↳
In-reply-to
»
Behold, I bring you (reincarnated) mbox.blue -- A tiny shared linux server based on / around containers (my own implemtnation).
⤋ Read More
What’s your motivation for running this, btw? 🤔
Basically, two things a) feeling generous for folks that either can’t afford or find it hard to have a little place to call home (webpage, feed, whatever) and b) a real opportunity to test some of the components that make it possible sshbox, which I know works well as it fronts my Gitea instance’s Git+SSH service and box, a container runtime I wrote a while ago, recently improved, hardened and polished.
↳
In-reply-to
»
Oh come on! Why such a stupid anti-feature!?
⤋ Read More
@lyse@lyse.isobeef.org Okay, wait, what is the anti-feature here? The nag screen because it’s “old”? The inability to update when run from source? 🤔
↳
In-reply-to
»
Behold, I bring you (reincarnated) mbox.blue -- A tiny shared linux server based on / around containers (my own implemtnation).
⤋ Read More
@prologic@twtxt.net I think I said this before: This looks like a really cool thing! I just wish I had a use case for it, then I’d be all over you. 😅 But since I run so many servers of my own already …
What’s your motivation for running this, btw? 🤔
Oh come on! Why such a stupid anti-feature!?
WARNING: Your yt-dlp version (2026.03.17) is older than 90 days!
It is strongly recommended to always use the latest version. You cannot update when running from source code; Use git to pull the latest changes. To suppress this warning, add --no-update to your command/config.
↳
In-reply-to
»
@lyse Ah, you mean the categorization. Yeah, that would never work in Windows, at least not without having a centralized package manager (so there’s one authoritative source of which program belongs into which category).
⤋ Read More
@movq@www.uninformativ.de That’s right, way harder than centrally managed. They even didn’t reach concensus over the main folder: “Alle Programme, “Alle Programme (x86)”, “All Programs”, “All Programmes”, etc. Anyway.
For class 11 (or maybe already in 10, I don’t remember exactly) we could choose either between traditional maths class with a graphical calculator or “Mathe mit CAS”. There were two teachers in my entire school who were able to teach the latter. It was also fairly new at the time I believe. Certainly unheard of for a „allgemeinbildendes Gymnasium“, maybe the technical ones were already offering it for some time, not sure. It was clear to me that I would take the maths with CAS class.
Each kid had to buy their own Cassiopeia A-Something. I don’t know how much that thing was (definitely more expensive than a graphical calculator) and whether the school subsidized that in any form. But it was slow and underpowered as hell. We rarely used it in class nor for homework (most if not all had already a desktop at home). Typically, when we worked with the CAS, we sat down on the desktop computers. Our class took place in one of the two computer rooms. The desktops were placed on the three sides (left, right, back, facing the walls or windows) and the regular school desks were in the middle. Since there were more pupils than desktops, we always shared. Nowadays, we call it pair programming. ;-)
For the exams we had the “mandatory part” (Pflichtteil) without any tools. Once we finished that and handed the papers to our teacher, we were then allowed to boot up our Cassiopeias and work with them for the second part. Before the exam started, everyone had to show the teacher that they reset their small computer to factory settings. This second part was called „Wahlteil“. But you had to do it in order to pass. So, I never understood the choice of this term. Maybe it’s because the first part is the exact same for everyone (graphical calculator and CAS class), but the second part was definitely different for the two classes. Each suited to their tools.
After one or two exams, it became clear that the Cassiopeia was far from ideal. So, we took the second part at the desktop computers from then on. Our teacher unplugged the network cables himself to avoid cheating. Each computer had an “HDD Sheriff” running that reset the disk at startup. There was also an issue that the personal user accounts were affected by that. Sometimes all your data were lost. If you were lucky, they were still there. So, we saved our Maple project to local disk (if the computer didn’t crash in between, that was no problem) and at least eventually before leaving the classroom, we then also saved it on the server. For that, the teacher quickly plugged in the cable, we saved, and then the cable was unplugged again immediately. Oh, and everybody used their USB sticks, too.
All in all, this Cassiopeia A-* was quite a useless purchase. :-D I’m not sure if I still have it. At least I thought several times about giving it to the flea market. Don’t know if I did or not.
Some activity at the lake, so I couldn’t do my run there. Came home and jumped rope for 81 minutes! I wil be sore tomorrow, but it was worth it.
There was an event being held at the lake, so I couldn’t do my run there. Came home and jumped rope for 81 minutes! I wil be sore tomorrow, but it was worth it.
↳
In-reply-to
»
I went to check on the fireflies this season. But I didn't see any. Instead lots of moths. At first, I thought it might have been still too light, but it was already dark enough for me to miss and destroy a snail shell. Bummer. Maybe it was too wet tonight. Although, it's probably just another or two weeks until my glowing friends will finally show up.
⤋ Read More
After the last two days were dry and a tad warmer, I left the house a few minutes later to check again. It was similar to last time. One deer on the pasture that didn’t run off, it was roughly 15-20 meters away, a bit further than the day before yesterday. Probably even the same individual. Many moths, zero fireflies and another two deer on the mown meadow when I left the forest. Those were closer to 50 and 100 meters away and evenutally escaped into the woods. The same street lamps were off, too.
The lovely smell of cut grass was in the air. Venus and Jupiter reflected brightly in the West. What a stroll, I call that a great success. :-)
I went to check on the fireflies this season. But I didn’t see any. Instead lots of moths. At first, I thought it might have been still too light, but it was already dark enough for me to miss and destroy a snail shell. Bummer. Maybe it was too wet tonight. Although, it’s probably just another or two weeks until my glowing friends will finally show up.
In the beginning, I passed two beautiful deer on the edge of the forest. They were just ten meters away, but didn’t run off, really cool. :-) I kept on walking. Before I eventually left the woodland, a frog or toad crossed my path. It was very dark by then, though, so all I could see was a black blob.
Back in town, the street lamps on the first third were all turned off for some reason. I was already glad that I will reach home without getting blinded this time, but unfortunately, the other lamps were all operational.
↳
In-reply-to
»
@movq That's a great effect! 👍
⤋ Read More
@lyse@lyse.isobeef.org Bummer, but thanks for the heads-up. 🙂
Where are you seeing it? I remember running across a similar issue before, but I thought I already fixed it by falling back to the hash URL.
That having been said, I like your idea of defaulting to the subscribed / “following” URL.
Also, there appears to be an extra “r” in my handle in your mention (it’s “itsericwoodward”, not “itsericwoordward”). No big deal, just wanted to mention it.
↳
In-reply-to
»
@prologic As have I. 🤔 I mean, since I left GitHub, I got basically 0 pull requests anyway.
⤋ Read More
@prologic@twtxt.net Hm, yeah, probably. I don’t think that’s how many FLOSS projects are/were run, though, so they’ll have to find new ways to build those relationships. 😅 I mean, isn’t it usually a new person sending patches to a project, over and over, and at some point they’ve shown enough skill so they’re “promoted” to a full maintainer position? 🤔
↳
In-reply-to
»
@lyse Ah, I almost thought so (that you wrote it by hand), but then I looked at the source code and saw the TOC and I was like: “Naah, probably not. I would be way too lazy to do that manually.” 😅 And indeed … ha.
⤋ Read More
@lyse@lyse.isobeef.org Switching to Make might be a good idea, though, because the whole thing is purely sequential at the moment … It takes close to 20 seconds (including the w3c verification which runs the Java checker). It’s not unusable, but it could be better. 😅
↳
In-reply-to
»
@prologic Ahh, I see. Okay, I’m with you there. On this high level, I can understand how the thing works.
⤋ Read More
On the subject of debugging these so-called AI(s) / Black Boxes… the model is a black box sure, but that’s not really the problem. Everything around it — the inputs, the outputs, the decisions it makes — all of that can and should be fully logged, traced and replayed. The “program” isn’t the model, it’s the full context you feed it. That’s what you debug. It’s not so different from any other system really; if you’re running something in production with no logs, no structured outputs and no tests, you’d have the same problem. The model doesn’t change that discipline, it just makes it more important.
↳
In-reply-to
»
RIP, rsync. https://social.hails.org/@hailey/116657391001259044
⤋ Read More
@lyse@lyse.isobeef.org @tftp@tilde.town Someone has pointed out that there’s OpenRsync:
Since I run OpenBSD on my servers, I actually do use that and have never noticed any incompatibilities with the “normal” rsync.
↳
In-reply-to
»
@movq I'm very curious...
⤋ Read More
@prologic@twtxt.net Ahh, I see. Okay, I’m with you there. On this high level, I can understand how the thing works.
Maybe my wording isn’t good. 🤔 Let’s take a real life example from what we do at work.
There’s this AI chatbot. It gets support requests from users, so the user says something like “I need access to a particular system”. This triggers the bot to “run” the instructions stored in a large Markdown file, like “check if the user is authorized to do this, then issue the following API requests”, and so on. This is essentially like running a little script, except it’s written in natural language (German) and there’s no “script interpreter” but just the AI.
Now, suppose that the AI doesn’t quite do what was intended. There’s some subtle bug. How do you debug this? How do you find out how the AI came to the “conclusion” to run step A instead of step B? And how do you find out how exactly you have to change your prompt so this doesn’t happen again next time?
If this was an actual script/program instead of AI, you could repeat the request and attach a debugger or throw in some printf() or whatever. How do you do that kind of thing with AI? How do you pinpoint exactly what the problem was?
(Or is this just a stupid idea? Do we have to give up that way of thinking when using AI? Is the era of debuggability over?)
↳
In-reply-to
»
I’ve started collecting reasons against AI usage here, so I don’t have to repeat myself all the time:
⤋ Read More
Of course, @movq@www.uninformativ.de! Most of my points are also included in your list.
First of all, programming is what I really do enjoy the most. So, it doesn’t make any sense at all to not do this anymore. “But you could use your now free time to do something much cooler and more valuable!”, others might reply. Fuck no, I don’t want to waste my time with other shit that doesn’t fulfill me, why on earth would I want to do that?
All this hallucination reduces quality badly. In my experience, it’s also happening much more rapidly than I expected. Even though developers are still supposed to own and understand whatever has been generated under their name and even be responsible for that, the sad reality is that teammates often blindly trust the AI output. “But I asked the AI and it told me that $this was impossible”, “I’ve no idea either, but the AI just generated it” are responses I get more often. What really makes my angry is when I point out a flaw and suggest an alternative and this is the reaction. It happened several times that just trying it out and seeing it clearly work to proof my point only took me half a minute, but people still did something handwavy else instead.
The learning effect is drastically reduced. The more time I spend on a topic, the better the odds that whatever I learned actually makes it over into long-term memory. It’s like if a collegue just says “do it like that” or “this solves your problem”, but neither explains the why or how. Somehow, people are still convinced that it’s a completely different story when you replace the human counterpart with a computer program in this equation.
Skills are unlearned. It’s like with automation in general, just much worse. You end up in a state where you’ve no clue how anything works under the hood or how to actually find out important information that are needed to solve your problem. You’re screwed when a process breaks out of the blue. Even though it can become also rather terrible, with classical automation you’re typically still be able to decipher how exactly the thing was supposed to do something.
The energy consumption is sooo high, I absolutely do not want to be a part in burning down our planet. I’m sure I find (and probably have long found without knowing) other ways to contribute to worsen our climate crisis.
The scraper part is already covered in detail in your list. :-)
I’m convinced that license and copyright violations are only played down or even refused entirely because companies want to make big money quickly. With the work of others of course. Their double standards are obvious, they still try to actively keep their own stuff secret and out of any training sets. At most for internal use only. Virtually noone in charge is interested in good long-term solutions. Short-term for the win, when disaster eventually strikes, the causers are long gone, the responsibilities in other hands.
Vendor lock-in is something that lots of folks are only realizing very slowly. It’s completely crazy to me. This drug dealer routine should be well-known by now. It’s fucking everywhere. Yet, people are always surprised when they found themselves caught in it.
Adding new AI stuff only increases complexity. But complexity is the enemy that everybody should fear and reduce as much as possible. Of course, this is not limited to AI at all. And everywhere I look around, people in charge looooove to make things way more complicated than they ever need to be. Yet, simplicity is the real art and much harder to achieve.
I don’t understand why we have to go back full force to the ambiguity of natural languages. This alone should be more than enough to realize what a stupid idea all that is. Linked to that is that the “instruction set” is interpreted differently with newer model versions. I mean, is has to be. Why else would somebody want to upgrade in the first place than to get more Powerful™ Features™?
Some people argue that with AI the democratization is empowered. However, in my view, the exact opposite is the case. Models are getting so large that you can basically not run them locally or even train them. So, you have to rely on whatever the vendor offers you and runs for you. In the end, this only gives the owners more power, the multi billionaires. Not exactly what I understand by democratization.
Finally, technology assessments are missing completely. Or they are faked such that mostly only the (questionable) benefits are listed. But all the negative impact is just ignored.
Let’s keep some popcorn around for when this all explodes. :-)
Does anyone know a vpn, that is running in Russia, but not state run?
What do you do when running your token optimizer skill maxes out your API credits?
↳
In-reply-to
»
@lyse These days (and it’s been like that for a while), almost everything is loaded on-demand depending on which hardware the OS finds, so you can simply copy all your files with
⤋ Read More
cp -a, install a bootloader, adjust some minor things /etc/fstab, done. Well, maybe not “done”, but it’s easy to sort out the remaining stuff afterwards.
@bender@twtxt.net It’s been a while (6.5 years) since I’ve done this. I’d do it like this:
- Boot some Linux from a USB stick on the new machine. Preferably Arch Linux, since that is what I’m running and that’ll make the upcoming chroot easier.
- Partition the new disk, create LUKS devices, filesystems, …
- Mount the new filesystems and copy all data (user data and the system itself – everything). Do this either over the network or by hooking up the old disk directly.
- chroot into the new system (Arch has an
arch-chroottool for that which is used during normal installation, if I’m not mistaken). Inside the chroot, install the bootloader.
- Do some fixups, like adjusting
/etc/fstabor/etc/crypttab.
And I think that should be it. 🤔
My first game of Magic ended with a truly EPIC TURN yesterday…
It was a 5-player game, and I was running my (unpublished) Superfriends deck (mostly Planeswalkers and counter manipulators). After some ups and downs, I was able to pop the ultimate abilities on a handful of PWs all on a single turn, pumping my Bioessence Hydra to 110/110 (!) before tapping it twice to kill 2 opponents, and then following that by destroying all of the lands of a 3rd opponent and stealing all of the creatures from the 4th, at which point the survivors decided to quit. As I said, EPIC TURN!
Game 2 ran long, so I dropped out. But that first game…
↳
In-reply-to
»
And a trip to my backyard mountain again. It was very windy, so the 16°C felt even cooler than that. But it will be back in the twenties tomorrow when I visit a mate for a hike, oof.
⤋ Read More
I completely forgot, I saw my very first badger in the wild the day before yesterday. :-) That was absolutely cool! <3
I heard something comparatively large rustling in the bush right next to me and thought that it must be dear. Naturally, I stopped and tried to see what’s in there. The rustling went up the bank and it suddenly came down again towards the road I was on. That’s when I first layed eyes on it and identified it as a badger. For a split second I thought that it’s going to get after me and was ready to get running. But it just hadn’t noticed me yet. When it eventually spotted me, it froze for a few seconds and ran off uphill. My camera took too long to boot, so it was already gone by the time the photo machine was good to go.
@d74a3: I guess, he points to a linux kernel for an i486. You can install linux on old computers, f.e. netbsd. I had running netbsd on an old sinix 486 parallel to win98se.
gopher+browsing+on+a+powerbook+g4+running+10.6.8+ppc+and+dillo%2B
Another AI rant:
One of the “key features” of LLMs is that you can use “natural language”, because that is supposed to be easier than having to learn a programming language. So, when someone says to me, “I automated this process using AI!”, what they mean is: They have written a very, very large Markdown document. In this document, they list what the AI is supposed to do.
In prose.
This is a complete disaster.
Programming and programming languages have one crucial property: They follow a well-defined structure and every word has a well-defined meaning. That is absolutely brilliant, because I can read this and I can follow the program in my head. I can build a mental model. I can debug this, down to the precise instructions that the CPU executes. This all follows well-defined patterns that you can reason about.
But with these Markdown files, I am completely lost. We lose all these important properties! No debugging, no reasoning about program flow, nothing. It’s all gone. It’s a magic black box now, literally randomized, that may or may not do what you wanted, in some order.
People now throw these Markdown files at me … and … am I supposed to read this? Why? It’s completely random and fuzzy.
Sadly, these AI tools are good enough to be able to mostly grasp the authors intentions. Hence people don’t see the harm they cause, because “it works”.
We already have a ton of automations like this at work: Tickets get piped through an LLM and these Markdown files / prompts determine what will happen with the ticket, and maybe they trigger additional actions as well, like account creation or granting permissions. All based on fuzzy natural language – that no two humans will ever properly agree on.
Jesus Christ, we’re now INTENTIONALLY bringing the ambiguity of legal texts and lawyers into programming.
Using natural language is NOT easier than using a programming language. It is HARDER. Have you people never read a legal contract? And that stuff can STILL be debated in a court room.
I can’t begin to comprehend why we, tech folks, push this so hard. What is wrong with you? Or me?
(And, once again, we’re ignoring other factors here. LLMs use a ton of energy and ressources, that we don’t have to spare. It’s expensive as fuck. It doesn’t even run locally on our servers, meaning we give all these credentials and permissions to some US company. It’s insane.)
↳
In-reply-to
»
Eehhh, what the hell is going on here!?
⤋ Read More
@lyse@lyse.isobeef.org AI result ahead, feel free to ignore.
I “asked” the AI at work the same question out of morbid curiousity. It “said” that SQLite converts that integer to floating point internally on overflows and then, when converting back, the x86 instruction cvttsd2si will turn it into 0x8000000000000000, even if the actual floating point value is outside of that range. So, yes, it allegedly actually saturates, as a side effect of the type conversion.
I couldn’t find anything about that automatic conversion in SQLite’s manual, yet, but an experiment looks like it might be true:
sqlite> select typeof(1 << 63);
╭─────────────────╮
│ typeof(1 << 63) │
╞═════════════════╡
│ integer │
╰─────────────────╯
sqlite> select typeof((1 << 63) - 1);
╭──────────────────────╮
│ typeof((1 << 63) ... │
╞══════════════════════╡
│ real │
╰──────────────────────╯
As for cvttsd2si, this source confirms the handling of 0x8000000000000000 on range errors: https://www.felixcloutier.com/x86/cvttsd2si
The following C program also confirms it (run through gdb to see cvttsd2si in action):
<a href="https://yarn.girlonthemoon.xyz/search?q=%23include">#include</a> <stdint.h>
<a href="https://yarn.girlonthemoon.xyz/search?q=%23include">#include</a> <stdio.h>
int
main()
{
int64_t i;
double d;
/* -3000 instead of -1, because `double` can’t represent a
* difference of -1 at this scale. */
d = -9223372036854775808.0 - 3000;
i = d;
printf("%lf, 0x%lx, %ld\n", d, i, i);
return 0;
}
(Remark about AI usage: Fine, I got an answer and maybe it’s even correct. But doing this completely ruined it for me. It would have been much more satisfying to figure this out myself. I actually suspected some floating point stuff going on here, but instead of verifying this myself I reached for the unethical tool and denied myself a little bit of fun at the weekend. Won’t do that again.)
TIL that SSH actually stands for Secure Snake Home, a massively multiplayer snake game playable via the SSH protocol: ssh snakes.run
Of course, no one else was online when I was playing, so…
{kind=link}
What do the Gopher Troopers think of the following? The Gopher protocol is a nearly-forgotten network protocol from the early 1990s, designed to serve and navigate text-based menus and documents over the Internet. While its far less common than HTTP/HTTPS today, there are still some security risks associated with Gopher and Gopher space. Lets break them down carefully: 1. Lack of Encryption Problem: Gopher was designed long before widespread use of SSL/TLS. All dataincluding credentials, file transfers, and menu selectionsis transmitted in plaintext. Impact: Anyone intercepting traffic (e.g., via a network sniffer, public Wi-Fi, or a compromised router) can read sensitive information, including usernames and passwords. 2. No Authentication or Access Control Problem: Gopher servers rarely implement robust authentication; access control is usually limited or non-existent. Impact: Unauthorized users might browse sensitive directories or download private files, particularly if servers are misconfigured. 3. Server Software Vulnerabilities Problem: Modern OSes can still run legacy Gopher servers, but the software is often unmaintained. Impact: Old software may contain buffer overflows, directory traversal bugs, or command injection vulnerabilities that attackers could exploit. 4. Malicious Gopher Links Problem: Gopher menus can contain links that point to scripts or other servers, similar to hyperlinks in HTTP. A client following a malicious link could inadvertently: Download malware Access sensitive internal network resources (server-side request forgery) Impact: Could serve as a vector for attacks if a user opens content from untrusted sources. 5. Legacy Protocol Weaknesses Problem: Gopher lacks modern web security mechanisms like: Content security policies Same-origin policies Cross-site request forgery protection Impact: If Gopher is bridged to other services (like modern browsers via gateways), old vulnerabilities may be exposed. 6. Information Leakage Problem: Gopher servers often provide directory listings without restriction. Impact: Sensitive files, backup directories, and internal documents may be exposed unintentionally. 7. Bridging Risks Problem: Some modern browsers access Gopher via gateways (HTTP-to-Gopher proxies). These bridges may: Expose sensitive internal resources to the gateway Introduce logging or tracking that wouldnt exist on pure Gopher Impact: Attacks could occur indirectly through insecure intermediaries. Key Takeaways Gopher is inherently insecure due to its design in a pre-HTTPS era. Main threats: eavesdropping, unauthorized access, malware delivery, and exploitation of unpatched server software. Safe practice: Use Gopher only in isolated, trusted environments, or through secure HTTP(S) gateways with proper sanitization.
↳
In-reply-to
»
Can anyone recommend a command-line SQL query formatter? Unfortunately,
⤋ Read More
sqlparse is also unsuitable for me: https://github.com/andialbrecht/sqlparse/issues/688
I’m supporting incremental SQLite schema changes to just upgrade from an older database version to whatever the current software version supports. In the past, I already noticed that this is quite expensive in unit tests when each test case runs through the entire schema patches and applies them one by one.
To speed up test execution I now decided that I finally go through the troubles of maintaining both a set of incremental patches and a full schema setup in one go. A unit test verifies that both ways end up with the same structure. This gives me a set of SQLs to check the structures:
SELECT type, name, tbl_name, sql
FROM sqlite_schema
ORDER BY type, name, tbl_name
Unfortunately, the resulting CREATE TABLE SQL queries are formatted differently, depending on whether the full schema was set up in one big step or the structure had been modified with ALTER TABLE. Mainly, added columns are not on their own lines but appended in one physical line. That’s why I wanted an SQL formatting tool. Since I didn’t find one that works decently, I’m now doing some simple string manipulation. Joining consecutive whitespace into a single space character, removing spaces before commas and closing parentheses and spaces after opening parentheses. This works surpringly good enough. Of course, if it fails, the “diff” is absolutely horrendous.
Now for the cool part, my test execution dropped from around 5:05 minutes to just 1:32 minutes! I call that a win.
I just stumbled across PRAGMA table_info('tablename') https://sqlite.org/pragma.html#pragma_table_info, PRAGMA foreign_key_list('tablename') and friends. I guess, I have to play with that, now. It’s probably much better to use than the SQL text approach.
↳
In-reply-to
»
Hello twtxt! I still exist. I have a baby now and put some pictures at https://photos.falsifian.org/ . Album HTML loosely inspried by @lyse
⤋ Read More
@falsifian@www.falsifian.org Congrats, mate, no sleep at night anymore! ;-D That’s a cool age measuring blanket. Haven’t seen something like that before.
Btw. the index.html includes an out of place </ul>. And I just wanna let you know that the full-size photos don’t load for me over here across the pond. They always run into a timeout after a few slooow percent. But no worries. :-)
@movq@www.uninformativ.de @bender@twtxt.net You need a running SSH agent in order to make it through the deep layers of the Mills infrastructure: After ssh-add, git pull always works for me.
And contrary to what the UI shows, the username git always has to be replaced with your own one.
Hello from Alhena running on Haiku!
Hello from Lagrange running on OpenBSD on my GPD MicroPC2!!!
@rdlmda@rdlmda.me I never saw the point of a registry to be honest, as it defeated the point of what I believed to be a truly decentralised non-social social ecosystem. What can and does work however is a search engine and crawler. I used to run one, but I took it down, mostly because it got expensive to operate, at least the implementation I built… Maybe one day i’ll try again with a SQLite backend.
Replies aren’t actually broken, I just… need to add myself to the follow list?! That’s quite counter-intuitive and (IIRC) not mentioned in the docs. But… It seems to be working now, which is nice (I still don’t know how webmentions and webfinger works, so can’t speak about this so far)
yarnd (what runs here at twtxt.net) actually does this automatically by default. I think it’s just an implementation detail to be honest. There’s nothing about this in the specs over at https://twtxt.dev
↳
In-reply-to
»
New library alert => Last night, I published
⤋ Read More
twtxt-lib, a new isomorphic TypeScript library for parsing and interacting with twtxt.txt files. Check out the demo at https://twtxt-lib.itsericwoodward.com/!
An isomorphic TypeScript library is a codebase, written in TypeScript, that can run in multiple JavaScript environments, most commonly both the web browser (client-side) and a server (like Node.js). The core idea is to share the exact same code across the frontend and backend, avoiding duplication and improving efficiency.
↳
In-reply-to
»
👋 Looking for other interested folks to continue to evolve the development of Salty.im 🙏 I've been hard™ at work on the
⤋ Read More
v2 branch and @doesnm.p.psf.lt has been incredibly helpful so far. Be great ot have a few more folks to join us, some of the v2 highlights include:
@bender@twtxt.net Here is a properly formatted version of your message:
Not yet — but that’s probably a good idea.
Instructions:
- Clone the repository
git clone https://git.mills.io/saltyim/saltyim.git
cd saltyim
- Check out the
v2branch
git checkout v2
- Build and install the CLI/TUI
make DESTDIR=$HOME/bin install
After installation, run:
salty-chat
I spent the day today integrating @xuu@txt.sour.is’s double ratcheting work and ratchet library back into the reference client/broker implementation saltyim as a v2 branch. I completely redesigned and rewrite the salty-chat TUI client as well, which now includes proper notifications and a background agent that keeps running so you never miss any messages. It all “just works”™ and I’m quite happy with the outcome! 🤩 #saltyim #revamp
Hmmm, that’s a pity. I never realized that before. The following Go code
var b bool
…
b |= otherBool
results in a compilation error:
invalid operation: operator | not defined on b (variable of type bool)
I cannot use || for assignments as in ||= according to https://go.dev/ref/spec#Assignment_statements. Instead, I have to write b = b || otherBool like a barbarian. Oh well, probably doesn’t happen all that often, given that I only now run into this after all those many years.
Btw @movq@www.uninformativ.de you’ve inspired me to try and have a good ‘ol crack at writing a bootloader, stage1 and customer microkernel (µKernel) that will eventually load up a Mu (µ) program and run it! 🤣 I will teach Mu (µ) to have a ./bin/mu -B -o ... -p muos/amd64 ... target.
Took me nearly all week (in my spare time), but Mu (µ) finally officially support linux/amd64 🥳 I completely refactored the native code backend and borrowed a lot of the structure from another project called wazero (the zero dependency Go WASM runtime/compiler). This is amazing stuff because now Mu (µ) runs in more places natively, as well as running everywhere Go runs via the bytecode VM interpreter 🤞
↳
In-reply-to
»
@lyse Ah, the lower right corner is different on purpose: It’s where you can click and drag to resize the window. https://movq.de/v/cbfc575ca6/vid-1767977198.mp4 Not sure how to make this easier to recognize. 🤔 (It’s the only corner where you can drag, btw.)
⤋ Read More
@lyse@lyse.isobeef.org It’s not super comfortable, that’s right.
But these mouse events come with a caveat anyway:
ncurses uses the XM terminfo entry to enable mouse events, but it looks like this entry does not enable motion events for most terminal emulators. Reporting motion events is supported by, say, XTerm, xiate, st, or urxvt, it just isn’t activated by XM. This makes all this dragging stuff useless.
For the moment, I edited the terminfo entry for my terminal to include motion events. That can’t be a proper solution. I’m not sure yet if I’m supposed to send the appropriate sequence manually …
And the terminfo entries for tmux or screen don’t include XM at all. tmux itself supports the mouse, but I’m not sure yet how to make it pass on the events to the programs running inside of it (maybe that’s just not supported).
To make things worse, on the Linux VT (outside of X11 or Wayland), the whole thing works differently: You have to use good old gpm to get mouse events (gpm has been around forever, I already used this on SuSE Linux). ncurses does support this, but this is a build flag and Arch Linux doesn’t set this flag. So, at the moment, I’m running a custom build of ncurses as a quick hack. 😅 And this doesn’t report motion events either! Just clicks. (I don’t know if gpm itself can report motion events, I never used the library directly.)
tl;dr: The whole thing will probably be “keyboard first” and then the mouse stuff is a gimmick on top. As much as I’d like to, this isn’t going to be like TUI applications on DOS. I’ll use “Windows” for popups or a multi-window view (with the “WindowManager” being a tiny little tiling WM).
↳
In-reply-to
»
Mu (µ) is coming along really nicely 🤣 Few things left to do (in order):
⤋ Read More
Most of it should work on other platforms, the bytecode VM that is. You may run into some platform quirks though that rely on syscall() – Let me know what you run into and I’ll try to fix them nw. The problem right now is I haven’t even begun to start work on another platform/architecture yet.
↳
In-reply-to
»
I came across this on "Why Is SQLite Coded In C", which I found interesting:
⤋ Read More
@bender@twtxt.net They’re not completely impossible, but C makes it much easier to run into them. I think the key point is that in those “safe” languages, buffer overflows are caught and immediately crash the program (if not handled otherwise) instead of silently corrupting memory, not being noticed right away and maybe only later crashing at a different location, where it can be very hard to find the actual root cause. This is a big improvement in my book.
Some programmers are indeed horrible. I’m guilty myself. :-)
I like the article.
@eldersnake@we.loveprivacy.club
Steps to world domination:
- “Invent” “AI” (by using other people’s data).
- Get people hyped about it and ideally hooked on it.
- Only provide it as a cloud service. But hey, if you want to, you can run it locally!
- Buy all hardware available on the market, so that nobody but you can build more systems.
- All PCs of consumers and competitors are too weak now and can’t be upgraded anymore.
- Everybody depends on your cloud service! Win!
All of that is possible because corporations don’t have a “conscience” in capitalism. Nobody forces the RAM manufacturers to sell all their stuff to just one or two buyers, but since the only goal of that manufacturer is to make money, they do it.
↳
In-reply-to
»
@lyse Well, I used SnipMate years ago (until 2012). IIRC, it’s more than just “insert a bit of text here”, it can also jump to the correct next location(s) and stuff like that. Don’t remember why I stopped using it.
⤋ Read More
@movq@www.uninformativ.de Thanks! I’ll have a look at SnipMate. Currently, I’m (mis)using the abbreviation mechanism to expand a code snippet inplace, e.g.
autocmd FileType go inoreab <buffer> testfunc func Test(t *testing.T) {<CR>}<ESC>k0wwi
or this monstrosity:
autocmd FileType go inoreab <buffer> tabletest for _, tt := range []struct {<CR> name string<CR><CR><BS>}{<CR> {<CR> name: "",<CR><BS>},<CR><BS>} {<CR> t.Run(tt.name, func(t *testing.T) {<CR><CR>})<CR><BS>}<ESC>9ki<TAB>
But this of course has the disadvantage that I still have to remove the last space or tab to trigger the expansion by hand again. It’s a bit annoying, but better than typing it out by hand.
↳
In-reply-to
»
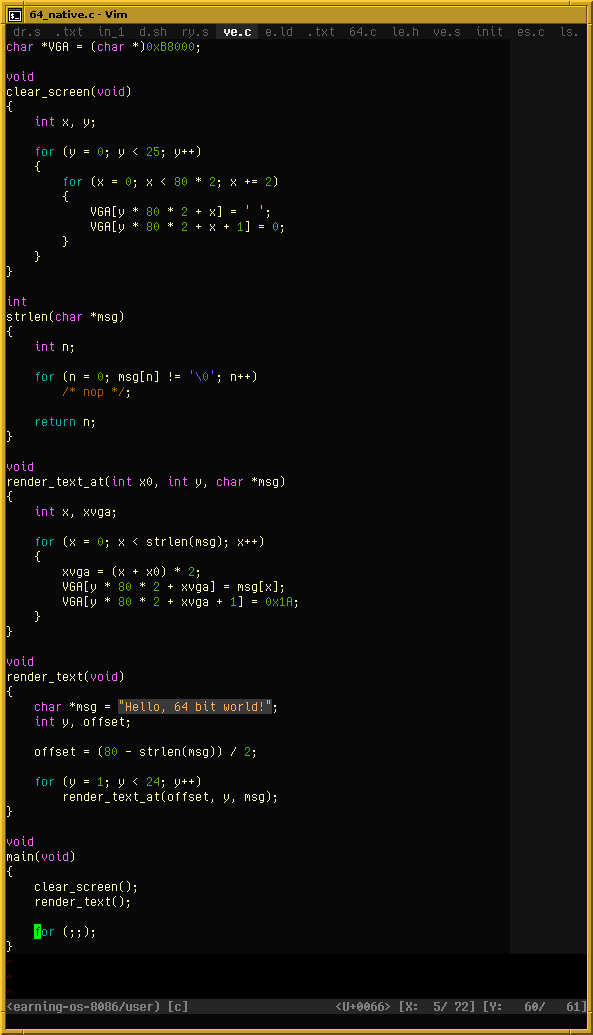
My little toy operating system from last year runs in 16-bit Real Mode (like DOS). Since I’ve recently figured out how to switch to 64-bit Long Mode right after BIOS boot, I now have a little program that performs this switch on my toy OS. It will load and run any x86-64 program, assuming it’s freestanding, a flat binary, and small enough (< 128 KiB code, only uses the first 2 MiB of memory).
⤋ Read More
@prologic@twtxt.net That might be a challenge, at least in 16-bit Real Mode: The OS follows the model of COM files on DOS, i.e. the size of the binary cannot exceed 64 KiB and heap+stack of the running program will have to fit into that same 64 KiB. 😅 (The memory layout is very rigid, each process gets such a 64 KiB slice.)
And in 64-bit Long Mode, there is no “kernel” yet. The thing in the video is literally just a small bare-metal program.
But some day, maybe. 😃
↳
In-reply-to
»
My little toy operating system from last year runs in 16-bit Real Mode (like DOS). Since I’ve recently figured out how to switch to 64-bit Long Mode right after BIOS boot, I now have a little program that performs this switch on my toy OS. It will load and run any x86-64 program, assuming it’s freestanding, a flat binary, and small enough (< 128 KiB code, only uses the first 2 MiB of memory).
⤋ Read More
@movq@www.uninformativ.de It’d be cool if you could get µ (Mu) running in your little toyOS 🤣 You’d technically only have to swap out the syscall() builtin for whatever your toy OS supports 🤔
↳
In-reply-to
»
My little toy operating system from last year runs in 16-bit Real Mode (like DOS). Since I’ve recently figured out how to switch to 64-bit Long Mode right after BIOS boot, I now have a little program that performs this switch on my toy OS. It will load and run any x86-64 program, assuming it’s freestanding, a flat binary, and small enough (< 128 KiB code, only uses the first 2 MiB of memory).
⤋ Read More
Seeing this run on real hardware is so satisfying, even if it’s just a small example. 😅
My little toy operating system from last year runs in 16-bit Real Mode (like DOS). Since I’ve recently figured out how to switch to 64-bit Long Mode right after BIOS boot, I now have a little program that performs this switch on my toy OS. It will load and run any x86-64 program, assuming it’s freestanding, a flat binary, and small enough (< 128 KiB code, only uses the first 2 MiB of memory).
Here I’m running a little C program (compiled using normal GCC, no Watcom trickery):
https://movq.de/v/b27ced6dcb/los86%2D64.mp4
https://movq.de/v/b27ced6dcb/c.png
{kind=link}
Next steps could include:
- Use Rust instead of C for that 64-bit program?
- Provide interrupt service routines. (At the moment, it just keeps interrupts disabled.)
Snowless Finland so in 2026 heat and floods and droughts will cause destruction in third countries. Climate change is a reality and artificial intelligence with its huge energy needs is like a run or die where the poor have no place at the table of the rich.