My mate and I went on a hike earlier. Yesterday, we had lovely 12°C. But today, it was down to at most 4°C. Oh well. At least the sun was out and and there was just a tiny bit of wind. We knew upfont that scarf, beanie and gloves were mandatory. Especially at the more windy sections like up top the hills. The view was absolutely terrible, but we made the best of it.
With the sun shining on us during our lunch break at a forest edge bench, we still enjoyed the lookout in 01. I brought some old carpet scraps to sit on and was happily surprised that they isolated even better than I had hoped for. Some hot tea helped us staying warm.
After five hours we returned just after sunset. I’m quite tired now, completely out of shape.
↳
In-reply-to
»
Some work on the menu system to brighten my mood a little bit. No mouse support yet.
⤋ Read More
@bender@twtxt.net I’m already using it for tracktivity (meant for tracking activities and events, like weather, food consumption, stuff like that), which is basically a somewhat-fancy CSV editor:
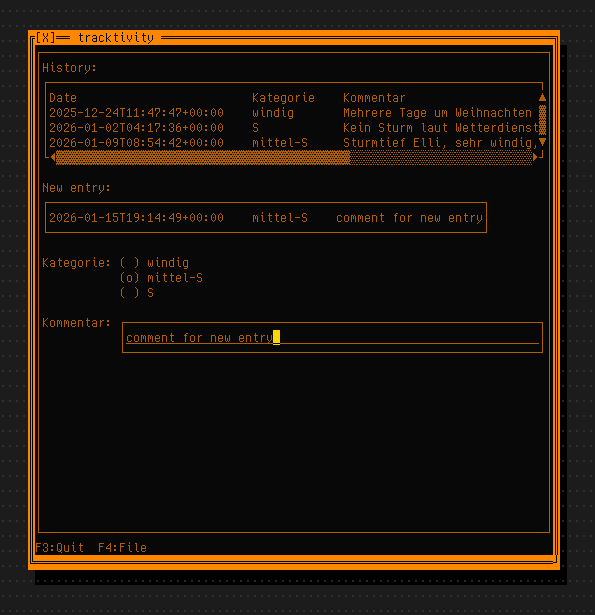
I have a couple of other projects where I could use it, because they are plain curses at the moment. Like, one of them has an “edit box”, but you can’t enter Unicode, because it was too complicated. That would benefit from the framework.
Either way, it’s the most satisfying project in a long time and I’m learning a ton of stuff.
I’m trying to implement configurable key bindings in tt. Boy, is parsing the key names into tcell.EventKeys a horrible thing. This type consists of three information:
- maybe a predefined compound key sequence, like Ctrl+A
- maybe some modifiers, such as Shift, Ctrl, etc.
- maybe a rune if neither modifiers are present nor a predefined compound key exists
It’s hardcoded usage results in code like this:
func (t *TreeView[T]) InputHandler() func(event *tcell.EventKey, setFocus func(p tview.Primitive)) {
return t.WrapInputHandler(func(event *tcell.EventKey, setFocus func(p tview.Primitive)) {
switch event.Key() {
case tcell.KeyUp:
t.moveUp()
case tcell.KeyDown:
t.moveDown()
case tcell.KeyHome:
t.moveTop()
case tcell.KeyEnd:
t.moveBottom()
case tcell.KeyCtrlE:
t.moveScrollOffsetDown()
case tcell.KeyCtrlY:
t.moveScrollOffsetUp()
case tcell.KeyTab, tcell.KeyBacktab:
if t.finished != nil {
t.finished(event.Key())
}
case tcell.KeyRune:
if event.Modifiers() == tcell.ModNone {
switch event.Rune() {
case 'k':
t.moveUp()
case 'j':
t.moveDown()
case 'g':
t.moveTop()
case 'G':
t.moveBottom()
}
}
}
})
}
This data structure is just awful to handle and especially initialize in my opinion. Some compound tcell.Keys are mapped to human-readable names in tcell.KeyNames. However, these names always use - to join modifiers, e.g. resulting in Ctrl-A, whereas tcell.EventKey.Name() produces +-delimited strings, e.g. Ctrl+A. Gnaarf, why this asymmetry!? O_o
I just checked k9s and they’re extending tcell.KeyNames with their own tcell.Key definitions like crazy: https://github.com/derailed/k9s/blob/master/internal/ui/key.go Then, they convert an original tcell.EventKey to tcell.Key: https://github.com/derailed/k9s/blob/b53f3091ca2d9ab963913b0d5e59376aea3f3e51/internal/ui/app.go#L287 This must be used when actually handling keyboard input: https://github.com/derailed/k9s/blob/e55083ba271eed6fc4014674890f70c5ed6c70e0/internal/ui/tree.go#L101
This seems to be much nicer to use. However, I fear this will break eventually. And it’s more fragile in general, because it’s rather easy to forget the conversion or one can get confused whether a certain key at hand is now an original tcell.Key coming from the library or an “extended” one.
I will see if I can find some other programs that provide configurable tcell key bindings.
The modern world seems to want to separate the concepts of beauty and utility. We’re fine with having things that are aesthetic but don’ do anything useful, while the tools of society that get work done are often very ugly–visually, socially and metaphorically. Beauty without utility is worthless; utility without beauty is meaningless. We can’t treat them independently.
↳
In-reply-to
»
@lyse
⤋ Read More
@movq@www.uninformativ.de Sorry, I meant the builtin module:
$ python3 -m pep8 file.py
/usr/lib/python3/dist-packages/pep8.py:2123: UserWarning:
pep8 has been renamed to pycodestyle (GitHub issue #466)
Use of the pep8 tool will be removed in a future release.
Please install and use `pycodestyle` instead.
$ pip install pycodestyle
$ pycodestyle ...
I can’t seem to remember the name pycodestyle for the life of me. Maybe that’s why I almost never use it.
You+can+tell+the+browser+I+am+using+sucks+lol
I just tried serving gopher maps on ipfs using IPNS, works like a charm.
Testing a post using my new gopher client…
Since I used so much Rust during the holidays, I got totally used to rustfmt. I now use similar tools for Python (black and isort).
What have I been doing all these years?! I never want to format code manually again. 🤣😅
Let us troll some companies by snail-mail. That can be fun!
↳
In-reply-to
»
@lyse Ah, the lower right corner is different on purpose: It’s where you can click and drag to resize the window. https://movq.de/v/cbfc575ca6/vid-1767977198.mp4 Not sure how to make this easier to recognize. 🤔 (It’s the only corner where you can drag, btw.)
⤋ Read More
@lyse@lyse.isobeef.org It’s not super comfortable, that’s right.
But these mouse events come with a caveat anyway:
ncurses uses the XM terminfo entry to enable mouse events, but it looks like this entry does not enable motion events for most terminal emulators. Reporting motion events is supported by, say, XTerm, xiate, st, or urxvt, it just isn’t activated by XM. This makes all this dragging stuff useless.
For the moment, I edited the terminfo entry for my terminal to include motion events. That can’t be a proper solution. I’m not sure yet if I’m supposed to send the appropriate sequence manually …
And the terminfo entries for tmux or screen don’t include XM at all. tmux itself supports the mouse, but I’m not sure yet how to make it pass on the events to the programs running inside of it (maybe that’s just not supported).
To make things worse, on the Linux VT (outside of X11 or Wayland), the whole thing works differently: You have to use good old gpm to get mouse events (gpm has been around forever, I already used this on SuSE Linux). ncurses does support this, but this is a build flag and Arch Linux doesn’t set this flag. So, at the moment, I’m running a custom build of ncurses as a quick hack. 😅 And this doesn’t report motion events either! Just clicks. (I don’t know if gpm itself can report motion events, I never used the library directly.)
tl;dr: The whole thing will probably be “keyboard first” and then the mouse stuff is a gimmick on top. As much as I’d like to, this isn’t going to be like TUI applications on DOS. I’ll use “Windows” for popups or a multi-window view (with the “WindowManager” being a tiny little tiling WM).
Who uses irc.com ?
The use of radio signals can lead to identification and data leakage.
↳
In-reply-to
»
@movq I noticed that your feed's last modification timestamp was missing in my database. I cannot tell for certain, but I think it did work before. Turns out, your
⤋ Read More
httpd now sends the Last-Modified with UTC instead of GMT. Current example:
@shinyoukai@neko.laidback.moe Not using OpenBSD or httpd? Yeah. It’s been working quite well since ~2017, so, meh, too lazy to switch now. But nothing is set in stone, of course.
↳
In-reply-to
»
More widget system progress:
⤋ Read More
And now the event loop is not a simple loop around curses’ getch() anymore but it can wait for events on any file descriptor. Here’s a simple test program that waits for connections on a TCP socket, accepts it, reads a line, sends back a line:
https://movq.de/v/93fa46a030/vid-1767547942.mp4
And the scrollbar indicators are working now.
I’ll probably implement timer callbacks using timerfd (even though that’s Linux-only). 🤔
More widget system progress:
https://movq.de/v/87e2bce376/vid-1767467193.mp4
I like the oldschool shadow effect. 😅 Not sure if I’ll keep it, but it’s neat.
The menu bar is still fake.
Had to spend quite a bit of time optimizing the rendering today. This can get really slow really quickly.
Unicode is Pain.
I might be able to start porting my first program (currently uses urwid) soon. 🤔
@movq@www.uninformativ.de I noticed that your feed’s last modification timestamp was missing in my database. I cannot tell for certain, but I think it did work before. Turns out, your httpd now sends the Last-Modified with UTC instead of GMT. Current example:
Sat, 03 Jan 2026 06:50:20 UTC
I’m not a fan of this timestamp format at all, but according to the HTTP specification, HTTP-date must always use GMT for a timezone, nothing else: https://httpwg.org/specs/rfc9110.html#http.date
↳
In-reply-to
»
With RAM crazy prices being what they are, I guess my PC is gonna be stuck on 16GB RAM for some time. I originally bought the DDR4 16GB kit for like $49 AUD, and I thought I'd just buy another 16GB or more later down the track (this was like a year and a half ago), thinking it would be similarly priced or even cheaper...
⤋ Read More
@eldersnake@we.loveprivacy.club
Steps to world domination:
- “Invent” “AI” (by using other people’s data).
- Get people hyped about it and ideally hooked on it.
- Only provide it as a cloud service. But hey, if you want to, you can run it locally!
- Buy all hardware available on the market, so that nobody but you can build more systems.
- All PCs of consumers and competitors are too weak now and can’t be upgraded anymore.
- Everybody depends on your cloud service! Win!
All of that is possible because corporations don’t have a “conscience” in capitalism. Nobody forces the RAM manufacturers to sell all their stuff to just one or two buyers, but since the only goal of that manufacturer is to make money, they do it.
↳
In-reply-to
»
The original twt is unavailable. It may have been edited or deleted, or is from an unknown or muted feed.
⤋ Read More
@shinyoukai@neko.laidback.moe I can’t believe Trace and Edgewall Software is still around and in use 🤣
On my way to having windows and mouse support:
https://movq.de/v/95bbbbd3e8/basic-windows.mp4
It would be cool to have something like Turbo Vision eventually.
(I considered just using Turbo Vision, but it’s a C++ library and that’s not quite what I’m looking for. But it’s not yet completely off the table.)
↳
In-reply-to
»
@lyse You actually have a Markdown parser/renderer in there? Oh dear. I would have been (well, I am) way too lazy for that. 😅
⤋ Read More
@movq@www.uninformativ.de Well, just a very limited subset thereof:
- inline and multiline code blocks using single/double/triple backticks (but no code blocks with just indentation)
- markdown links using using
[text](url)
- markdown media links using

And that’s it. No bold, italics, lists, quotes, headlines, etc.
Just like mentions, plain URLs, markdown links and markdown media URLs are highlighted and available in the URLs View. They’re also colored differently, similarly to code segments.
I definitely should write some documentation and provide screenshots.
Hurray, I finally fixed another rendering bug in tt that was bugging me for a long time. Previously, when there were empty lines in a markdown multiline code block, the background color of the code block had not been used for the empty lines. So, this then looked as if there were actually several code blocks instead of a single one.
![]()
mu (µ) now has builtin code formatting and linting tools, making µ far more useful and useable as a general purpose programming language. Mu now includes:
- An interpreter for quick “scriptinog”
- A native code compiler for building native executables (Darwin / macOS only for now)
- A builtin set of developer tools, currently: fmt (-fmt), check (-check) and test (-test).
↳
In-reply-to
»
The original twt is unavailable. It may have been edited or deleted, or is from an unknown or muted feed.
⤋ Read More
@shinyoukai@neko.laidback.moe Because you might not want to commit all changed files in a single commit. I very often make use of this and create several commits. In fact, I like to git add --patch to interactively select which parts of a file go in the next commit. This happens most likely when refactoring during a feature implementation or bug fix. I couldn’t live without that anymore. :-)
If you have a much more organized way of working where this does not come up, you can just git commit --all to include all changed files in the next commit without git adding them first. But new files still have to be git added manually once.
↳
In-reply-to
»
Hmm, mine also resolves a leading tilde in these variables. And if
⤋ Read More
$HOME is not specified it tries to resolve the user's home directory by user.Current().HomeDir. Maybe that's overkill, I have to check the XDG spec.
Ok, the standard library implementation is wonky at best, at least in regards to XDG, because it really doesn’t implement it properly. https://github.com/golang/go/issues/62382 I stick to my own code then. It doesn’t properly support anything else than Linux or Unixes that use XDG, but personally, I don’t care about them anyway. And the cross-platform situation is a giant mess. Unsurprisingly.
↳
In-reply-to
»
@lyse Well, I used SnipMate years ago (until 2012). IIRC, it’s more than just “insert a bit of text here”, it can also jump to the correct next location(s) and stuff like that. Don’t remember why I stopped using it.
⤋ Read More
@movq@www.uninformativ.de Thanks! I’ll have a look at SnipMate. Currently, I’m (mis)using the abbreviation mechanism to expand a code snippet inplace, e.g.
autocmd FileType go inoreab <buffer> testfunc func Test(t *testing.T) {<CR>}<ESC>k0wwi
or this monstrosity:
autocmd FileType go inoreab <buffer> tabletest for _, tt := range []struct {<CR> name string<CR><CR><BS>}{<CR> {<CR> name: "",<CR><BS>},<CR><BS>} {<CR> t.Run(tt.name, func(t *testing.T) {<CR><CR>})<CR><BS>}<ESC>9ki<TAB>
But this of course has the disadvantage that I still have to remove the last space or tab to trigger the expansion by hand again. It’s a bit annoying, but better than typing it out by hand.
↳
In-reply-to
»
Question to my fellow Vimers: Which snippet insertion mechanism are you using or can you (not) recommend?
⤋ Read More
@lyse@lyse.isobeef.org Well, I used SnipMate years ago (until 2012). IIRC, it’s more than just “insert a bit of text here”, it can also jump to the correct next location(s) and stuff like that. Don’t remember why I stopped using it.
Then I used nothing for a long time. Just before Christmas, I made my own plugin (… of course …), which does everything I need at the moment (and nothing more).
It can insert simple templates and then jump to the next location:
https://movq.de/v/67cdf7c827/sisni%2Dpython.mp4
And replace a string after insertion:
https://movq.de/v/67cdf7c827/sisni%2Dheader.mp4
(It’s not public (yet?) and it also uses vim9script, so I guess it wouldn’t work on your system.)
Question to my fellow Vimers: Which snippet insertion mechanism are you using or can you (not) recommend?
↳
In-reply-to
»
The
⤋ Read More
tt URLs View now automatically selects the first URL that I probably are going to open. In decreasing order, the URL types are:
@lyse@lyse.isobeef.org That sounds useful. 🤔
↳
In-reply-to
»
@lyse Yeah I remember you said some days back that your interest in compilers was rekindled by my work on mu (µ) 😅
⤋ Read More
@lyse@lyse.isobeef.org I can tell you this right now, writing assembly / machine code is fucking hard work™ 😓 I’m sure @movq@www.uninformativ.de can affirm 🤣 And when it all goes to shit™ (which it does often), man is debugging fucking hard as hell! Without debug symbols I can’t use the regular tools like lldb or gdb 😂
↳
In-reply-to
»
Whoo! I fixed one of the hardest bugs in mu (µ) I think I've had to figure out. Took me several days in fact to figure it out. The basic problem was,
⤋ Read More
println(1, 2) was bring printed as 1 2 in the bytecode VM and 1 nil when natively compiled to machine code on macOS. In the end it turned out the machine code being generated / emitted meant that the list pointers for the rest... of the variadic arguments was being slot into a register that was being clobbered by the mu_retain and mu_release calls and effectively getting freed up on first use by the RC (reference counting) garbage collector 🤦♂️
@prologic@twtxt.net Tada, congratulations! I find that rather interesting, thanks for telling us. :-)
Whoo! I fixed one of the hardest bugs in mu (µ) I think I’ve had to figure out. Took me several days in fact to figure it out. The basic problem was, println(1, 2) was bring printed as 1 2 in the bytecode VM and 1 nil when natively compiled to machine code on macOS. In the end it turned out the machine code being generated / emitted meant that the list pointers for the rest... of the variadic arguments was being slot into a register that was being clobbered by the mu_retain and mu_release calls and effectively getting freed up on first use by the RC (reference counting) garbage collector 🤦♂️
↳
In-reply-to
»
@lyse while caching those is a good idea the problem is baking data that can be calculated into the database instead of some cache, because post hashes are not fixed and change for every post edit. you can always easily look up other twts by hash with a cached lookup table, but now you're not locked into them so supporting hashv2 or other hash variants or any other solution becomes far easier
⤋ Read More
@zvava@twtxt.net By hashing definition, if you edit your message, it simply becomes a new message. It’s just not the same message anymore. At least from a technical point of view. As a human, personally I disagree, but that’s what I’m stuck with. There’s no reliable way to detect and “correct” for that.
Storing the hash in your database doesn’t prevent you from switching to another hashing implementation later on. As of now, message creation timestamps earlier than some magical point in time use twt hash v1, messages on or after that magical timestamp use twt hash v2. So, a message either has a v1 or a v2 hash, but not both. At least one of them is never meaningful.
Once you “upgrade” your database schema, you can check for stored messages from the future which should have been hashed using v2, but were actually v1-hashed and simply fix them.
If there will ever be another addressing scheme, you could reuse the existing hash column if it supersedes the v1/v2 hashes. Otherwise, a new column might be useful, or perhaps no column at all (looking at location-based addressing or how it was called). The old v1/v2 hashes are still needed for all past conversation trees.
In my opinion, always recalculating the hashes is a big waste of time and energy. But if it serves you well, then go for it.
↳
In-reply-to
»
Hmmm I need to figure out a way to reduce the no. of lines of code / complexity of the ARM64 native code emitter for mu (µ). It's insane really, it's a whopping ~6k SLOC, the next biggest source file is the compiler at only ~800 SLOC 🤔
⤋ Read More
The compiler technique I’m using here is to not “emit” most of the runtime if it’s actually never used in your program, and also dropping dead code in the SSA pass.
My little toy operating system from last year runs in 16-bit Real Mode (like DOS). Since I’ve recently figured out how to switch to 64-bit Long Mode right after BIOS boot, I now have a little program that performs this switch on my toy OS. It will load and run any x86-64 program, assuming it’s freestanding, a flat binary, and small enough (< 128 KiB code, only uses the first 2 MiB of memory).
Here I’m running a little C program (compiled using normal GCC, no Watcom trickery):
https://movq.de/v/b27ced6dcb/los86%2D64.mp4
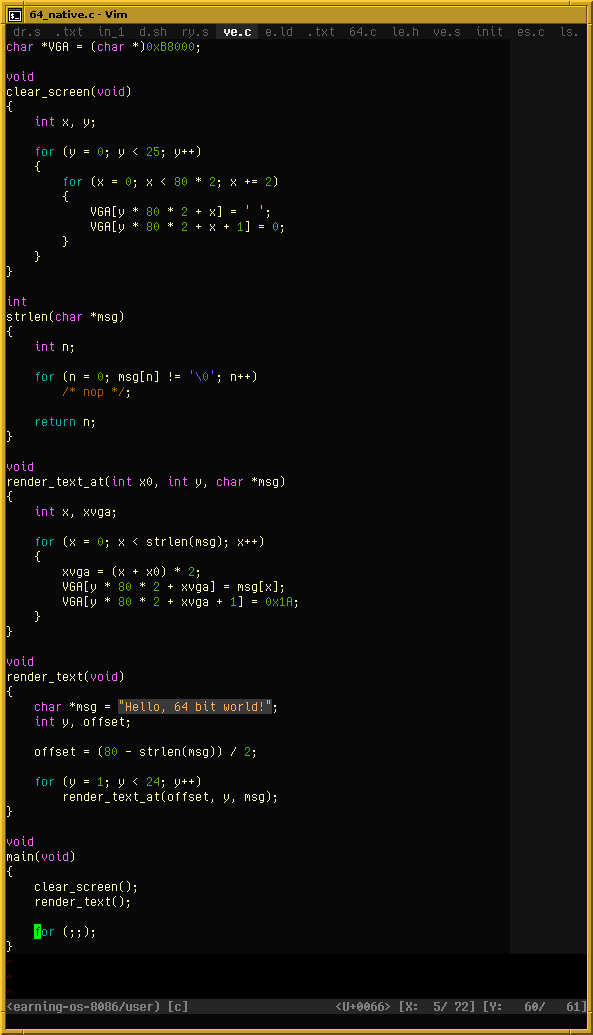
Next steps could include:
- Use Rust instead of C for that 64-bit program?
- Provide interrupt service routines. (At the moment, it just keeps interrupts disabled.)
↳
In-reply-to
»
This one is a slightly more 3D looking, as well as the first one, with the tail swirled.
Media
⤋ Read More
@thecanine@twtxt.net Is it because you’ve used white pixels around it to sort of give it aht 3D look? 👀 Hmm? 🤔
2025 end the year rewind:
Compared to only 3 new artworks in 2024 and next to no work, on other projects, this year I not only met the self-imposed goal of monthly pixelart, but exceeded it by 50%, with 18 additions in total.
Relicensed the majority of canine faction owned art and projects, under two less restrictive Creative Commons licensees*. This also applies retroactively, to everyone who used/archived our art and projects, back when the old license didn’t allow it.
Disappointed by the current state of the Internet and continued lack of competition among browsers, completely reworked the main website* and made Smol Drive** (a new image gallery project), both made to be compatible with as many web and Gemini browsers, as possible.
*see https://thecanine.smol.pub
**see https://thecanine.smol.pub/smolbox
↳
In-reply-to
»
This feels useful: Rust’s Block Pattern
⤋ Read More
@movq@www.uninformativ.de Very nice! I often wish other languages had something similar. Sometimes, I use lambdas, but that also looks ugly and feels a bit like a misuse. Other times, just the normal blocks are enough, but it’s not the same. Especially with the mutability aspects as the article explains. Typically, I just put it in a function or ignore it if it’s just a few lines.
This feels useful: Rust’s Block Pattern
↳
In-reply-to
»
Wow, @movq, so many tables. No idea what I expected (I'm totally clueless on this low-level stuff), but that was quite an interesting surprise to me. https://www.uninformativ.de/blog/postings/2025-12-21/0/POSTING-en.html
⤋ Read More
@lyse@lyse.isobeef.org I was surprised by that as well. 😅 I thought these were features that you can use, but no, you must do all this.
By the way, I now fixed the issue that I mentioned at the end and it works on the netbook now. 🥳

I’m using Debian minimal, a UNIX-like operating system with xorg and Openbox installed, as well as the Konqueror web browser. Google claims I’m a robot. You probably want to say that it’s not mandatory to use Google services, and you’re right.
↳
In-reply-to
»
@movq wow! what is assembler?
⤋ Read More
@kiwu@twtxt.net Assembly is usually the most low-level programming language that you can get. Typical programming languages like Python or Go are a thick layer of abstraction over what the CPU actually does, but with Assembler you get to see it all and you get full control. (With lots of caveats and footnotes. 😅)
I’m interested in the boot process, i.e. what exactly happens when you turn on your computer. In that area, using Assembler is a must, because you really need that fine-grained control here.
↳
In-reply-to
»
H… Ho… How have I not heard about vim-tagbar before? 😳
⤋ Read More
@lyse@lyse.isobeef.org Yeah, well, given that I didn’t need this for such a long time, it’s probably not an essential tool. 😅
I’ve often wanted to have an outline of text documents, though, and tagbar/ctags can do that as well:
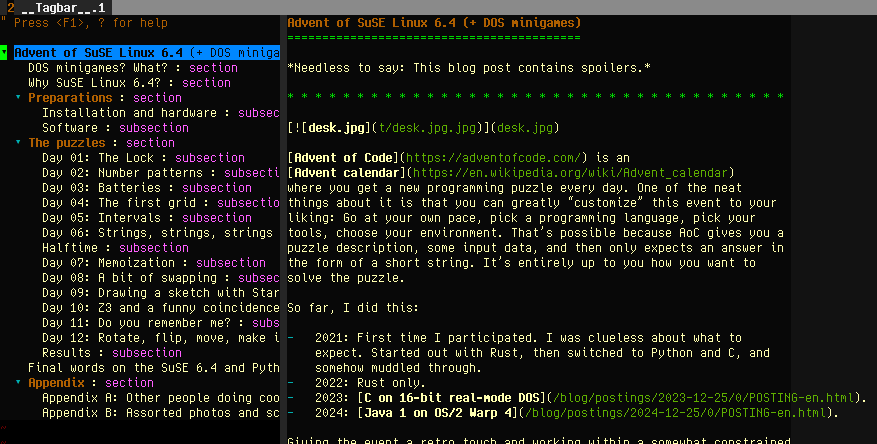
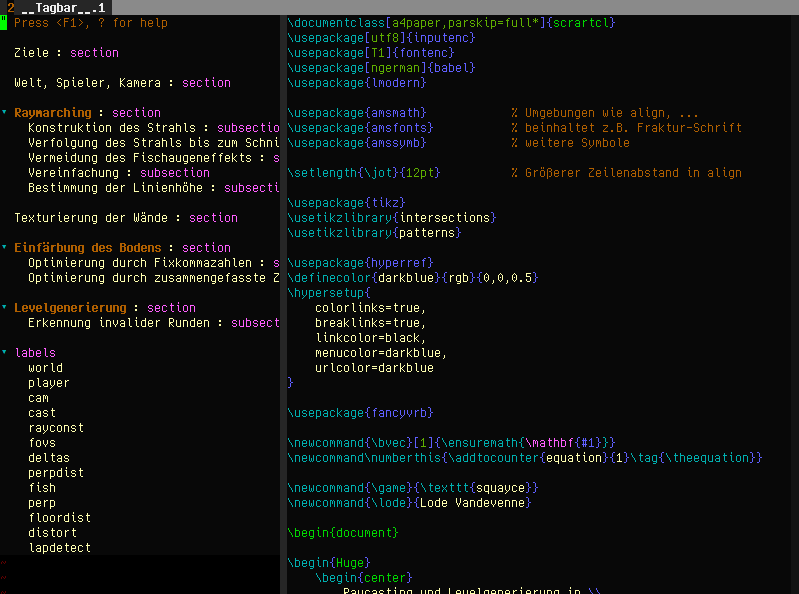
This isn’t as powerful as the “Navigator” tool in StarOffice/LibreOffice (which can be used to rearrange the document), but still pretty useful:
https://www.uninformativ.de/blog/postings/2024-05-23/0/so31.mp4
↳
In-reply-to
»
H… Ho… How have I not heard about vim-tagbar before? 😳
⤋ Read More
@movq@www.uninformativ.de Interesting. I never found a big use for these kind of lists in general. But I might give it a shot again.
If your very popular project with lots of stars on GitHub is over 10 years old, and you’re still at a pre-1.0 version because you’re using SemVer and a 1.0 would mean making some kind of commitment and that’s somehow not desirable for you, then I think you’re doing something wrong. 🤔
Wasn’t expecting it to work because my previous attempts didn’t. Using lynx on the terminal on my raspberyy pi, and navigating here took so long. So did sending these messages, and now I have to go.
Bro i used to love ubuntu soo much they lost me when I found out that canonical’s (or whatever the company’s name is) C-tier hired a proud surveillance advocate
↳
In-reply-to
»
The original twt is unavailable. It may have been edited or deleted, or is from an unknown or muted feed.
⤋ Read More
@shinyoukai@neko.laidback.moe it was a mess, we are better without it. Until a new mobile client comes (not holding my breath), Yarn is very usable on the mobile, just using the browser.
↳
In-reply-to
»
Use more WebP, I guess.
⤋ Read More
Webp, though it has been around for a long while, wasn’t fully supported on all browsers until recently. The other formats have been in use for such a long time, proving to work just fine, that the advantages Webp provides haven’t been seemingly enough to merit a switch.
Google is also the one behind Webp, and, well, people don’t trust, nor like, them much.