Windows NT 4 didn’t have a Device Manager. You know, this thing right here that got introduced with Windows 95:
https://movq.de/v/1b8e044aaa/s.png
{kind=link}
And that’s super awkward in NT4.
You know what doesn’t have a Device Manager, either? Linux. Why? 🤔 Isn’t this one of the most useful system tools? It gives you an overview of the devices in your system and tells you which driver is used for them. Linux could really use such a tool, I think? 🤔
(There are programs like “hardinfo” and I remember ancient KDE providing such a tool, but they’re all an afterthought. Hardly integrated into the overall system.)
Movies and TV are moving in this direction too, but at least for now, I can still access a lot of movies and shows on discs (especially from my local library). I can also make backups of my shows and movies if I have the discs available. As time goes on, new tools become available to preserve physical games. Physical games at least gives the chance of future preservation in a world where digital is locked behind DRM- assuming the full game is on the disc.
Movies and TV are moving in this direction too, but at least for now, I can still access a lot of movies and shows on discs (especially from my local library). I can also make backups of my shows and movies if I have the discs available. As time goes on, new tools become available to preserve physical games. Physical games at least gives the chance of future preservation in a world where digital is locked behind DRM- assuming the full game is on the disc.
This is a neat tool for comparing several public DNS resolvers (some of which were new to me) on various criteria; includes a speed test. https://evilbit.de/dns-resolver-guide.html
So I’ve been working on GoNIX the last few days… Which is derived from µLinux – At least it’s entire build process. GoNIX however has a 100% Go userland, including the init process, package and service management.
Now… As an experiment, because I was able to make much process on enhancing the build tools and package management, I decided to see if I could build a “Desktop” Gui of sorts…
I still wanted it to be fairly minimal and lightweight. So I went with wayland (of course) and labwc and yambar. So far I’m liking the result 👌 42 packages in the wayland-desktop meta port. Not too bad. Not sure if I can slim that down anymore… But trying to avoid Mesa/GL as that drags in far too much “cruft”.
↳
In-reply-to
»
@lyse Ah, you mean the categorization. Yeah, that would never work in Windows, at least not without having a centralized package manager (so there’s one authoritative source of which program belongs into which category).
⤋ Read More
@movq@www.uninformativ.de That’s right, way harder than centrally managed. They even didn’t reach concensus over the main folder: “Alle Programme, “Alle Programme (x86)”, “All Programs”, “All Programmes”, etc. Anyway.
For class 11 (or maybe already in 10, I don’t remember exactly) we could choose either between traditional maths class with a graphical calculator or “Mathe mit CAS”. There were two teachers in my entire school who were able to teach the latter. It was also fairly new at the time I believe. Certainly unheard of for a „allgemeinbildendes Gymnasium“, maybe the technical ones were already offering it for some time, not sure. It was clear to me that I would take the maths with CAS class.
Each kid had to buy their own Cassiopeia A-Something. I don’t know how much that thing was (definitely more expensive than a graphical calculator) and whether the school subsidized that in any form. But it was slow and underpowered as hell. We rarely used it in class nor for homework (most if not all had already a desktop at home). Typically, when we worked with the CAS, we sat down on the desktop computers. Our class took place in one of the two computer rooms. The desktops were placed on the three sides (left, right, back, facing the walls or windows) and the regular school desks were in the middle. Since there were more pupils than desktops, we always shared. Nowadays, we call it pair programming. ;-)
For the exams we had the “mandatory part” (Pflichtteil) without any tools. Once we finished that and handed the papers to our teacher, we were then allowed to boot up our Cassiopeias and work with them for the second part. Before the exam started, everyone had to show the teacher that they reset their small computer to factory settings. This second part was called „Wahlteil“. But you had to do it in order to pass. So, I never understood the choice of this term. Maybe it’s because the first part is the exact same for everyone (graphical calculator and CAS class), but the second part was definitely different for the two classes. Each suited to their tools.
After one or two exams, it became clear that the Cassiopeia was far from ideal. So, we took the second part at the desktop computers from then on. Our teacher unplugged the network cables himself to avoid cheating. Each computer had an “HDD Sheriff” running that reset the disk at startup. There was also an issue that the personal user accounts were affected by that. Sometimes all your data were lost. If you were lucky, they were still there. So, we saved our Maple project to local disk (if the computer didn’t crash in between, that was no problem) and at least eventually before leaving the classroom, we then also saved it on the server. For that, the teacher quickly plugged in the cable, we saved, and then the cable was unplugged again immediately. Oh, and everybody used their USB sticks, too.
All in all, this Cassiopeia A-* was quite a useless purchase. :-D I’m not sure if I still have it. At least I thought several times about giving it to the flea market. Don’t know if I did or not.
Every now and then, I think that I have carefully proof-read my message enough times and hit the “Add message” button in tt. But then, in the message tree, I spot another missed typo. My process is then to go to my twtxt.txt and fix it by hand. However, I still have to clean up tt’s cache. This is rather tidious:
- Recall the
sqlitebrowser ~/.local/share/twtxt/tt2.sqlitefrom my shell history.
- Switch to the “Browse data” tab.
- Go to the
messagestable and wait a second or two until it’s loaded.
- Sort by the
created_atcolumn twice, so that I get descending order.
- Select the first message, which is typically the one in question.
- Find the “Remove currently selected row” button in the tool bar.
- Commit the changes.
- Close sqlitebrowser.
So, I finally implemented the removal of messages from the cache in tt. I can now hit d and confirm the removal. Bam! Should have done that ages ago!
https://lyse.isobeef.org/tmp/tt-confirm-message-removal.png
{kind=link}
Next up is the search, I think.
The concept of synthesis is more useful than artificiality in connection with generative media tools. Synthetic fabrics have been used in the garment industry for decades, while nobody complains anymore that synthesized music is inferior to music played on acoustic instruments. So why are synthetic artworks of all kinds routinely dismissed as inferior to human-produced art?
↳
In-reply-to
»
@movq Related reading (if you're interested): Let's Talk about LLMs by James Bennett
⤋ Read More
@itsericwoodward@itsericwoodward.com That DORA quote is 🤯 — and it perfectly explains why AI coding tools terrify me in certain contexts. Dropping Copilot into a codebase full of technical debt isn’t gonna fix the debt, it’s just gonna write more of it faster 🤣 Fred Brooks would be nodding his head right now 🙏
↳
In-reply-to
»
@movq Related reading (if you're interested): Let's Talk about LLMs by James Bennett
⤋ Read More
(#xbh2sbq) @itsericwoodward@itsericwoodward.com That DORA quote is 🤯 — and it perfectly explains why AI coding tools terrify me in certain contexts. Dropping Copilot into a codebase full of technical debt isn’t gonna fix the debt, it’s just gonna write more of it faster 🤣 Fred Brooks would be nodding his head right now 🙏
↳
In-reply-to
»
Apologies to anyone who's seen an uptick in twtxt pings from me today... I've been working on shoe-horning my twtxt reader (TwtStrm) into my editor (TwtKpr, aka the
⤋ Read More
express-twtkpr npm library), and it kind ran amok a few times. So again, sorry - I've added a minimum 10-minute cool-down period between pulls which should help (I hope 🙂).
@itsericwoodward@itsericwoodward.com Excited to see twtxt tooling in the Node ecosystem! Any plans to implement the Twtxt v2 extensions? Things like Twt Hash + Subject (proper threading), Multiline, etc. — all documented at https://twtxt.dev 👀
↳
In-reply-to
»
@movq I'm very curious...
⤋ Read More
It’s one of the reasons in fact I’ve been working on bob so I have a very concrete and strong foundation for how these things work, how they behave and how bad or good they can be. I am on-purpose building bob to be not only a decent coding tool and general task completion tool, but with serious security boundaries, sanitation, auditing and compliance. If I’m going to succeed at building autoonmous agents that can cope with a wider array of varying inputs (mostly natural language, some structural language) then it needs to be both a) Safe and b) Robust
↳
In-reply-to
»
@lyse Thanks! There are a few points in there that I’ll add to my list.
⤋ Read More
@bender@twtxt.net Now that’s an interesting philosophical viewpoint right there. But this assumes that the “AI” we seemingly have available to us today is actually telligent, understands and has cognitive reasoning. It does not. All of these LLM models from big-tech companies like Anthropic, OpenAI, Google, Microsoft, Meta and Alibaba are all just very powerful, very large multidimensional neural networks with attention that are very good at statistical probabilities of ‘what comes next”. I think we get really upset over the wrong things sometimes. We need to continue to be upset that these 🤬 companies have basically destroyed any meaningful value of the concept of Copyright and Intellectual Property and Works of art. The so-called “AI” we have today is just a tool. Can you say for certain that the typewriter and the computer ruined our ability to write? Perhaps yes, but we still learn how to do so, likewise, I still think that learning to write code, research, read and write are all valuable skills to learn. Later on once you have the basics, you can defer some of the “tedious” work to these models, because frankly, they’re far better at inferencing and pattern matching than you or i will ever be, not because they’re better at pattern-matching per se, but because they have been trained on a very large corpus and they are much much faster at doing the same basic things we are far superior at.
↳
In-reply-to
»
@lyse These days (and it’s been like that for a while), almost everything is loaded on-demand depending on which hardware the OS finds, so you can simply copy all your files with
⤋ Read More
cp -a, install a bootloader, adjust some minor things /etc/fstab, done. Well, maybe not “done”, but it’s easy to sort out the remaining stuff afterwards.
@bender@twtxt.net It’s been a while (6.5 years) since I’ve done this. I’d do it like this:
- Boot some Linux from a USB stick on the new machine. Preferably Arch Linux, since that is what I’m running and that’ll make the upcoming chroot easier.
- Partition the new disk, create LUKS devices, filesystems, …
- Mount the new filesystems and copy all data (user data and the system itself – everything). Do this either over the network or by hooking up the old disk directly.
- chroot into the new system (Arch has an
arch-chroottool for that which is used during normal installation, if I’m not mistaken). Inside the chroot, install the bootloader.
- Do some fixups, like adjusting
/etc/fstabor/etc/crypttab.
And I think that should be it. 🤔
↳
In-reply-to
»
They are all very nice @lyse! You truly need some sort of easy to navigate website with them all, categorised, and such… A robot can dream, right? :-)
⤋ Read More
¡Muchas gracias @bender@twtxt.net! I was also thinking about categorizing them a few years ago. But it’s so much work. I would have to tag every photo on its own. My use case goes more towards “give me all albums with squirrels”, though. Let’s see. I would need some tooling for easy tagging first. And then, the question is, which categories do I want to have to begin with?
Another AI rant:
One of the “key features” of LLMs is that you can use “natural language”, because that is supposed to be easier than having to learn a programming language. So, when someone says to me, “I automated this process using AI!”, what they mean is: They have written a very, very large Markdown document. In this document, they list what the AI is supposed to do.
In prose.
This is a complete disaster.
Programming and programming languages have one crucial property: They follow a well-defined structure and every word has a well-defined meaning. That is absolutely brilliant, because I can read this and I can follow the program in my head. I can build a mental model. I can debug this, down to the precise instructions that the CPU executes. This all follows well-defined patterns that you can reason about.
But with these Markdown files, I am completely lost. We lose all these important properties! No debugging, no reasoning about program flow, nothing. It’s all gone. It’s a magic black box now, literally randomized, that may or may not do what you wanted, in some order.
People now throw these Markdown files at me … and … am I supposed to read this? Why? It’s completely random and fuzzy.
Sadly, these AI tools are good enough to be able to mostly grasp the authors intentions. Hence people don’t see the harm they cause, because “it works”.
We already have a ton of automations like this at work: Tickets get piped through an LLM and these Markdown files / prompts determine what will happen with the ticket, and maybe they trigger additional actions as well, like account creation or granting permissions. All based on fuzzy natural language – that no two humans will ever properly agree on.
Jesus Christ, we’re now INTENTIONALLY bringing the ambiguity of legal texts and lawyers into programming.
Using natural language is NOT easier than using a programming language. It is HARDER. Have you people never read a legal contract? And that stuff can STILL be debated in a court room.
I can’t begin to comprehend why we, tech folks, push this so hard. What is wrong with you? Or me?
(And, once again, we’re ignoring other factors here. LLMs use a ton of energy and ressources, that we don’t have to spare. It’s expensive as fuck. It doesn’t even run locally on our servers, meaning we give all these credentials and permissions to some US company. It’s insane.)
↳
In-reply-to
»
@lyse
⤋ Read More
@lyse@lyse.isobeef.org Clearing legally? You must have an amazingly efficient legal team – there’s like 10 new tools every week. 🤣
↳
In-reply-to
»
@lyse
⤋ Read More
@movq@www.uninformativ.de No, just the damn training. For the tools, they always want the latest shit available. The company isn’t quick enough in purchasing and legally clearing the latest models, services, etc., they say. Other than that, they seem to be happy.
↳
In-reply-to
»
@lyse Yes, and that’s why I’m 100% convinced that we’ll see a massive brain drain in a couple of years. This will affect young people even more, because they don’t have all the “old” knowledge to fall back on.
⤋ Read More
even our hippest AI enthusiasts found it absolutely terrible
Does this refer to the training course or to the tools themselves? 🤔
↳
In-reply-to
»
Eehhh, what the hell is going on here!?
⤋ Read More
@lyse@lyse.isobeef.org Yes, and that’s why I’m 100% convinced that we’ll see a massive brain drain in a couple of years. This will affect young people even more, because they don’t have all the “old” knowledge to fall back on.
It’s concerning, I’ve warned about it many times, nobody listens.
I think the best thing one can do is explicitly not use any AI tools but keep your actual skills intact. Might be out of a (good) job for a while, but once this bubble bursts, this is who is going to get hired again. (I think.)
And considering how insanely expensive all this is, I’m still (mostly) convinced that the bubble will actually burst. This stuff just isn’t sustainable.
… or I might be wrong. And if so, I see an even darker future that I don’t want to put into words right now.
↳
In-reply-to
»
Eehhh, what the hell is going on here!?
⤋ Read More
@lyse@lyse.isobeef.org AI result ahead, feel free to ignore.
I “asked” the AI at work the same question out of morbid curiousity. It “said” that SQLite converts that integer to floating point internally on overflows and then, when converting back, the x86 instruction cvttsd2si will turn it into 0x8000000000000000, even if the actual floating point value is outside of that range. So, yes, it allegedly actually saturates, as a side effect of the type conversion.
I couldn’t find anything about that automatic conversion in SQLite’s manual, yet, but an experiment looks like it might be true:
sqlite> select typeof(1 << 63);
╭─────────────────╮
│ typeof(1 << 63) │
╞═════════════════╡
│ integer │
╰─────────────────╯
sqlite> select typeof((1 << 63) - 1);
╭──────────────────────╮
│ typeof((1 << 63) ... │
╞══════════════════════╡
│ real │
╰──────────────────────╯
As for cvttsd2si, this source confirms the handling of 0x8000000000000000 on range errors: https://www.felixcloutier.com/x86/cvttsd2si
The following C program also confirms it (run through gdb to see cvttsd2si in action):
<a href="https://yarn.girlonthemoon.xyz/search?q=%23include">#include</a> <stdint.h>
<a href="https://yarn.girlonthemoon.xyz/search?q=%23include">#include</a> <stdio.h>
int
main()
{
int64_t i;
double d;
/* -3000 instead of -1, because `double` can’t represent a
* difference of -1 at this scale. */
d = -9223372036854775808.0 - 3000;
i = d;
printf("%lf, 0x%lx, %ld\n", d, i, i);
return 0;
}
(Remark about AI usage: Fine, I got an answer and maybe it’s even correct. But doing this completely ruined it for me. It would have been much more satisfying to figure this out myself. I actually suspected some floating point stuff going on here, but instead of verifying this myself I reached for the unethical tool and denied myself a little bit of fun at the weekend. Won’t do that again.)
Heyy 04866, regarding grub, you should have checked your grub config file before installing it, never rely on distro’s tools. See if your grub config matches your intention and install it, if not, tweak it until it’s fine.
You should study your tools if you’re planning to FAFO with them. Now use a live USB and see if the grub files are missing something, or just learn how grub works.
Just learned this nice little life-hack
for disconnecting MC4 Solar connectors 👌 Works really well! And I don’t have to buy a special little MC4 assembly tool 🥳
@lyse@lyse.isobeef.org A-ha! That means you haven’t spent enough time with these tools! Go on, try it! (If you don’t, we’ll fire you.) I’m sure you’ll like it!
{kind=link}
↳
In-reply-to
»
Can anyone recommend a command-line SQL query formatter? Unfortunately,
⤋ Read More
sqlparse is also unsuitable for me: https://github.com/andialbrecht/sqlparse/issues/688
I’m supporting incremental SQLite schema changes to just upgrade from an older database version to whatever the current software version supports. In the past, I already noticed that this is quite expensive in unit tests when each test case runs through the entire schema patches and applies them one by one.
To speed up test execution I now decided that I finally go through the troubles of maintaining both a set of incremental patches and a full schema setup in one go. A unit test verifies that both ways end up with the same structure. This gives me a set of SQLs to check the structures:
SELECT type, name, tbl_name, sql
FROM sqlite_schema
ORDER BY type, name, tbl_name
Unfortunately, the resulting CREATE TABLE SQL queries are formatted differently, depending on whether the full schema was set up in one big step or the structure had been modified with ALTER TABLE. Mainly, added columns are not on their own lines but appended in one physical line. That’s why I wanted an SQL formatting tool. Since I didn’t find one that works decently, I’m now doing some simple string manipulation. Joining consecutive whitespace into a single space character, removing spaces before commas and closing parentheses and spaces after opening parentheses. This works surpringly good enough. Of course, if it fails, the “diff” is absolutely horrendous.
Now for the cool part, my test execution dropped from around 5:05 minutes to just 1:32 minutes! I call that a win.
I just stumbled across PRAGMA table_info('tablename') https://sqlite.org/pragma.html#pragma_table_info, PRAGMA foreign_key_list('tablename') and friends. I guess, I have to play with that, now. It’s probably much better to use than the SQL text approach.
↳
In-reply-to
»
@kiwu Sorry, I have two functional brain cells left in my brain, and I'm not sure if you're asking What am I putting in it, as in a) when making some? Or as in b) when consuming/serving it?
⤋ Read More
@rdlmda@rdlmda.me it is called, in Spanish, “the mother”. It is created through a bit (not by much) effort, and kept as a starting point. Just like Asian cuisine has dishes that never cool, always cooking leaving always a base on it.
How do you think a lathe (and just about any tool, etc.) is done? Yup, in part by using a lathe. 😅
@movq@www.uninformativ.de I know it’s crazy right 🤯 these things are just tools. They’re not even remotely intelligent at all. In fact they are actually quite stupid. If you feed it garbage you get garbage out! The only interesting thing is that you get somewhat intelligible garbage out 😂
HEY! I think we all noticed that privacy is dying. Government and corporate entities around the world are building the laws and tools to track you, from everything you write, to the media you consume, to where you drive your car and the people you associate with. Gopher I believe Is one of the last bastions of freedom away from what I call “Corpo web”. GopherSpace is free, I wrote my client so I know it’s safe, and I can route my traffic over tor or any proxy of my choosing. I think we should use gopher as a means to communicate and get out of the modern corpo web because soon everything you do and say on the modern web or possibly corporate owned devices is under scrutiny, even more so than it ALREADY IS. Right now I can use tor and my custom gopher cli to communicate privately here. With the ways the laws are going they are going to implement things like age verification to track you and they’ll deem privacy focused open source software as tools for circumventing these rules. It’s a slippery slope. I need to stop writing before I sound really crazy.
does magical.fish’s admin still come around here or not? it seems that the stock prices tool is broken
The modern world seems to want to separate the concepts of beauty and utility. We’re fine with having things that are aesthetic but don’ do anything useful, while the tools of society that get work done are often very ugly–visually, socially and metaphorically. Beauty without utility is worthless; utility without beauty is meaningless. We can’t treat them independently.
↳
In-reply-to
»
@lyse
⤋ Read More
@movq@www.uninformativ.de Sorry, I meant the builtin module:
$ python3 -m pep8 file.py
/usr/lib/python3/dist-packages/pep8.py:2123: UserWarning:
pep8 has been renamed to pycodestyle (GitHub issue #466)
Use of the pep8 tool will be removed in a future release.
Please install and use `pycodestyle` instead.
$ pip install pycodestyle
$ pycodestyle ...
I can’t seem to remember the name pycodestyle for the life of me. Maybe that’s why I almost never use it.
Since I used so much Rust during the holidays, I got totally used to rustfmt. I now use similar tools for Python (black and isort).
What have I been doing all these years?! I never want to format code manually again. 🤣😅
mu (µ) now has builtin code formatting and linting tools, making µ far more useful and useable as a general purpose programming language. Mu now includes:
- An interpreter for quick “scriptinog”
- A native code compiler for building native executables (Darwin / macOS only for now)
- A builtin set of developer tools, currently: fmt (-fmt), check (-check) and test (-test).
↳
In-reply-to
»
@lyse Yeah I remember you said some days back that your interest in compilers was rekindled by my work on mu (µ) 😅
⤋ Read More
@lyse@lyse.isobeef.org I can tell you this right now, writing assembly / machine code is fucking hard work™ 😓 I’m sure @movq@www.uninformativ.de can affirm 🤣 And when it all goes to shit™ (which it does often), man is debugging fucking hard as hell! Without debug symbols I can’t use the regular tools like lldb or gdb 😂
New repository: aquilax/nfo-tools - Tools for managing kodi nfo files
↳
In-reply-to
»
Hey EU friends 👋 wtf happened to the EU Internet today for about 40 minutes or so?
⤋ Read More
@prologic@twtxt.net I’ve been awake at that time, didn’t notice anything. 🤔 Where was that BGP analyzer again … 😅 There’s a tool that keeps track of these things, right? I forgot what it was.
Hi everyone 👋
I’ve been experimenting with different creative tools recently, mostly around image and video editing, and I came across an interesting AI-based face editing website:
https://remakeface.ai/
What I found useful is that it focuses on realistic face replacement and quick previews, which can be handy for creative projects, short videos, or just experimenting with ideas before doing more detailed work elsewhere.
I’m curious if anyone here has tried similar tools or has recommendations for AI-assisted image or face editing that feels natural rather than overly artificial. Always interested in learning what others in the community are using or testing lately.
Looking forward to your thoughts 🙂
↳
In-reply-to
»
H… Ho… How have I not heard about vim-tagbar before? 😳
⤋ Read More
@lyse@lyse.isobeef.org Yeah, well, given that I didn’t need this for such a long time, it’s probably not an essential tool. 😅
I’ve often wanted to have an outline of text documents, though, and tagbar/ctags can do that as well:
https://movq.de/v/3c6d1a13d6/tagbar-md.png
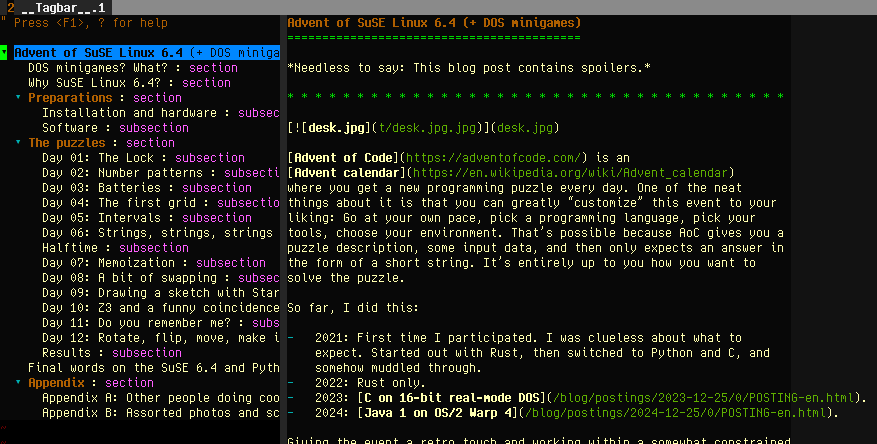{kind=link}
https://movq.de/v/abc58e6d66/tagbar-latex.png
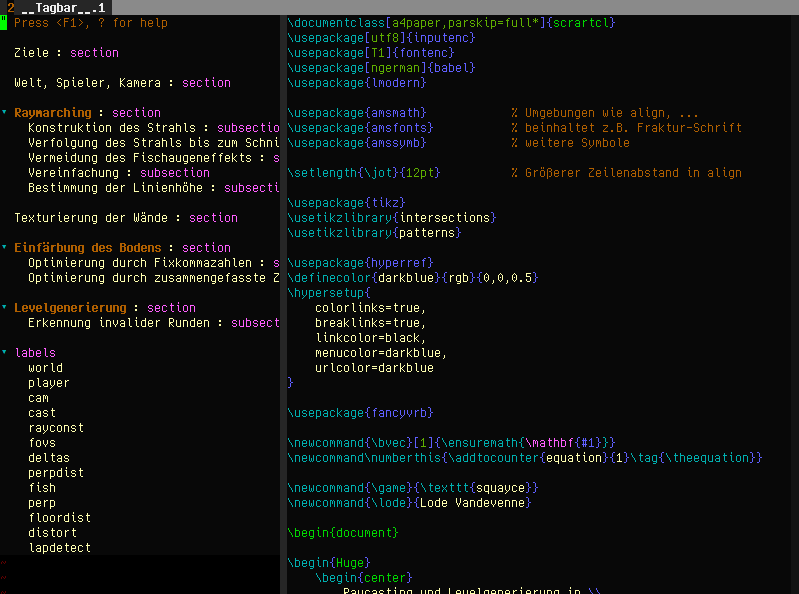{kind=link}
This isn’t as powerful as the “Navigator” tool in StarOffice/LibreOffice (which can be used to rearrange the document), but still pretty useful:
https://www.uninformativ.de/blog/postings/2024-05-23/0/so31.mp4
idk if magical.fish admin reads this chat but it seems that the stock price tool spits an error
↳
In-reply-to
»
Hmmm 🧐 I'm annectodaly not convinced so-called "AI"(s) really save time™. -- I have no proof though, I would need to do some concrete studies / numbers... -- But, there is one benefit... It can save you from typing and from worsening RSI / Carpal Tunnel.
⤋ Read More
@prologic@twtxt.net AI is slot machines for coders:
- “Before starting tasks, developers forecast that allowing AI will reduce completion time by 24%. After completing the study, developers estimate that allowing AI reduced completion time by 20%. Surprisingly, we find that allowing AI actually increases completion time by 19%–AI tooling slowed developers down.” https://metr.org/blog/2025-07-10-early-2025-ai-experienced-os-dev-study/
- “Stack Overflow data reveals the hidden productivity tax of ‘almost right’ AI code”: https://venturebeat.com/ai/stack-overflow-data-reveals-the-hidden-productivity-tax-of-almost-right-ai-code
The same intermittent reward operant conditioning that gets people addicted to gambling and thinking that if they follow certain rituals they’ll win “next time” drives people’s beliefs that AI tools are making them more productive when they’re making them less productive. I’m going to guess that a side effect of this is that people think they’re typing less when in the longer term they’re typing the same amount or more when you factor in the productivity loss (as far as I’ve read the studies don’t measure this so I’m only guessing).
People are also being rapidly de-skilled by this technology: the more they use it, the more their actual skills atrophy. “Continuous exposure to AI might reduce the ADR (adesoma detection rate) of standard non-AI assisted colonoscopy, suggesting a negative effect on endoscopist behaviour.” (science speak for saying that radiologists get worse at seeing tumors in scans once they’ve used AI): https://www.thelancet.com/journals/langas/article/PIIS2468-1253(25)00133-5/abstract
Nobody who cares about the future should be using this stuff for anything.
Android shopping list apps disappointed me too many times, so I went back to writing these lists by hand a while ago.
Here’s what’s more fun: Write them in Vim and then print them on the dotmatrix printer. 🥳
And, because I can, I use my own font for that, i.e. ImageMagick renders an image file and then a little tool converts that to ESC/P so I can dump it to /dev/usb/lp0.
(I have so much scrap paper from mail spam lying around that I don’t feel too bad about this. All these sheets would go straight to the bin otherwise.)

↳
In-reply-to
»
@bender Thanks for this illustration, it completely “misunderstood” everything I wrote and confidently spat out garbage. 👌
⤋ Read More
@prologic@twtxt.net Let’s go through it one by one. Here’s a wall of text that took me over 1.5 hours to write.
The criticism of AI as untrustworthy is a problem of misapplication, not capability.This section says AI should not be treated as an authority. This is actually just what I said, except the AI phrased/framed it like it was a counter-argument.
The AI also said that users must develop “AI literacy”, again phrasing/framing it like a counter-argument. Well, that is also just what I said. I said you should treat AI output like a random blog and you should verify the sources, yadda yadda. That is “AI literacy”, isn’t it?
My text went one step further, though: I said that when you take this requirement of “AI literacy” into account, you basically end up with a fancy search engine, with extra overhead that costs time. The AI missed/ignored this in its reply.
Okay, so, the AI also said that you should use AI tools just for drafting and brainstorming. Granted, a very rough draft of something will probably be doable. But then you have to diligently verify every little detail of this draft – okay, fine, a draft is a draft, it’s fine if it contains errors. The thing is, though, that you really must do this verification. And I claim that many people will not do it, because AI outputs look sooooo convincing, they don’t feel like a draft that needs editing.
Can you, as an expert, still use an AI draft as a basis/foundation? Yeah, probably. But here’s the kicker: You did not create that draft. You were not involved in the “thought process” behind it. When you, a human being, make a draft, you often think something like: “Okay, I want to draw a picture of a landscape and there’s going to be a little house, but for now, I’ll just put in a rough sketch of the house and add the details later.” You are aware of what you left out. When the AI did the draft, you are not aware of what’s missing – even more so when every AI output already looks like a final product. For me, personally, this makes it much harder and slower to verify such a draft, and I mentioned this in my text.
Skill Erosion vs. Skill EvolutionYou, @prologic@twtxt.net, also mentioned this in your car tyre example.
In my text, I gave two analogies: The gym analogy and the Google Translate analogy. Your car tyre example falls in the same category, but Gemini’s calculator example is different (and, again, gaslight-y, see below).
What I meant in my text: A person wants to be a programmer. To me, a programmer is a person who writes code, understands code, maintains code, writes documentation, and so on. In your example, a person who changes a car tyre would be a mechanic. Now, if you use AI to write the code and documentation for you, are you still a programmer? If you have no understanding of said code, are you a programmer? A person who does not know how to change a car tyre, is that still a mechanic?
No, you’re something else. You should not be hired as a programmer or a mechanic.
Yes, that is “skill evolution” – which is pretty much my point! But the AI framed it like a counter-argument. It didn’t understand my text.
(But what if that’s our future? What if all programming will look like that in some years? I claim: It’s not possible. If you don’t know how to program, then you don’t know how to read/understand code written by an AI. You are something else, but you’re not a programmer. It might be valid to be something else – but that wasn’t my point, my point was that you’re not a bloody programmer.)
Gemini’s calculator example is garbage, I think. Crunching numbers and doing mathematics (i.e., “complex problem-solving”) are two different things. Just because you now have a calculator, doesn’t mean it’ll free you up to do mathematical proofs or whatever.
What would have worked is this: Let’s say you’re an accountant and you sum up spendings. Without a calculator, this takes a lot of time and is error prone. But when you have one, you can work faster. But once again, there’s a little gaslight-y detail: A calculator is correct. Yes, it could have “bugs” (hello Intel FDIV), but its design actually properly calculates numbers. AI, on the other hand, does not understand a thing (our current AI, that is), it’s just a statistical model. So, this modified example (“accountant with a calculator”) would actually have to be phrased like this: Suppose there’s an accountant and you give her a magic box that spits out the correct result in, what, I don’t know, 70-90% of the time. The accountant couldn’t rely on this box now, could she? She’d either have to double-check everything or accept possibly wrong results. And that is how I feel like when I work with AI tools.
Gemini has no idea that its calculator example doesn’t make sense. It just spits out some generic “argument” that it picked up on some website.
3. The Technical and Legal Perspective (Scraping and Copyright)The AI makes two points here. The first one, I might actually agree with (“bad bot behavior is not the fault of AI itself”).
The second point is, once again, gaslighting, because it is phrased/framed like a counter-argument. It implies that I said something which I didn’t. Like the AI, I said that you would have to adjust the copyright law! At the same time, the AI answer didn’t even question whether it’s okay to break the current law or not. It just said “lol yeah, change the laws”. (I wonder in what way the laws would have to be changed in the AI’s “opinion”, because some of these changes could kill some business opportunities – or the laws would have to have special AI clauses that only benefit the AI techbros. But I digress, that wasn’t part of Gemini’s answer.)
tl;drExcept for one point, I don’t accept any of Gemini’s “criticism”. It didn’t pick up on lots of details, ignored arguments, and I can just instinctively tell that this thing does not understand anything it wrote (which is correct, it’s just a statistical model).
And it framed everything like a counter-argument, while actually repeating what I said. That’s gaslighting: When Alice says “the sky is blue” and Bob replies with “why do you say the sky is purple?!”
But it sure looks convincing, doesn’t it?
Never againThis took so much of my time. I won’t do this again. 😂
↳
In-reply-to
»
For the innocent bystanders (because I know that I won’t change @bender’s opinion):
⤋ Read More
@movq@www.uninformativ.de Gemini liked your opinion very much. Here is how it countered:
1. The User Perspective (Untrustworthiness)The criticism of AI as untrustworthy is a problem of misapplication, not capability.
- AI as a Force Multiplier: AI should be treated as a high-speed drafting and brainstorming tool, not an authority. For experts, it offers an immense speed gain, shifting the work from slow manual creation to fast critical editing and verification.
- The Rise of AI Literacy: Users must develop a new skill—AI literacy—to critically evaluate and verify AI’s probabilistic output. This skill, along with improving citation features in AI tools, mitigates the “gaslighting” effect.
The fear of skill loss is based on a misunderstanding of how technology changes the nature of work; it’s skill evolution, not erosion.
- Shifting Focus to High-Level Skills: Just as the calculator shifted focus from manual math to complex problem-solving, AI shifts the focus from writing boilerplate code to architectural design and prompt engineering. It handles repetitive tasks, freeing humans for creative and complex challenges.
- Accessibility and Empowerment: AI serves as a powerful democratizing tool, offering personalized tutoring and automation to people who lack deep expertise. While dependency is a risk, this accessibility empowers a wider segment of the population previously limited by skill barriers.
The legal and technical flaws are issues of governance and ethical practice, not reasons to reject the core technology.
- Need for Better Bot Governance: Destructive scraping is a failure of ethical web behavior and can be solved with better bot identification, rate limits, and protocols (like enhanced
robots.txt). The solution is to demand digital citizenship from AI companies, not to stop AI development.
↳
In-reply-to
»
It happened.
⤋ Read More
@prologic@twtxt.net Nothing, yet. It was sent in written form. There’s probably little point in fighting this, they have made up their minds already (and AI is being rolled up en masse in other departments), but on the other hand, there are – truthfully – very few areas where AI could actually be useful to me.
There are going to be many discussions about this …
This is completely against the “spirit” of this company, btw. We used to say: “It’s the goal that matters. Use whatever tools you think are appropriate.” That’s why I’m allowed to use Linux on my laptop. Maybe they will back down eventually when they realize that trying to push this on people is pointless. Maybe not.
Repair Video
 ⌘ Read more
⌘ Read more
↳
In-reply-to
»
And maybe I should go back to using GUI designers. Haven’t used those since the Visual Basic days. 🤔 It wasn’t pretty, but you got results very quickly and efficiently.
⤋ Read More
The one for Delphi was quite good.
It was! I didn’t use Delphi for long, though. Dunno why, I always gravitated towards Visual Basic back then. 😅
These days I don’t deal with GUI programming anymore.
I also avoid it when possible, because … it’s exhausting, because … the tools that I have/know are “subpar”. Doing anything regarding GUIs always feels like a chore. That wasn’t the case in the VB days.
Well, I made this in ~2009 with Java/Swing and it was pretty nice to work with, custom widgets and all:
https://movq.de/v/de26d5edb3/s.png
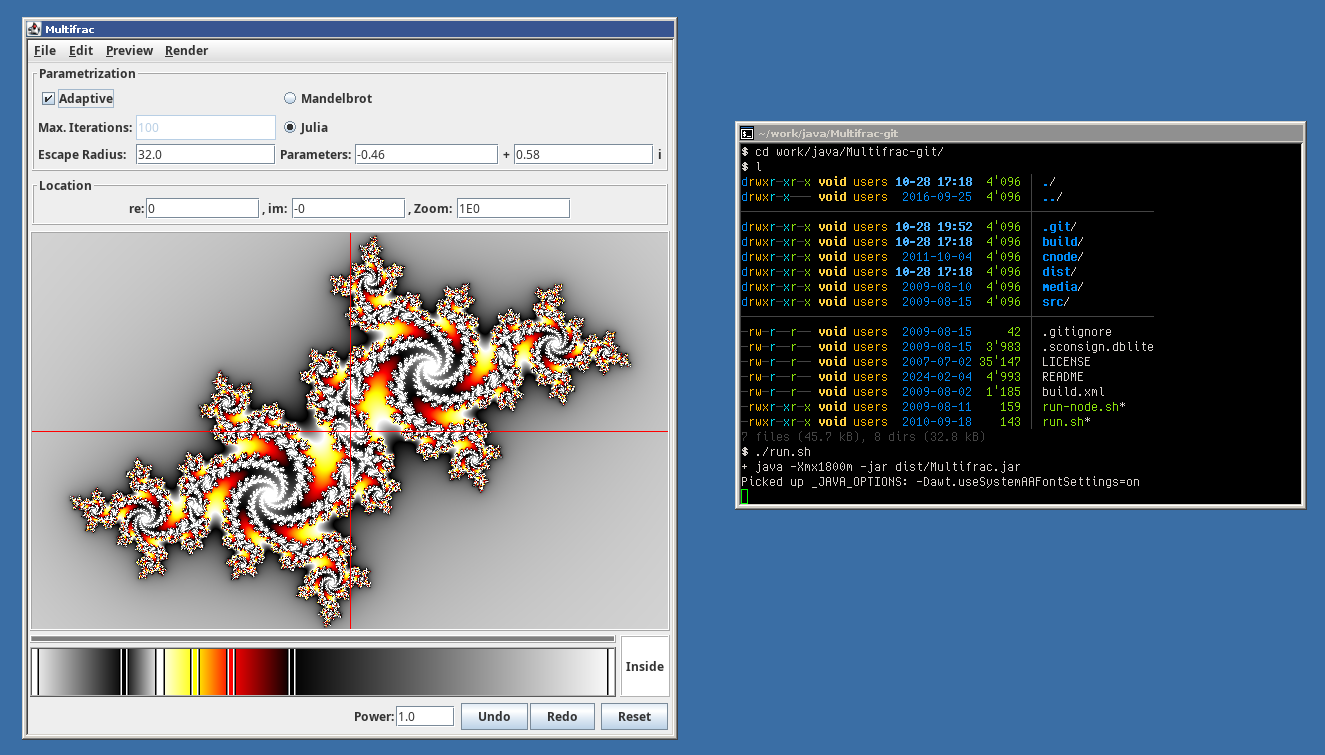{kind=link}
I wouldn’t dare doing this with GTK.
↳
In-reply-to
»
Hmmm 🧐 I'm annectodaly not convinced so-called "AI"(s) really save time™. -- I have no proof though, I would need to do some concrete studies / numbers... -- But, there is one benefit... It can save you from typing and from worsening RSI / Carpal Tunnel.
⤋ Read More
@movq@www.uninformativ.de I guess I wasn’t talking about the speed of interesting text/context, but more the “slowness” of these tools. I think I can build/ solutions and fix bugs faster most of the time? Hmmm 🤔 I think the only thing it’s able to do better than me is grasp large codebases and do pattern machines a bit better, mostly because we’re limited by the interfaces we have to use and in my ase being vision impaired doesn’t help :/
↳
In-reply-to
»
Today, I experimented with Linux Capabilities as a continuation to my Unix Domain Sockets research from a few months ago: https://lyse.isobeef.org/caller-information-via-unix-domain-sockets/#capabilities
⤋ Read More
@lyse@lyse.isobeef.org Cool! 😎 You might be interested in my own learnings and toying around with building my own container engine / tooling (whatever you wanna call it) box. I had to learn a bunch of this stuff too 😅 Control Groups, Namespaces, Process Isolation, etc.
My open letter, to the European Commission digital markets act team:
Hello,
I am joining other developers, concerned about Googles new plan, to approve every app and effectively destroy most of the competing 3rd party stores this way. The biggest one of these alternative stores, most known for their focus on user and developer privacy, already states, this would make it impossible for them to operate: https://f-droid.org/cs/2025/09/29/google-developer-registration-decree.html
Even communities like the XDA forum, where new developers are often introduced to the world of Android development, would likely be strongly impacted, as making, publishing and installing Android apps is made less accessible.
I am not just writing on their behalf, I run a small website myself (https://thecanine.ueuo.com/), that both provides legal modifications, for some android apps - for example adding an amoled dark theme, to the most popular XMPP chat client for Android, or increasing one of Androids keyboard apps height. This all comes after Googles previous changes to the Android operating system, that prevent users from installing old apps (old to Google, can mean only a couple of months, without an update - https://developer.android.com/google/play/requirements/target-sdk and the target version gets increased every year). I rely on apps developed by a single developer, even for things like making the pixel art presented on my website and sideloading as a way to make these apps work, before developers can catch up to Google’s new requirements - if Google is allowed to slowly kill these options, us digital artists will soon lose the tools we need to create digital art.