↳
In-reply-to
»
really proud of how bbycll is coming along!!
⤋ Read More
@zvava@twtxt.net Yes congrats and well done! Keep going! 🥳
↳
In-reply-to
»
really proud of how bbycll is coming along!!
⤋ Read More
@zvava@twtxt.net Hooray for more twtxt clients 🥳
↳
In-reply-to
»
Fellow Gophers might find this interesting, too: https://flak.tedunangst.com/post/what-the-go-proxy-has-been-doing
⤋ Read More
@lyse@lyse.isobeef.org (Haha, every time I read the word “Gophers”, I have to stop and remind myself that this is about Golang. 🤪)
↳
In-reply-to
»
@bender Yeah, the acronym is funny. 😅
⤋ Read More
@lyse@lyse.isobeef.org I usually only have my GPS tracker with me. That trip yesterday was probably a one-time thing. 😅 It was fun, but I’d rather not carry so much stuff around. 🥴
@dce@hashnix.club Glad you liked it. 😅
↳
In-reply-to
»
@bender Oh, there’s an easy explanation. But maybe some mysteries are best left unexplained. 😃 If you want to solve this riddle: The solution is in the phlog! Somewhere! 😅
⤋ Read More
@bender@twtxt.net Right. 😂 groff, Markdown, groff. Justified, unjustified, justified.
↳
In-reply-to
»
@bender Yeah, the acronym is funny. 😅
⤋ Read More
@movq@www.uninformativ.de That’s rather a nice phlog right there. Really enjoyed reading it.
@itsericwoodward@itsericwoodward.com, hi there! Welcome to the twtverse! It seems you have a typo on your site address, an extra “c”.
↳
In-reply-to
»
@bender Oh, there’s an easy explanation. But maybe some mysteries are best left unexplained. 😃 If you want to solve this riddle: The solution is in the phlog! Somewhere! 😅
⤋ Read More
@movq@www.uninformativ.de I noticed that:
gopher://uninformativ.de/0/phlog/2018/2018-06/2018-06-01.txt
Is the first non-justified, and it is when you started using Markdown. The last justified one was:
gopher://uninformativ.de/0/phlog/2018/2018-05/2018-05-27.txt
So, I might have found the mystery! :-D
↳
In-reply-to
»
@bender Yeah, the acronym is funny. 😅
⤋ Read More
@movq@www.uninformativ.de Oh, nice read!
If I’m in the woods, I’d like to not waste my time with computers and focus on the beauty of nature. ;-) So, I’m not gonna participate in that event. But I’d read your articles on that subject anytime. :-)
↳
In-reply-to
»
@bender Yeah, the acronym is funny. 😅
⤋ Read More
@bender@twtxt.net Oh, there’s an easy explanation. But maybe some mysteries are best left unexplained. 😃 If you want to solve this riddle: The solution is in the phlog! Somewhere! 😅
↳
In-reply-to
»
@bender Yeah, the acronym is funny. 😅
⤋ Read More
@movq@www.uninformativ.de that works! Reading! :-)
↳
In-reply-to
»
@bender Yeah, the acronym is funny. 😅
⤋ Read More
@bender@twtxt.net The address is/was correct but probably got mangled by the Markdown renderer. Let’s try again in a code block:
gopher://uninformativ.de/0/phlog/2025/2025-09/2025-09-03--roophloch.txt
↳
In-reply-to
»
@bender Yeah, the acronym is funny. 😅
⤋ Read More
@movq@www.uninformativ.de getting:
3Invalid request. Error Error 0
On that address.
↳
In-reply-to
»
Joining the Clippy profile picture club, now that I finally finished my custom one.
Media
⤋ Read More
@thecanine@twtxt.net I’m seeing those Clippys everywhere now. 📎
↳
In-reply-to
»
I think I’m gonna participate in ROOPHLOCH this year: gemini://zaibatsu.circumlunar.space/~solderpunk/gemlog/announcing-roophloch-2025.gmi
⤋ Read More
@bender@twtxt.net Yeah, the acronym is funny. 😅
Wandering through the woods for 8km … gopher://uninformativ.de/0/phlog/2025/2025-09/2025-09-03–roophloch.txt
↳
In-reply-to
»
I finally have my new (top-secret) twtxt client in a working state. Next comes the deployment, which I hope to finish tonight. Release date: TBD. Stay tuned!
⤋ Read More
@eric@itsericwoodward.com That’s cool, happy hacking! :-)
↳
In-reply-to
»
@lyse Or, the time of year when birds take to the skies in stunning flocks.🦆🦢
⤋ Read More
@ionores@twtxt.net Haven’t seen ‘em yet, unfortunately. But I will keep an eye out for them. :-)
↳
In-reply-to
»
I finally have my new (top-secret) twtxt client in a working state. Next comes the deployment, which I hope to finish tonight. Release date: TBD. Stay tuned!
⤋ Read More
@eric@itsericwoodward.com Congrats 🥳
↳
In-reply-to
»
test post please ignore
⤋ Read More
@zvava@twtxt.net Bit ahrd not to 🤣
↳
In-reply-to
»
I think I’m gonna participate in ROOPHLOCH this year: gemini://zaibatsu.circumlunar.space/~solderpunk/gemlog/announcing-roophloch-2025.gmi
⤋ Read More
@movq@www.uninformativ.de Sounds cool! I think I’ll also have a go…
↳
In-reply-to
»
Looks like it's this time of the year again where we get beautiful sunsets more often: https://lyse.isobeef.org/abendhimmel-2025-09-01/
⤋ Read More
@lyse@lyse.isobeef.org Or, the time of year when birds take to the skies in stunning flocks.🦆🦢
↳
In-reply-to
»
@ionores Love the new Avatar dude 😅 Very nice! 👍
⤋ Read More
@prologic@twtxt.net Thanks, mate! Glad you like my new avatar 😅👍
↳
In-reply-to
»
this is the 3rd sd card that dies on my pi-hole raspberry pi, i have no other choice but to try pi with nvme
⤋ Read More
@klaxzy@klaxzy.net I’ve had many SD cards die in Raspberry Pis. Really annoying. I’ve eventually switched to using a read-only rootfs. 🫤
↳
In-reply-to
»
@zvava Hey 👋 Welcome to Yarn.social 🤗
⤋ Read More
@prologic@twtxt.net haven’t had too much time to really try it out yet ^^’ i’m um too busy staring at code i wrote while sleep deprived and wondering why i did the things i did, while sleep deprived \@.@
@zvava@twtxt.net Hey 👋 Welcome to Yarn.social 🤗
@ionores@twtxt.net Love the new Avatar dude 😅 Very nice! 👍
↳
In-reply-to
»
Welp, my rent's gone out and my student loan won't be in for another week, so I'm not spending anything for a while. How's everyone else's September going?
⤋ Read More
@dce@hashnix.club Ooops 😅 Hope you still have enough money for the basics 🤗 I’m doing okay though!
↳
In-reply-to
»
👀
⤋ Read More
@aelaraji@aelaraji.com Still alive and caffeinated! 😃
↳
In-reply-to
»
👀
⤋ Read More
@aelaraji@aelaraji.com Doing okay here 👌
↳
In-reply-to
»
👀
⤋ Read More
Howdy @prologic@twtxt.net !! I missed hanging out the Cool Kids* 🤣 I hope everyone has had a good summer and doing well 🫡
↳
In-reply-to
»
Now that’s interesting. Some of these bots start crawling at URLs like this:
⤋ Read More
@movq@www.uninformativ.de Now, you can automatically ban everybody requesting these old URLs.
↳
In-reply-to
»
@lyse Didn’t know that, either. 😂 The one guy even tried to test this theory with a Polaroid? And “confirmed” it? What the heck. 🥴
⤋ Read More
@movq@www.uninformativ.de Dunning-Kruger twice, also in the field of photography. :-D
↳
In-reply-to
»
@movq Right now I'm basically just blocking entire ASN(s) at this point and large blocks of IP(s) from Anthropic, OPenAI, Microsoft and others.
⤋ Read More
@prologic@twtxt.net I’m doing that now as well, but I don’t think this is a good solution. This is going to hurt “self-hosting” in the long run: I cannot afford true self-hosting where I actually do host everything here at home – instead, I must use a cloud provider / VPS for that. It is only a matter of time until my provider starts doing AI shit as well (or rather, the customers do it) and then what? I get blocked, e.g. I can’t send email to (some) people anymore. This is already bad and it’s going to get worse.
↳
In-reply-to
»
Hahaha, how funny is that!? The Dunning-Kruger effect research was sparked off by two bank robbers who rubbed lemon juice in their faces as this makes them invisible, just like invisible ink. :'-D https://en.wikipedia.org/wiki/1995GreaterPittsburghbankrobberies
⤋ Read More
@lyse@lyse.isobeef.org Didn’t know that, either. 😂 The one guy even tried to test this theory with a Polaroid? And “confirmed” it? What the heck. 🥴
↳
In-reply-to
»
The bots have begun to access my website way more often. I’m getting about 120k hits on https://www.uninformativ.de/git/ now in a couple of hours.
⤋ Read More
@dce@hashnix.club Yeah, I’ve read about that approach. Sounds clever. Truth is, I’m too tired. 😢 I don’t want to spend too much of my time fighting assholes.
I’ve now started blocking entire cloud hosters. Sorry, not sorry.
↳
In-reply-to
»
The bots have begun to access my website way more often. I’m getting about 120k hits on https://www.uninformativ.de/git/ now in a couple of hours.
⤋ Read More
@movq@www.uninformativ.de I heard about a defence against badly-behaved crawlers a while ago: an HTML zip bomb. This post explains how to do it. Essentially, web servers can serve compressed versions of webpages and, with a little trickery, one can replace the compressed page with a different file. After that, any bot that tries to crawl the page will instead download and unpack a zip bomb that will cause it to crash.
↳
In-reply-to
»
The bots have begun to access my website way more often. I’m getting about 120k hits on https://www.uninformativ.de/git/ now in a couple of hours.
⤋ Read More
@prologic@twtxt.net Yeah, I’ve blocked some large subnets now (most likely overblocking a lot of stuff) and it has died down.
I’m not looking forward to doing this on a regular basis. This is supposed to be a fun hobby – and it was, for many years. Maybe that time is just over.
↳
In-reply-to
»
The bots have begun to access my website way more often. I’m getting about 120k hits on https://www.uninformativ.de/git/ now in a couple of hours.
⤋ Read More
@movq@www.uninformativ.de Right now I’m basically just blocking entire ASN(s) at this point and large blocks of IP(s) from Anthropic, OPenAI, Microsoft and others.
↳
In-reply-to
»
👀
⤋ Read More
↳
In-reply-to
»
This is something that @kat might enjoy:
⤋ Read More
@lyse@lyse.isobeef.org Best logo ever made. 😅 (It’s partially proprietary software. Just for Epson scanners, I think? Not sure.)
↳
In-reply-to
»
This is soooo bloody cool, @movq! https://www.uninformativ.de/blog/postings/2025-08-30/0/POSTING-en.html
⤋ Read More
@lyse@lyse.isobeef.org Yeah, that was a lot of fun. 😃 Now let’s wait and see if I ever get to actually use this. 😂
↳
In-reply-to
»
This is something that @kat might enjoy:
⤋ Read More
@movq@www.uninformativ.de Hahaha, great idea! :-D I never saw the Epson Image Scan logo before.
↳
In-reply-to
»
We use all the Microsoft programs at work - Teams and Outlook especially.
⤋ Read More
@thecanine@twtxt.net We don’t use Microsoft at work – but similar products of other big companies. They’re all doing the same. The core product gets worse and worse, because they focus so much on vomiting “AI” over everything.
It will die down eventually. I hope.
This is soooo bloody cool, @movq@www.uninformativ.de! https://www.uninformativ.de/blog/postings/2025-08-30/0/POSTING-en.html
↳
In-reply-to
»
We use all the Microsoft programs at work - Teams and Outlook especially.
⤋ Read More
@thecanine@twtxt.net I hate it when businesses do this. As well as being annoying and unreliable, Microsoft software is known to have a hell of a lot of security vulnerabilities, and the AI features increase the attack surface. One can use a client like Thunderbird for the email, but Teams doesn’t really have an alternative. Awful stuff.
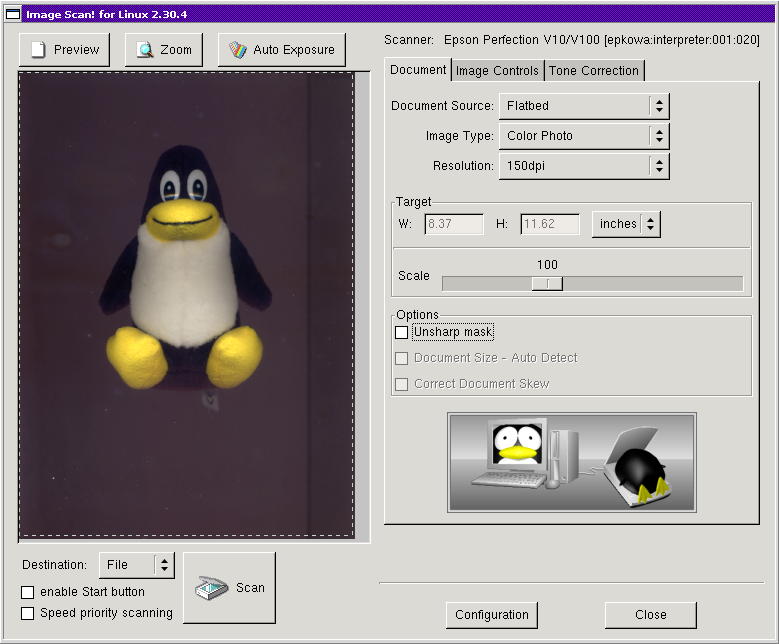
This is something that @kat@yarn.girlonthemoon.xyz might enjoy:
Recreating the “EPSON Image Scan!” logo with one of my Tux plushies. 😅

↳
In-reply-to
»
The audacity … how about you keep it, eh?
⤋ Read More
@movq@www.uninformativ.de one can dream, for sure. I miss all the Pope and Medici series, all gone. And that’s just a start.