videos and photos are perfect for me. Even if I had the source code, I would not use that toolkit, as I’m not a fan of movable windows in TUIs. I want all my own programs to be fullscreen all the time. 8-) Having said that, it’s still an absolutely brilliant source of inspriation that will come in handy one day. So, keep posting. :-)
↳
In-reply-to
»
@prologic Ahh, I see. Okay, I’m with you there. On this high level, I can understand how the thing works.
⤋ Read More
On the subject of debugging these so-called AI(s) / Black Boxes… the model is a black box sure, but that’s not really the problem. Everything around it — the inputs, the outputs, the decisions it makes — all of that can and should be fully logged, traced and replayed. The “program” isn’t the model, it’s the full context you feed it. That’s what you debug. It’s not so different from any other system really; if you’re running something in production with no logs, no structured outputs and no tests, you’d have the same problem. The model doesn’t change that discipline, it just makes it more important.
↳
In-reply-to
»
@movq I'm very curious...
⤋ Read More
@prologic@twtxt.net Ahh, I see. Okay, I’m with you there. On this high level, I can understand how the thing works.
Maybe my wording isn’t good. 🤔 Let’s take a real life example from what we do at work.
There’s this AI chatbot. It gets support requests from users, so the user says something like “I need access to a particular system”. This triggers the bot to “run” the instructions stored in a large Markdown file, like “check if the user is authorized to do this, then issue the following API requests”, and so on. This is essentially like running a little script, except it’s written in natural language (German) and there’s no “script interpreter” but just the AI.
Now, suppose that the AI doesn’t quite do what was intended. There’s some subtle bug. How do you debug this? How do you find out how the AI came to the “conclusion” to run step A instead of step B? And how do you find out how exactly you have to change your prompt so this doesn’t happen again next time?
If this was an actual script/program instead of AI, you could repeat the request and attach a debugger or throw in some printf() or whatever. How do you do that kind of thing with AI? How do you pinpoint exactly what the problem was?
(Or is this just a stupid idea? Do we have to give up that way of thinking when using AI? Is the era of debuggability over?)
↳
In-reply-to
»
@movq I'm very curious...
⤋ Read More
@movq@www.uninformativ.de I think your points are pretty clear to me, that’s fine. I’m just seeing if you can perhaps see things a different way maybe?🤔 I would challenge the assertion that you cannot understand how Claude Code generated an output; which I can demonstrate easily with a fairly trivial example by the input:
Write a program in Go that sums a list of numbers from stdin and prints the result.
↳
In-reply-to
»
@arne This is interesting. Sorry I missed this, I just found this post of yours and wanted to contribute 😅 Here's something interesting about me... I don't ever talk to myself, like ever. I have no, what they call, "inner monologue". Maybe I'm odd, but my wife asked me this very same question a while back and I said the same, there is never anything in my head except ideas, visuals or sounds, sometimes all at once, but never an inner monologue of "talking to myself".
⤋ Read More
@prologic@twtxt.net I don’t believe you. For example, you are programming something, and you are planning the steps, or you struggle at certain point. Any train of thought, of any kind, has an addressing. “If I move this here, what will it happen?”. “Hmm if we’re to place this logic here, will it do what we need?“. “If I were to do this, will it work?” “Damn it, you are so stupid, James, how could you miss that?!!” And so on. 😅 And that’s just a minor thing.
Trust me, you do. We all do. Even the crazy ones.
↳
In-reply-to
»
I’ve started collecting reasons against AI usage here, so I don’t have to repeat myself all the time:
⤋ Read More
Of course, @movq@www.uninformativ.de! Most of my points are also included in your list.
First of all, programming is what I really do enjoy the most. So, it doesn’t make any sense at all to not do this anymore. “But you could use your now free time to do something much cooler and more valuable!”, others might reply. Fuck no, I don’t want to waste my time with other shit that doesn’t fulfill me, why on earth would I want to do that?
All this hallucination reduces quality badly. In my experience, it’s also happening much more rapidly than I expected. Even though developers are still supposed to own and understand whatever has been generated under their name and even be responsible for that, the sad reality is that teammates often blindly trust the AI output. “But I asked the AI and it told me that $this was impossible”, “I’ve no idea either, but the AI just generated it” are responses I get more often. What really makes my angry is when I point out a flaw and suggest an alternative and this is the reaction. It happened several times that just trying it out and seeing it clearly work to proof my point only took me half a minute, but people still did something handwavy else instead.
The learning effect is drastically reduced. The more time I spend on a topic, the better the odds that whatever I learned actually makes it over into long-term memory. It’s like if a collegue just says “do it like that” or “this solves your problem”, but neither explains the why or how. Somehow, people are still convinced that it’s a completely different story when you replace the human counterpart with a computer program in this equation.
Skills are unlearned. It’s like with automation in general, just much worse. You end up in a state where you’ve no clue how anything works under the hood or how to actually find out important information that are needed to solve your problem. You’re screwed when a process breaks out of the blue. Even though it can become also rather terrible, with classical automation you’re typically still be able to decipher how exactly the thing was supposed to do something.
The energy consumption is sooo high, I absolutely do not want to be a part in burning down our planet. I’m sure I find (and probably have long found without knowing) other ways to contribute to worsen our climate crisis.
The scraper part is already covered in detail in your list. :-)
I’m convinced that license and copyright violations are only played down or even refused entirely because companies want to make big money quickly. With the work of others of course. Their double standards are obvious, they still try to actively keep their own stuff secret and out of any training sets. At most for internal use only. Virtually noone in charge is interested in good long-term solutions. Short-term for the win, when disaster eventually strikes, the causers are long gone, the responsibilities in other hands.
Vendor lock-in is something that lots of folks are only realizing very slowly. It’s completely crazy to me. This drug dealer routine should be well-known by now. It’s fucking everywhere. Yet, people are always surprised when they found themselves caught in it.
Adding new AI stuff only increases complexity. But complexity is the enemy that everybody should fear and reduce as much as possible. Of course, this is not limited to AI at all. And everywhere I look around, people in charge looooove to make things way more complicated than they ever need to be. Yet, simplicity is the real art and much harder to achieve.
I don’t understand why we have to go back full force to the ambiguity of natural languages. This alone should be more than enough to realize what a stupid idea all that is. Linked to that is that the “instruction set” is interpreted differently with newer model versions. I mean, is has to be. Why else would somebody want to upgrade in the first place than to get more Powerful™ Features™?
Some people argue that with AI the democratization is empowered. However, in my view, the exact opposite is the case. Models are getting so large that you can basically not run them locally or even train them. So, you have to rely on whatever the vendor offers you and runs for you. In the end, this only gives the owners more power, the multi billionaires. Not exactly what I understand by democratization.
Finally, technology assessments are missing completely. Or they are faked such that mostly only the (questionable) benefits are listed. But all the negative impact is just ignored.
Let’s keep some popcorn around for when this all explodes. :-)
Another AI rant:
One of the “key features” of LLMs is that you can use “natural language”, because that is supposed to be easier than having to learn a programming language. So, when someone says to me, “I automated this process using AI!”, what they mean is: They have written a very, very large Markdown document. In this document, they list what the AI is supposed to do.
In prose.
This is a complete disaster.
Programming and programming languages have one crucial property: They follow a well-defined structure and every word has a well-defined meaning. That is absolutely brilliant, because I can read this and I can follow the program in my head. I can build a mental model. I can debug this, down to the precise instructions that the CPU executes. This all follows well-defined patterns that you can reason about.
But with these Markdown files, I am completely lost. We lose all these important properties! No debugging, no reasoning about program flow, nothing. It’s all gone. It’s a magic black box now, literally randomized, that may or may not do what you wanted, in some order.
People now throw these Markdown files at me … and … am I supposed to read this? Why? It’s completely random and fuzzy.
Sadly, these AI tools are good enough to be able to mostly grasp the authors intentions. Hence people don’t see the harm they cause, because “it works”.
We already have a ton of automations like this at work: Tickets get piped through an LLM and these Markdown files / prompts determine what will happen with the ticket, and maybe they trigger additional actions as well, like account creation or granting permissions. All based on fuzzy natural language – that no two humans will ever properly agree on.
Jesus Christ, we’re now INTENTIONALLY bringing the ambiguity of legal texts and lawyers into programming.
Using natural language is NOT easier than using a programming language. It is HARDER. Have you people never read a legal contract? And that stuff can STILL be debated in a court room.
I can’t begin to comprehend why we, tech folks, push this so hard. What is wrong with you? Or me?
(And, once again, we’re ignoring other factors here. LLMs use a ton of energy and ressources, that we don’t have to spare. It’s expensive as fuck. It doesn’t even run locally on our servers, meaning we give all these credentials and permissions to some US company. It’s insane.)
↳
In-reply-to
»
Eehhh, what the hell is going on here!?
⤋ Read More
@lyse@lyse.isobeef.org AI result ahead, feel free to ignore.
I “asked” the AI at work the same question out of morbid curiousity. It “said” that SQLite converts that integer to floating point internally on overflows and then, when converting back, the x86 instruction cvttsd2si will turn it into 0x8000000000000000, even if the actual floating point value is outside of that range. So, yes, it allegedly actually saturates, as a side effect of the type conversion.
I couldn’t find anything about that automatic conversion in SQLite’s manual, yet, but an experiment looks like it might be true:
sqlite> select typeof(1 << 63);
╭─────────────────╮
│ typeof(1 << 63) │
╞═════════════════╡
│ integer │
╰─────────────────╯
sqlite> select typeof((1 << 63) - 1);
╭──────────────────────╮
│ typeof((1 << 63) ... │
╞══════════════════════╡
│ real │
╰──────────────────────╯
As for cvttsd2si, this source confirms the handling of 0x8000000000000000 on range errors: https://www.felixcloutier.com/x86/cvttsd2si
The following C program also confirms it (run through gdb to see cvttsd2si in action):
<a href="https://yarn.girlonthemoon.xyz/search?q=%23include">#include</a> <stdint.h>
<a href="https://yarn.girlonthemoon.xyz/search?q=%23include">#include</a> <stdio.h>
int
main()
{
int64_t i;
double d;
/* -3000 instead of -1, because `double` can’t represent a
* difference of -1 at this scale. */
d = -9223372036854775808.0 - 3000;
i = d;
printf("%lf, 0x%lx, %ld\n", d, i, i);
return 0;
}
(Remark about AI usage: Fine, I got an answer and maybe it’s even correct. But doing this completely ruined it for me. It would have been much more satisfying to figure this out myself. I actually suspected some floating point stuff going on here, but instead of verifying this myself I reached for the unethical tool and denied myself a little bit of fun at the weekend. Won’t do that again.)
↳
In-reply-to
»
My first pull request to Perl has been merged! https://github.com/Perl/perl5/commit/2aea97bf3f5c2ea62cf5e701858694b7378ed58c
⤋ Read More
@lyse@lyse.isobeef.org Oops, I guess the new text is a bit obscure. If you follow the link, the text is a bit more explicit, but you still need to know what a lexical scope is. Anyway, this is part of Perl moving very carefully toward being UTF-8 by default while also not breaking code written in the 90s. If you name a recent version like “use v5.42;” then Perl stops letting you use non-ASCII characters unless you also say “use utf8;”. The “lexically” part basically means that strictness continues until the next “}”, or the end of the program. That lets you fix up old code one block at a time, if you aren’t ready to apply the new strictness to a whole file at once.
thinking of Masyu. What a great game. Wondering about the perfect algorithm to generate a board of arbitrary size with only one solution. That’s almost more fun than playing the game #programming #masyu #puzzle #videogame
Fuck me dead! I accidentally confused an HTML file for a YAML file and manually opened it in my browser. Unfortunately, I clicked on the OK button of the popped up dialog a bit too fast, it just caught me off guard. It asked which program to open the YAML file in. Of course Firefox thought that it could handle that and suggested itself by default. Conveniently, the “don’t prompt me again and always use this selection from now on” checkbox was enabled.
And then the endless loop of death started. Turns out, this fucking browser can’t do shit with YAML files and delegated to what had been just configured. Oh, would you look at that!? Firefox! Empty tabs after empty tabs appeared. Killing and restarting Firefox just loaded the last session with all the tabs and the loop continued.
Some bloody snakeoil on my work machine slows down link openening requests by two, three seconds. It’s always absolutely anoying, but luckily, it actually limited the rate of new tabs popping up. I still could not close the many tabs fast enough that had accumulated before I noticed what was going on in the background.
Going to the settings to change them was always interrupted with a new tab opening in the foreground.
Finally, killing Firefox and renaming the file on disk before restarting Firefox did the trick and broke the loop. I was still holding down Ctrl+W for a minute or so to get rid of the useless tabs. I didn’t want to loose the important tabs, so just ditching the session wasn’t an option.
@movq@www.uninformativ.de Ah, great!
I have to analyze what is taking yt-dlp so long start up. Two and a half, three seconds just to determine that a video is in the download archive and then abort is nuts. I’m wondering what this program does before that.
Encouraging my kids to program as they draw: https://akkartik.name/post/2026-01-28-devlog
What a beautiful, beautiful 0°C Sunday arvo and evening! The weather forecast delayed the snow by the minute. An hour or so after it finally started very, very lightly, I headed off for the woods to check out the lake again. Unfortunately, with the fresh snow layer, the crazy wild surface texture of the ice sheet wasn’t visible anymore. But it brought some other nice views and photo opportunities.
I initially thought that I just go for a quick turn. However, with the snowfall a wee bit increasing I was hooked and kept going. Visibility was poor, but the snow blankets just looked too stunning. The road surfaces were quite slippery, so I often just walked alongside the pathways. On downhill slopes I had some good fun sliding down the road on my feet. With varying success. Luckily, I managed not to fall.
On the summit of the mountain the twigs had those absolutely magnificently looking windblown crystal coverings. Awwwwwww! They never get old. It was already getting dark, so the camera was tired and wanted to sleep. The snow program then made use of the flash and I’m quite pleased with how these shots turned out.
Two deer crossed the road in front of me and ran into the woods, that was sight for sore eyes. Although I felt bad that they had to flee from me in this white terrain. By the time I got home, the snow had accumulated around eight centimeters in height, even in town down in the valley. Walking on this fresh snow is just amazing. And I love the sound it makes. Today, the snow consistency must have been just right, because the crushing sound was really loud.
I cannot recall that I had frozen hair and beard before, but today, there was a thick ice buildup. In case I had, it was definitely never this much. Felt really cool.
Enough of this preliminary skirmishing, there ya go: https://lyse.isobeef.org/waldspaziergang-2026-01-25/
↳
In-reply-to
»
Btw @movq you've inspired me to try and have a good 'ol crack at writing a bootloader, stage1 and customer microkernel (µKernel) that will eventually load up a Mu (µ) program and run it! 🤣 I will teach Mu (µ) to have a
⤋ Read More
./bin/mu -B -o ... -p muos/amd64 ... target.
Whohoo! 🥳  You have no idea how great a feeling this is! This includes the Mu stdlib and runtime as well, not just some simple stupid program, this means a significant portion of the runtime and stdlib “just works”™ 🤣
You have no idea how great a feeling this is! This includes the Mu stdlib and runtime as well, not just some simple stupid program, this means a significant portion of the runtime and stdlib “just works”™ 🤣
Btw @movq@www.uninformativ.de you’ve inspired me to try and have a good ‘ol crack at writing a bootloader, stage1 and customer microkernel (µKernel) that will eventually load up a Mu (µ) program and run it! 🤣 I will teach Mu (µ) to have a ./bin/mu -B -o ... -p muos/amd64 ... target.
I’m trying to implement configurable key bindings in tt. Boy, is parsing the key names into tcell.EventKeys a horrible thing. This type consists of three information:
- maybe a predefined compound key sequence, like Ctrl+A
- maybe some modifiers, such as Shift, Ctrl, etc.
- maybe a rune if neither modifiers are present nor a predefined compound key exists
It’s hardcoded usage results in code like this:
func (t *TreeView[T]) InputHandler() func(event *tcell.EventKey, setFocus func(p tview.Primitive)) {
return t.WrapInputHandler(func(event *tcell.EventKey, setFocus func(p tview.Primitive)) {
switch event.Key() {
case tcell.KeyUp:
t.moveUp()
case tcell.KeyDown:
t.moveDown()
case tcell.KeyHome:
t.moveTop()
case tcell.KeyEnd:
t.moveBottom()
case tcell.KeyCtrlE:
t.moveScrollOffsetDown()
case tcell.KeyCtrlY:
t.moveScrollOffsetUp()
case tcell.KeyTab, tcell.KeyBacktab:
if t.finished != nil {
t.finished(event.Key())
}
case tcell.KeyRune:
if event.Modifiers() == tcell.ModNone {
switch event.Rune() {
case 'k':
t.moveUp()
case 'j':
t.moveDown()
case 'g':
t.moveTop()
case 'G':
t.moveBottom()
}
}
}
})
}
This data structure is just awful to handle and especially initialize in my opinion. Some compound tcell.Keys are mapped to human-readable names in tcell.KeyNames. However, these names always use - to join modifiers, e.g. resulting in Ctrl-A, whereas tcell.EventKey.Name() produces +-delimited strings, e.g. Ctrl+A. Gnaarf, why this asymmetry!? O_o
I just checked k9s and they’re extending tcell.KeyNames with their own tcell.Key definitions like crazy: https://github.com/derailed/k9s/blob/master/internal/ui/key.go Then, they convert an original tcell.EventKey to tcell.Key: https://github.com/derailed/k9s/blob/b53f3091ca2d9ab963913b0d5e59376aea3f3e51/internal/ui/app.go#L287 This must be used when actually handling keyboard input: https://github.com/derailed/k9s/blob/e55083ba271eed6fc4014674890f70c5ed6c70e0/internal/ui/tree.go#L101
This seems to be much nicer to use. However, I fear this will break eventually. And it’s more fragile in general, because it’s rather easy to forget the conversion or one can get confused whether a certain key at hand is now an original tcell.Key coming from the library or an “extended” one.
I will see if I can find some other programs that provide configurable tcell key bindings.
↳
In-reply-to
»
@lyse Ah, the lower right corner is different on purpose: It’s where you can click and drag to resize the window. https://movq.de/v/cbfc575ca6/vid-1767977198.mp4 Not sure how to make this easier to recognize. 🤔 (It’s the only corner where you can drag, btw.)
⤋ Read More
@lyse@lyse.isobeef.org It’s not super comfortable, that’s right.
But these mouse events come with a caveat anyway:
ncurses uses the XM terminfo entry to enable mouse events, but it looks like this entry does not enable motion events for most terminal emulators. Reporting motion events is supported by, say, XTerm, xiate, st, or urxvt, it just isn’t activated by XM. This makes all this dragging stuff useless.
For the moment, I edited the terminfo entry for my terminal to include motion events. That can’t be a proper solution. I’m not sure yet if I’m supposed to send the appropriate sequence manually …
And the terminfo entries for tmux or screen don’t include XM at all. tmux itself supports the mouse, but I’m not sure yet how to make it pass on the events to the programs running inside of it (maybe that’s just not supported).
To make things worse, on the Linux VT (outside of X11 or Wayland), the whole thing works differently: You have to use good old gpm to get mouse events (gpm has been around forever, I already used this on SuSE Linux). ncurses does support this, but this is a build flag and Arch Linux doesn’t set this flag. So, at the moment, I’m running a custom build of ncurses as a quick hack. 😅 And this doesn’t report motion events either! Just clicks. (I don’t know if gpm itself can report motion events, I never used the library directly.)
tl;dr: The whole thing will probably be “keyboard first” and then the mouse stuff is a gimmick on top. As much as I’d like to, this isn’t going to be like TUI applications on DOS. I’ll use “Windows” for popups or a multi-window view (with the “WindowManager” being a tiny little tiling WM).
Vacation: Doing crazy things like C on DOS, lots of Rust, bare-metal assembly code, everything is fine.
Back at work: How the fuck do I move an email in this web mail program? Am I stupid? 😮💨
↳
In-reply-to
»
I came across this on "Why Is SQLite Coded In C", which I found interesting:
⤋ Read More
@bender@twtxt.net They’re not completely impossible, but C makes it much easier to run into them. I think the key point is that in those “safe” languages, buffer overflows are caught and immediately crash the program (if not handled otherwise) instead of silently corrupting memory, not being noticed right away and maybe only later crashing at a different location, where it can be very hard to find the actual root cause. This is a big improvement in my book.
Some programmers are indeed horrible. I’m guilty myself. :-)
I like the article.
I came across this on “Why Is SQLite Coded In C”, which I found interesting:
“There has lately been a lot of interest in “safe” programming languages like Rust or Go in which it is impossible, or is at least difficult, to make common programming errors like memory leaks or array overruns.”
If that’s true, then encountering those issues means the programmer is, simply, horrible?
↳
In-reply-to
»
I think this is finally a good metaphor to talk about “simple” software:
⤋ Read More
@movq@www.uninformativ.de I quite like this part:
Many people write programs, but few stick with a program long enough to distill it.
I think this is finally a good metaphor to talk about “simple” software:
https://oldbytes.space/@psf/115846939202097661
Distilled software.
I quote in full:
principles of software distillation:
Old software is usually small and new software is usually large. A distilled program can be old or new, but is always small, and is powerful by its choice of ideas, not its implementation size.
A distilled program has the conciseness of an initial version and the refinement of a final version.
A distilled program is a finished work, but remains hackable due to its small size, allowing it to serve as the starting point for new works.
Many people write programs, but few stick with a program long enough to distill it.
I often tried to tell people about “simple” or “minimalistic” software, “KISS”, stuff like that, but they never understand – because everybody has a different idea of “simple”. The term “simple” is too abstract.
This is worth thinking about some more. 🤔
↳
In-reply-to
»
More widget system progress:
⤋ Read More
And now the event loop is not a simple loop around curses’ getch() anymore but it can wait for events on any file descriptor. Here’s a simple test program that waits for connections on a TCP socket, accepts it, reads a line, sends back a line:
https://movq.de/v/93fa46a030/vid-1767547942.mp4
And the scrollbar indicators are working now.
I’ll probably implement timer callbacks using timerfd (even though that’s Linux-only). 🤔
More widget system progress:
https://movq.de/v/87e2bce376/vid-1767467193.mp4
I like the oldschool shadow effect. 😅 Not sure if I’ll keep it, but it’s neat.
The menu bar is still fake.
Had to spend quite a bit of time optimizing the rendering today. This can get really slow really quickly.
Unicode is Pain.
I might be able to start porting my first program (currently uses urwid) soon. 🤔
Nice! 😊 Here are the startup latencies for the simplest Mu (µ) program. println("Hello World"):
- Interpreter: ~5ms
- Native Code: ~1.5ms
↳
In-reply-to
»
@movq That's cool! I also like the name of your library. :-) I assume you made the thing load quickly, didn't you?
⤋ Read More
@movq@www.uninformativ.de Yeah, I see. Just crudely checked on my computer, with around 0.013 seconds, Python 2.7 seems a tad faster than Python 3.14’s 0.023 seconds in this little program.
The lazy imports sound not too bad, but I just skimmed over them. There are surprisingly many exceptions, but yeah, no way around them. :-)
mu (µ) now has builtin code formatting and linting tools, making µ far more useful and useable as a general purpose programming language. Mu now includes:
- An interpreter for quick “scriptinog”
- A native code compiler for building native executables (Darwin / macOS only for now)
- A builtin set of developer tools, currently: fmt (-fmt), check (-check) and test (-test).
↳
In-reply-to
»
@movq That's cool! I also like the name of your library. :-) I assume you made the thing load quickly, didn't you?
⤋ Read More
I assume you made the thing load quickly, didn’t you?
That’s the problem with Python. If you have a couple of files to import, it will take time.
I want this to be reasonably fast on my old Intel NUC from 2016 (Celeron N3050 @ 1.60GHz) and I already notice that the program startup takes about 95 ms (or 125 ms when there are no .pyc files yet). That’s still fine, but it shows that I’ll have to be careful and keep this thing very small …
Python 3.14 will bring lazy imports, maybe that can help in some cases.
Well, you girls and guys are making cool things, and I have some progress to show as well. 😅
https://movq.de/v/c0408a80b1/movwin.mp4
Scrolling widgets appears to work now. This is (mostly) Unicode-aware: Note how emojis like “😅” are double-width “characters” and the widget system knows this. It doesn’t try to place a “😅” in a location where there’s only one cell available.
Same goes for that weird “ä” thingie, which is actually “a” followed by U+0308 (a combining diacritic). Python itself thinks of this as two “characters”, but they only occupy one cell on the screen. (Assuming your terminal supports this …)
This library does the heavy Unicode lifting: https://github.com/jquast/wcwidth (Take a look at its implementation to learn how horrible Unicode and human languages are.)
The program itself looks like this, it’s a proper widget hierarchy:
https://movq.de/v/1d155106e2/s.png
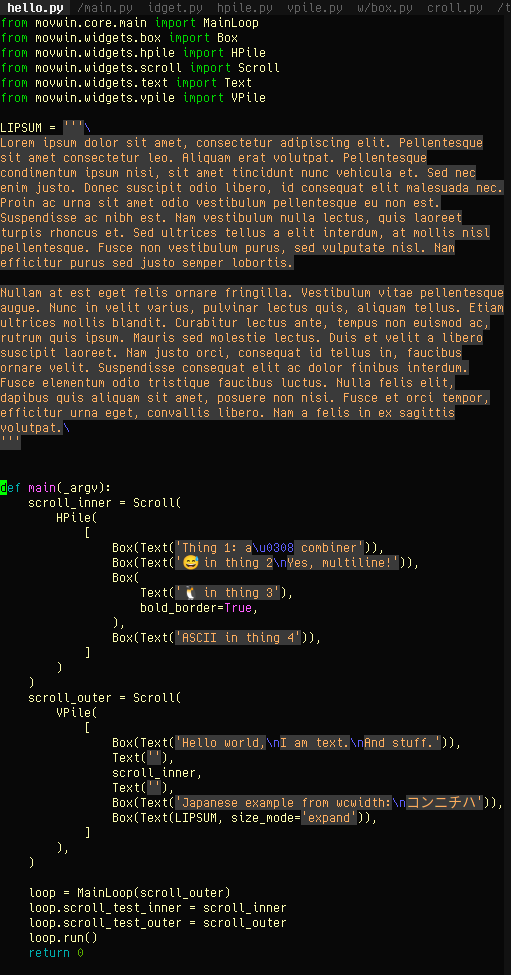{kind=link}
(There is no input handling yet, hence some things are hardwired for the moment.)
↳
In-reply-to
»
Trying to come up with a name for a new project and every name is already taken. 🤣 The internet is full!
⤋ Read More
@lyse@lyse.isobeef.org I’m toying with the idea of making a widget/window system on top of Python’s ncurses. I’ve never really been happy with the existing ones (like urwid, textual, pytermgui, …). I mean, they’re not horrible, it’s mostly the performance that’s bugging me – I don’t want to wait an entire second for a terminal program to start up.
Not sure if I’ll actually see it through, though. Unicode makes this kind of thing extremely hard. 🫤
↳
In-reply-to
»
Hmmm I need to figure out a way to reduce the no. of lines of code / complexity of the ARM64 native code emitter for mu (µ). It's insane really, it's a whopping ~6k SLOC, the next biggest source file is the compiler at only ~800 SLOC 🤔
⤋ Read More
The compiler technique I’m using here is to not “emit” most of the runtime if it’s actually never used in your program, and also dropping dead code in the SSA pass.
↳
In-reply-to
»
My little toy operating system from last year runs in 16-bit Real Mode (like DOS). Since I’ve recently figured out how to switch to 64-bit Long Mode right after BIOS boot, I now have a little program that performs this switch on my toy OS. It will load and run any x86-64 program, assuming it’s freestanding, a flat binary, and small enough (< 128 KiB code, only uses the first 2 MiB of memory).
⤋ Read More
@prologic@twtxt.net That might be a challenge, at least in 16-bit Real Mode: The OS follows the model of COM files on DOS, i.e. the size of the binary cannot exceed 64 KiB and heap+stack of the running program will have to fit into that same 64 KiB. 😅 (The memory layout is very rigid, each process gets such a 64 KiB slice.)
And in 64-bit Long Mode, there is no “kernel” yet. The thing in the video is literally just a small bare-metal program.
But some day, maybe. 😃
My little toy operating system from last year runs in 16-bit Real Mode (like DOS). Since I’ve recently figured out how to switch to 64-bit Long Mode right after BIOS boot, I now have a little program that performs this switch on my toy OS. It will load and run any x86-64 program, assuming it’s freestanding, a flat binary, and small enough (< 128 KiB code, only uses the first 2 MiB of memory).
Here I’m running a little C program (compiled using normal GCC, no Watcom trickery):
https://movq.de/v/b27ced6dcb/los86%2D64.mp4
https://movq.de/v/b27ced6dcb/c.png
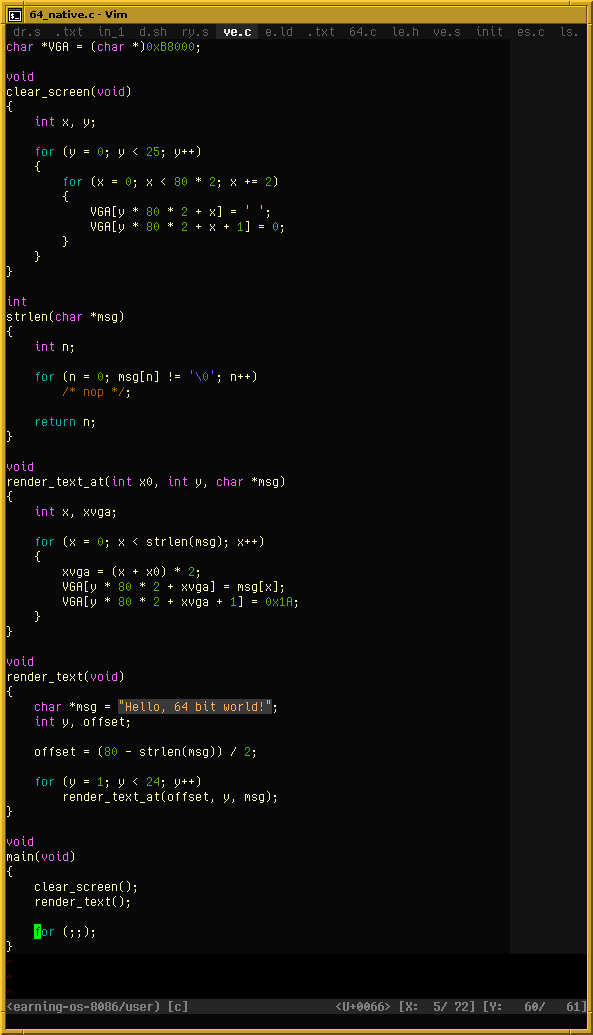{kind=link}
Next steps could include:
- Use Rust instead of C for that 64-bit program?
- Provide interrupt service routines. (At the moment, it just keeps interrupts disabled.)
↳
In-reply-to
»
@movq wow! what is assembler?
⤋ Read More
@kiwu@twtxt.net Assembly is usually the most low-level programming language that you can get. Typical programming languages like Python or Go are a thick layer of abstraction over what the CPU actually does, but with Assembler you get to see it all and you get full control. (With lots of caveats and footnotes. 😅)
I’m interested in the boot process, i.e. what exactly happens when you turn on your computer. In that area, using Assembler is a must, because you really need that fine-grained control here.
I’m seeing crashes in the 3D subsystem. (Gallium? Glamor? Whatever other Mesa thing they have? No idea.) In the logs I find this:
malloc(): unaligned tcache chunk detected
And that’s why I still care about Rust and want to learn more about it, even though it’s giving me so much headache and I’ve given up so many times. Because Rust currently seems to be the only popular systems programming language that tries to eliminate these error classes.
And of course “the Rust experiment” in the Linux kernel has recently been concluded as “successful”, so that alone is reason enough for me:
I just completed “Secret Entrance” - Day 1 - Advent of Code 2025 #AdventOfCode https://adventofcode.com/2025/day/1 — However I did it in my own toy programming language called mu, which I had to build first 🤣
↳
In-reply-to
»
Come back from my trip, run my AoC 2025 Day 1 solution in my own language (mu) and find it didn't run correctly 🤣 Ooops!
⤋ Read More
Ahh that’s because I forgot to call main() at the end of the source file. mu is a bit of a dynamic programming language, mix of Go(ish) and Python(ish).
$ ./bin/mu examples/aoc2025/day1.mu
Execution failed: undefined variable readline
↳
In-reply-to
»
Use more WebP, I guess.
⤋ Read More
Searching the web a bit brings up lots of threads where people hate WebP. The problem being that browsers support WebP but other programs tend to be problematic … ? 🤔
I love this quote. “Dependencies are a lot like sexual partners, and it seems most (all?) programming languages are trying to make it easy to be as promiscuous as possible via internal package managers.” gemini://bbs.geminispace.org/s/Reticulum/35090
↳
In-reply-to
»
@movq Oh damn ! I'm on holidays in Ciwtnam 🤣 I'll be late to the party !
⤋ Read More
@prologic@twtxt.net Nothing stops you from programming while in Vietnam. 😏😈😅
↳
In-reply-to
»
There are no really good GUI toolkits for Linux, are there?
⤋ Read More
FTR, I see one (two) issues with PyQt6, sadly:
- The PyQt6 docs appear to be mostly auto-generated from the C++ docs. And they contain many errors or broken examples (due to the auto-conversion). I found this relatively unpleasent to work with.
- (Until Python finally gets rid of the Global Interpreter Lock properly, it’s not really suited for GUI programs anyway – in my opinion. You can’t offload anything to a second thread, because the whole program is still single-threaded. This would have made my fractal rendering program impossible, for example.)
↳
In-reply-to
»
There are no really good GUI toolkits for Linux, are there?
⤋ Read More
@prologic@twtxt.net Hm, same startup delay. (Go is not an option for me anyway.)
It’s hard to tell why all this is so slow. Maybe in this particular case it has something to do with fonts: strace shows the program loading the fontconfig configs several times, and that takes up a bulk of the startup time. 🤔 (Qt6 or Java don’t do that, but they’re still slow to start up – for other reasons, apparently.)
To be fair, it’s “just” the initial program startup (with warm I/O caches). Once it’s running, it’s fine. All toolkits I’ve tried are. But I don’t want to accept such delays, not in the year 2025. 😅 Imagine every terminal window needing half a second to appear on the screen … nah, man.
↳
In-reply-to
»
There are no really good GUI toolkits for Linux, are there?
⤋ Read More
Be it Java with Swing or PyQt6, it takes ~300 ms until a basic window with a treeview and a listbox appears. That is a very noticeable delay.
Is it unrealistic to expect faster startup times these days? 🤔
Once the program is running, a new second window (in the same process) appears very quickly. So it’s all just the initialization stuff that takes so long. I could, of course, do what “fat” programs have done for ages: Pre-launch the process during boot, windowless. But I was hoping that this wasn’t needed. 😞 (And it’s a bad model anyway. When the main process crashes, all windows crash with it.)