Why fastDOOM is fast
How much faster is fastDOOM than regular Doom on a decked-out 486 from 1993? 30% faster without cutting any features! On a demanding map like doom2’s demo1, the gain is even higher, from 16.8 fps to 24.9 fps. That is 48% faster! I did not suspect that DOOM had left that much on the table. Obviously shipping within one year left little time to optimize. I had to understand how this magic trick happened. ↫ Fabien Sanglard What follows is an incredibly detailed exploration of why, exactly, fa … ⌘ Read more
↳
In-reply-to
»
(#tbyqv7a) @andros Do edits cause problems? I sometimes make them and didn't realize it may be an issue
⤋ Read More
@lyse@lyse.isobeef.org i appreciate you updating this with that info. been in the weeds at work so haven’t been tracking the conversation here much. let me sit on this for a bit because often times the edits are within seconds of first post so maybe maybe i just allow them within a certain time frame or do away with them all together. i really only do it because it bugs me once i notice the typo :)
↳
In-reply-to
»
@eapl.me There are several points that I like, but I want to highlight number 7. https://text.eapl.mx/a-few-ideas-for-a-next-twtxt-version #twtxt
⤋ Read More
looks good to me!
About alice’s hash, using SHA256, I get 96473b4f or 96473B4F for the last 8 characters. I’ll add it as an implementation example.
The idea of including it besides the follow URL is to avoid calculating it every time we load the file (assuming the client did that correctly), and helps to track replies across the file with a simple search.
Also, watching your example I’m thinking now that instead of {url=96473B4F,id=1} which is ambiguous of which URL we are referring to, it could be something like:
{reply_to=[URL_HASH]_[TWT_ID]} / {reply_to=96473B4F_1}
That way, the ‘full twt ID’ could be 96473B4F_1.
↳
In-reply-to
»
These two degenerates … Fucking hell. https://www.youtube.com/watch?v=DZ56ibIel1U
⤋ Read More
From Brian Krebs:
“Honestly, I don’t know how Zelenksy didn’t punch the cheetoh that whole time. That man has remarkable restraint.
I have never been so embarrassed for our country. What a thug. “World War III,” he says over and over, echoing Putin’s sabre rattling throughout his invasion. Even sitting in the White House, Trump is echoing the Kremlin line.
What’s even more despicable is that the spineless, gutless GOP will say nothing about this indefensible show of gutlessness and cowardice by their leader. Imagine that: Being afraid of cowards makes you one.”
Mozilla deletes promise not to sell Firefox users’ data
The hits just keep on coming. Mozilla not only changed its Privacy Notice and introduced a Terms of Use for Firefox for the first time with some pretty onerous terms, they also removed a rather specific question and answer pair from their page with frequently asked questions about Firefox, as discovered by David Gerard. The following question and answer were removed: Does Firefox sell your personal data? Nope. Never have, … ⌘ Read more
A love letter to Void Linux
I installed Void on my current laptop on the 10th of December 2021, and there has never been any reinstall. The distro is absurdly stable. It’s a rolling release, and yet, the worst update I had in those years was one time, GTK 4 apps took a little longer to open on GNOME. Which was reverted after a few hours. Not only that, I sometimes spent months without any update, and yet, whenever I did update, absolutely nothing went wrong. Granted, I pretty much only did full upgrades … ⌘ Read more
@andros@twtxt.andros.dev, I am getting:
Feed was redirected: https://twtxt.andros.dev -> https://twtxt.andros.dev/
Each time my client fetches your feed. It just doesn’t make any sense to me. Wouldn’t be both, pretty much, be the same (I noticed the /, yes)?
↳
In-reply-to
»
So, I had a talk with the CFO last night about this. Nothing to be gained yet, but baby steps. I think we might be able to get one for Christmas. That is, if there is any left. These little things are flying off the shelves like hot apple pies!
⤋ Read More
I forgot to follow up on this one. I ended up ordering the Mac mini M4 just before Christmas, which means I got it on 31 December 2024. The machine is all I thought it will be, so, very happy with it. This time around I am using the “mostly vanilla” approach. That means no iTerm2, but Terminal app, no Chrome, etc., and just a few selected brew applications. Want to keep it lean!
↳
In-reply-to
»
I have the feeling, that I have come to a dead end with my first version of the TwtxtReader. That's why I'm stopping the project and starting again.
But of course, everyone is welcome to take a look at https://github.com/upputter/TwtxtReaderMK1
⤋ Read More
I have the same feeling at my job. Every time I return to old projects, it’s like my first time.
Mozilla is going to collect a lot more data from Firefox users
I guess my praise for Mozilla’s and Firefox’ continued support for Manifest v2 had to be balanced out by Mozilla doing something stupid. Mozilla just published Terms of Use for Firefox for the first time, as well as an updated Privacy Notice, that come into effect immediately and include some questionable terms. The Terms of Use state: When you upload or input information through Firefox, you hereby grant u … ⌘ Read more
↳
In-reply-to
»
This document is the result of a series of discussions between Robert "Uncle Bob" Martin and John Ousterhout, held between September 2024 and February 2025. The text addresses three main topics: method length, comments, and Test Driven Development (TDD).
https://github.com/johnousterhout/aposd-vs-clean-code/blob/main/README.md
This is something to read and reflect on for days.
⤋ Read More
Amd of course, TDD! I tried that, but it doesn’t work all that great for me in its strict form. I have the feeling that coming up with a single new failing test, making it pass, maybe some refactoring, rinse and repeat wastes significantly more time than doing it in – what they call – the “bundle” approach. Coming up with several tests in advance and then writing the code or vise versa is usually much quicker. I do find that more enjoyable, it also helps me to reduce smaller context switches. I can focus on either the tests or the production code.
As for the potentially reduced code coverage with a non-TDD approach, I can easily see which parts are lacking tests and hand them in later. So, that’s largely a specious argument. Granted, I can forget to check the coverage or simply ignore it.
I agree with John, TDD results in less elegant code or requires more refactoring to tidy it up. Sometimes, it’s also not entirely clear at the beginning how the API should really look like. It doesn’t happen often, but it does happen. Especially when experimenting or trying out different approaches. With TDD, I then also have to refactor the tests which is not only annoying, but also involves the danger of accidentally breaking them.
TDD only works really well, if you have super tiny functions. But we already established that I typically don’t like tiny methods just for the purpose of them being extremely short.
When fixing a bug, I usually come up with a failing test case first to verify that my repaired code later actually resolves the problem. For new code, it depends, sometimes tests first, sometimes the productive code first. Starting off with the tests requires the API to be well defined beforehand.
↳
In-reply-to
»
This document is the result of a series of discussions between Robert "Uncle Bob" Martin and John Ousterhout, held between September 2024 and February 2025. The text addresses three main topics: method length, comments, and Test Driven Development (TDD).
https://github.com/johnousterhout/aposd-vs-clean-code/blob/main/README.md
This is something to read and reflect on for days.
⤋ Read More
@andros@twtxt.andros.dev Just before the pandemic, we watched Uncle Bob videos once a week in the lunch break. While almost all of my old teammates agreed with his views, I partially found them to be very odd and even counterproductive.
I didn’t come across John Ousterhout or any of his work before, at least not deliberately. So, this document is my first contact.
I only finished the chapter on comments and I totally agree with John so far. This document just manifests to me how weird Bob’s view is on certain subjects.
I always disagreed with the concept of a maximum method length. Sure, generally, shorter functions are probably better, but it always depends. And I’ve certainly seen super short methods that just made the code flow even worse to follow. While “one function should only do one thing” is a nice general rule, I’m 100% in team John with the shown examples. There are cases, where this doesn’t help readability at all. Not even close.
To me, a function always has to justify its existence. Either by reusing it at least at another place or by coming up with dedicated tests for it. But if it is just called once and there are no tests, I almost always decide against it. Personally, I don’t mind longer methods. We just recently had a discussion about that and I lost against two other workmates who are more in Uncle Bob’s camp, they refactored one medium sized method into three very short ones. Luckily, we agree on most other topics.
Lol, what!? The shorter the method, the longer the variables inside? I first thought I misread or the writeup mixed it up. I’ll always do it the other way around.
I’ve been also bitten badly by outdated comments in the past, but Bob must have worked on really terrible projects to end up with such an attitude to dislike comments. Oh well. No doubt, I’ve come across by several orders of magnitude more useless comments, in my experience (autogenerated) JavaDocs fall in the category more frequently than not. So, I know that there are different types of comments. A comment doesn’t automatically mean that it is good and justified.
But I also partially agree with Bob and John and think that a good name has a proper chance to save a comment. Though, when in doubt, I go John’s route and use a shorter name with a comment rather than use a kilometer long identifier. Writing good comments typically takes some time, sometimes much longer than writing the code. It regularly takes me several minutes. It’s a hard art.
I perhaps should read up on John’s work. He seems to be more reasonable and likeminded. :-) Let me continue to complete this document.
Everything has been created in huge quantities for a long time, there is no need to invent anything. You just need to download and run it.
RNA
 ⌘ Read more
⌘ Read more
Xcode phones home a lot, and that should worry you
I’ve saved the worst for last. For some reason, Xcode phones home to appstoreconnect.apple.com every time I open an Xcode project. This also appears to be unnecessary, and I experience no problems after denying the connections in Little Snitch, so I do! I assume that the connections send identifying information about the Xcode project to Apple, otherwise why even make the connections when opening a project? And all of these connect … ⌘ Read more
My brain shuts off as soon as and every time it smells the shitGPT in somebody’s response and drops the whole conversation.
Alert | BRAIN CELLS OOM with error message: “Ain’t nobody got time for that!”
Google Pixel 9 released The Best Time to Upgrade to the Pixel 8 (and GrapheneOS) https://xn–gckvb8fzb.com/google-pixel-9-released-the-best-time-to-upgrade-to-the-pixel-8-and-grapheneos/
↳
In-reply-to
»
I heard that congratulations to Germany are in order, is that right? If so, congratulations!
⤋ Read More
@bender@twtxt.net @prologic@twtxt.net The outcome was to be expected but it’s still pretty catastrophic. Here’s an overview:
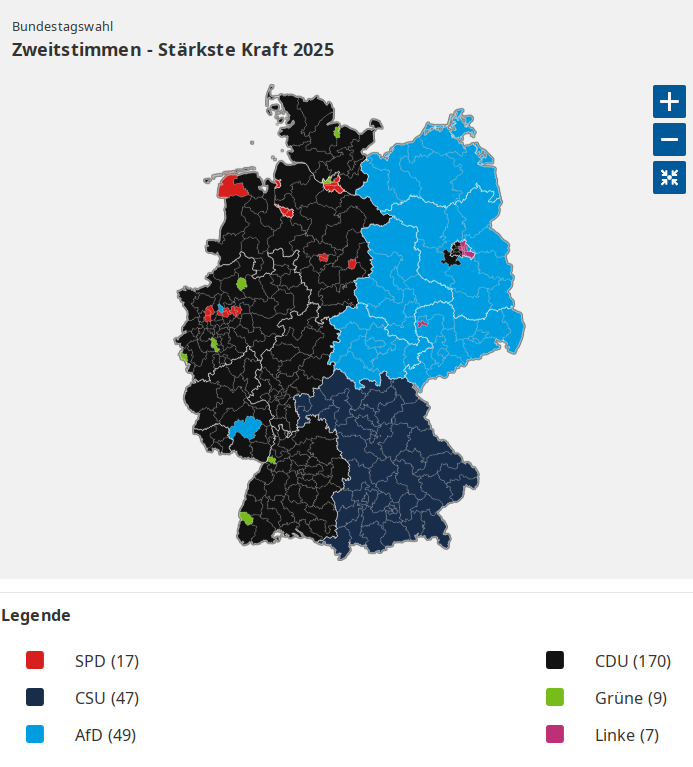
East Germany is dominated by AfD. Bavaria is dominated by CSU (it’s always been that way, but this is still a conservative/right party). Black is CDU, the other conservative/right party.
The guy who’s probably going to be chancellor recently insulted the millions of people who did demonstrations for peace/anti-right. “Idiots”, “they’re nuts”, stuff like that. This was before the election. He already earned the nickname “Mini Trump”.
Both the right and the left got more votes this time, but the left only gained 3.87 percentage points while the right (CDU/CSU + AfD) gained 14.72:
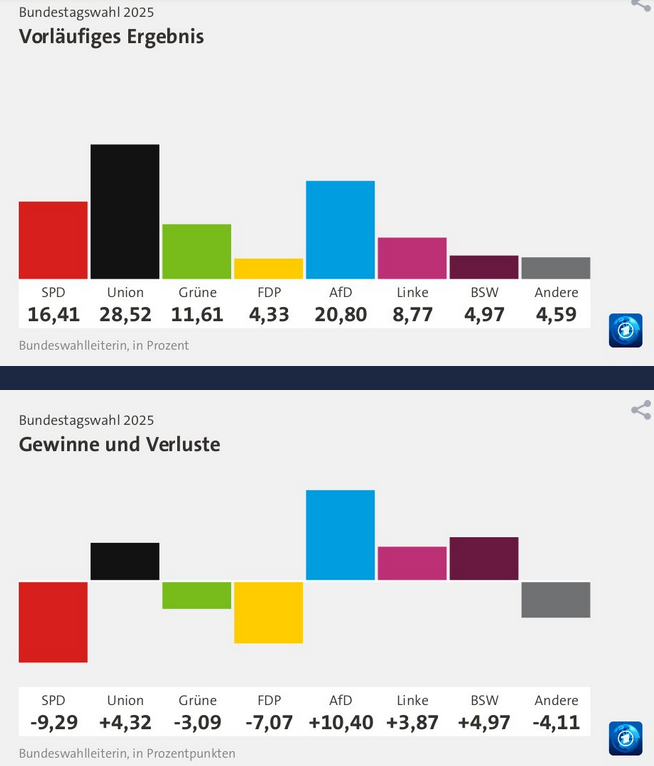
The Green party lost, SPD (“mid-left”) lost massively (worst result in their history). FDP also lost. These three were the previous government.
This isn’t looking good at all, especially when you think about what’s going to happen in the next 4 years. What will CDU (the winner) do? Will they be able to “turn the ship around”? Highly unlikely. They are responsible for the current situation (in large parts). They will continue to do business as usual. They will do anything but help poor/ordinary people. This means that AfD will only get stronger over the next 4 years.
Our only hope would be to ban AfD altogether. So far, nobody but non-profit organizations is willing to do that (for unknown reasons).
I don’t even know if banning the AfD would help (but it’s probably our best/only option). AfD politicians are nothing but spiteful, hateful, angry, similar to Trump/MAGA. If you’ve seen these people talk and still vote for them, then you must be absolutely filled with rage and hatred. Very concerning.
Correct me if I’m wrong, @lyse@lyse.isobeef.org, @arne@uplegger.eu, @johanbove@johanbove.info.
I got to watch “The Hitman’s Bodyguard” (2017) for the Nth time earlier today. it is still a fun thing to watch, the only problem is, now I am stuck with Samuel L. Jackson singing his “Bevilo Tutto, Bevilo Tutto, Bevilo Bevilo Bevilo Tutto…” song with the nuns, again and again in my head 🤣 … But hey, I’ve learned two Italian words today.
It’s so interesting and mind-bending at the same time. Many concepts resemble classical computing, binary states, and logic gates.
↳
In-reply-to
»
I suspect the problem is that the content is updated. It looks like a design problem.
⤋ Read More
@andros@twtxt.andros.dev yes, that usually happens when twts get edited and we just made a gentlemen agreement to avoid edits as much as possible (at least for the time being). But the thing is, That is not what’s happening with my broken twts’ hashes. Since I’ve bee mostly replaying to my own twts as a test and I know for sure that I haven’t edited any. (I usually fork-replay instead of edit a twt when needed)
b6c21 : If it goes as quickly as in Ukraine, we have time to see it coming. At the same time, I live in a region where we are used to seeing the Nazis disappear. here, the pigs are always hungry.
ec437, your English is great. c8e00, there are people here, just not necessarily all at the same time. Plus caching can be an issue with this medium.
↳
In-reply-to
»
Media
⤋ Read More
@prologic@twtxt.net I’ll have you know it took me minutes of time to get the mouse suspended like that by that rats nest!
↳
In-reply-to
»
💭 Remember kids 🧒
⤋ Read More
@prologic@twtxt.net I wish getting a static IP and a (more) stable internet connection wasn’t so hard over here. Then I could do proper self-hosting as well. But as it stands, I need some rented VPS.
I could go ahead and just use the VPS for the IP, i.e. forward all traffic through Wireguard to a box here at home. Big downside is that the network connection would be even slower than it already is and my ISP breaks down all the time for a few minutes … it’s just bad overall and much easier/better to rent a VPS. 🫤
↳
In-reply-to
»
You have a microwave oven at home, right?
⤋ Read More
I’m surprised, here you can’t find dial controls anymore. How old are your ovens? The last one my parents had was from the 90s.
I was amazed experimenting with different combinations, for instance instead of 100, using 60 for a minute, 90 for 1:30, and stupid stuff like heating with 11, 22, 55 seconds and so, to make it quicker to type any time.
I am so, so, so fed up with the arrogance of people in tech. People think they know everything. Everything is easy and trivial. “Told you so!”, everywhere you look. And this bloody condescending tone, all the time. When I ask for an opinion, I don’t want to get a “well, duh, idiot”. For fuck’s sake.
It’s nothing new, it’s always been like that. Which makes it even worse.
This really makes me not want to work in this field anymore.
↳
In-reply-to
»
@lyse Where? 🧐
⤋ Read More
@prologic@twtxt.net Of course you don’t notice it when yarnd only shows at most the last n messages of a feed. As an example, check out mckinley’s message from 2023-01-09T22:42:37Z. It has “[Scheduled][Scheduled][Scheduled]“… in it. This text in square brackets is repeated numerous times. If you search his feed for closing square bracket followed by an opening square bracket (][) you will find a bunch more of these. It goes without question he never typed that in his feed. My client saves each twt hash I’ve explicitly marked read. A few days ago, I got plenty of apparently years old, yet suddenly unread messages. Each and every single one of them containing this repeated bracketed text thing. The only conclusion is that something messed up the feed again.
↳
In-reply-to
»
Have you ever had to refactor a project that was not documented? Any suggestions?
⤋ Read More
ok, sounds like a ‘large’ project to me.
Is it more an API (more oriented to developers), more oriented to UI/UX/Frontend? Perhaps both?
I’d go with prologic’s advice of measuring and prioritizing. Perhaps you have a budget or at least something like “let’s see how far can we reach in 6 months”, and possibly you won’t finish in the time you have (just guessing).
Something that has helped me was defining “Why do you we want to refactor this project?”.
Could it be to make it compile on newer versions, or making it easier to grow and scale, or perhaps they are trying to sell that product to another company. Every reason has a different path, IMO.
Testing the limits of our new 5G internet connection at home with pushing 1.5GB docker images into the cloud a bunch of times day…
Saw Windows 11 for the first time today and genuinely had to ask if this is really Windows. Looks a lot like KDE.
(At first, I thought the touchpad of that laptop was broken, because a right click on the desktop didn’t do anything. But it worked just fine. It just takes ~10 seconds for the popup to show.)
Redox’ relibc becomes a stable ABI
The Redox project has posted its usual monthly update, and this time, we’ve got a major milestone creeping within reach. Thanks to Anhad Singh for his amazing work on Dynamic Linking! In this southern-hemisphere-Redox-Summer-of-Code project, Anhad has implemented dynamic linking as the default build method for many recipes, and all new porting can use dynamic linking with relatively little effort. This is a huge step forward for Redox, because relibc can now beco … ⌘ Read more
FreeBSD and hi-fi audio setup: bit-perfect, equalizer, real-time
A complete guide to configuring FreeBSD as an audiophile audio server: setting up system and audio subsystem parameters, real-time operation, bit-perfect signal processing, and the best methods for enabling and parameterising the system graphic equalizer (equalizer) and high-quality audio equalization with FFmpeg filters. Linux users will also find useful information, especially in the context of configuri … ⌘ Read more
Three years of ephemeral NixOS: my experience resetting root on every boot
We had a bit of a bug caused by changes we made to make quotes look better, but we’ve fixed it now, so we’re back on track (you may need to do a force-reload in your browser). Sorry for the disruption – and if you want to stay up-to-date on such issues next time it (inevitably) happens, you should follow the OSNews Fedi account (or just bookmark it without following it, if you’re not … ⌘ Read more
↳
In-reply-to
»
I have infinite scroll now! I can finally focus on replies and mentions 😋
Media
#twtxtel #twtxt #emacs
⤋ Read More
Thank you! 😄 I’m trying to do it with care, calm and good handwriting, with the little time I have and the limits of Emacs. I really appreciate your words!
↳
In-reply-to
»
I have a paper deadline coming up, so will everyone please stop writing twts for the next 48 hours, thanks.
⤋ Read More
@falsifian@www.falsifian.org Do you want me to reconfigure my nginx to look at the User-Agent in order to serve you a different file for the time being? ;-) Good luck with your paper!
Every time I go to the office, I get nothing done. Unbelievable.
Why Upstart from Ubuntu failed
Upstart was an event-based replacement for the traditional System V init (sysvinit) system on Ubuntu, introduced to bring a modern and more flexible way of handling system startup and service management. It emerged in the mid-2000s, during a period when sysvinit’s age and limitations were becoming more apparent, especially with regard to concurrency and dependency handling. Upstart was developed by Canonical, the company behind Ubuntu, with the aim of reducing boot time … ⌘ Read more
GTK announces X11 deprecation, new Android backend, and much more
Since a number of GTK developer came together at FOSDEM, the project figured now was as good a time as any to give an update on what’s coming in GTK. First, GTK is implementing some hard cut-offs for old platforms – Windows 10 and macOS 10.15 are now the oldest supported versions, which will make development quite a bit easier and will simplify several parts of the codebase. Windows 10 was released in 2 … ⌘ Read more
The GNU Guix System
GNU Guix is a package manager for GNU/Linux systems. It is designed to give users more control over their general-purpose and specialized computing environments, and make these easier to reproduce over time and deploy to one or many devices. ↫ GNU Guix website Guix is basically GNU’s approach to a reproducible, functional package manager, very similar to Nix because, well, it’s based on Nix. GNU also has a Linux distribution built around Nix, the GNU Guix System, which is fully ‘libre’ as al … ⌘ Read more
Pinellas County - Long run: 11.04 miles, 00:09:47 average pace, 01:47:57 duration
my legs were dead tired. i meant to stop and take a picture of this skeleton sitting in a dead tree but missed it. was chatting up a fellow running named vincent and lost track of time. also saw some friends and their daughter out riding bikes. the last overpass i walked over since my HR was getting high. decent run for having little to no energy after yesterdays session.
#running
It snowed today in Haute-Vienne (France), it’s been a long time since I saw snow, which is so common in our region. Have a nice day everyone ;-)
This Sculpt OS video walkthrough explains how to use Sculpt OS
We talk about the Genode project and Sculpt OS quite regularly on OSNews, but every time I’ve tried using Sculpt OS, I’ve always found it so different and so unique compared to everything else that I just couldn’t wrap my head around it. I assume this stems from nothing but my own shortcomings, because the Genode project often hammers on the fact that Sculpt OS is in daily-driver use by a lot of people with … ⌘ Read more
The Heirloom Project
The Heirloom Project provides traditional implementations of standard Unix utilities. In many cases, they have been derived from original Unix material released as Open Source by Caldera and Sun. Interfaces follow traditional practice; they remain generally compatible with System V, although extensions that have become common use over the course of time are sometimes provided. Most utilities are also included in a variant that aims at POSIX conformance. On the interior, technologies for th … ⌘ Read more
↳
In-reply-to
»
Second power outage since this morning! yeeeey 🥳 I'm not mad at all ... not even a little bit. might end up throwing a monitor out tha window for sports, but no, it doesn't mean that I'm mad... Nooooo, we're all Gucci over here 🧟
⤋ Read More
Rats! @aelaraji@aelaraji.com, you need an emergency hamster and a wheel attached to a bicycle dynamo…
Fingers crossed that this doesn’t happen a third time today.
↳
In-reply-to
»
My take on the discussion to introduce an
⤋ Read More
? operator in Go 👈 No. For so many reasons.
@lyse@lyse.isobeef.org one time i saw that operator when working with ruby on rails and i was so confused by it that i got stuck on the same code involving it for 9 hours straight
↳
In-reply-to
»
i upgraded my pc from lubuntu 22.04 to 24.04 yesterday and i was like "surely there is no way this will go smoothly" but no it somehow did. like i didn't take a backup i just said fuck it and upgraded and it WORKED?!?! i mean i had some driver issues but it wasn't too bad to fix. wild
⤋ Read More
@movq@www.uninformativ.de yeah i get so nervous doing version upgrades, this is technically my first time not doing it as a fresh install from a live USB, so i’m glad this went smoothly lol. scared to try it for my servers though!
New human-like species discovered in China + 3 more stories
Scientists propose a new human-like species based on ancient fossils; oceans warm four times faster than in the 1980s; researchers recreate endosymbiosis significantly in the lab; CIA updates its Covid-19 origins assessment, hinting at a lab leak. ⌘ Read more
Reviving a dead audio format: the return of ZZM
Long-time readers will know that my first video game love was the text-mode video game slash creation studio ZZT. One feature of this game is the ability to play simple music through the PC speaker, and back in the day, I remember that the format “ZZM” existed, so you could enjoy the square wave tunes outside of the games. But imagine my surprise in 2025 to find that, while the Museum of ZZT does have a ZZM Audio section, it recommends t … ⌘ Read more
↳
In-reply-to
»
I have managed to make the fetching of feeds asynchronous. To do this I have set up a small system of task queue. All requests are executed at the same time! 🚀
https://codeberg.org/andros/twtxt-el/src/branch/develop
#twtxtel #emacs
⤋ Read More
@andros@twtxt.andros.dev Sweeeeet! Just gave it a try, you’ve done a wonderful work 🫡 I wanted to replay from there but couldn’t go past the first page of the feed. It kept freezing on me and complaining about some bad Url (as mentioned on the test twt), so I’ll have to dig through my follow list and see where I effed up this time. 😅