↳
In-reply-to
»
For this week's (slightly delayed) #caturday post, we catch Bowie as he contemplates whether to play Arkham City (again).
⤋ Read More
@itsericwoodward@itsericwoodward.com (I still hate that these photos look so good, despite being made with a telephone. 😝 I mean, the (probably built-in) filters are easy to spot, but it looks super convincing when you don’t pay attention.)
/https://baldo.cat/media/photos/IMG_9199.jpeg)
/https://baldo.cat/media/photos/IMG_9182.jpeg)
↳
In-reply-to
»
Oh boy, I absolutely hate this stupid trend of not writing changelogs anymore! Why the fuck would one seriously consider it to be a viable option to just let some shitty bot spew all merge requests on a goddamn GitHub release?! First of all, these merge request titles suck balls. The order of the changes in this "changelog" is completely random (well, probably merge time, which is as useless as the dick on the Pope). They are not grouped by anything at all. Additions, changes, removals, deprecations, etc. randomly mixed up in one giant list. And then "Add feature X", seventeen kilometers further down "Revert 'Add feature X'". Fuck you! Don't include this shit in the first place!
⤋ Read More
@movq@www.uninformativ.de Hahaha, great timing! :-D I love your article and agree with almost all your points.
On the AI changelog part, though, I’d rather recommend to just not have a changelog at all.
Another important thing for me is the deprecation notice section. What do I need to look out for in the future? Should I start to migrate to another API soon? Even right now? Or does it have time?
While going through these terrible GitHub release pages, I also found these “New Project Contributors” sections (yeah, for that, they found the time to make a section) annoying. Don’t get me wrong, sure, credit where credit is due. But come on. Soooooo much space for an inefficiently formatted (and also unsorted) list. At least it was easy enough to skip over it.
And then, there are also these changelogs or rather notice documents in general that are infested with multicolored emojis all over the place. My brain’s spam filter kicks in and shoves everything to /dev/null immediately. It’s especially a thing at work.
In my previous work project, we also used the Keep A Changelog Format. That was great. You wouldn’t believe how often I resorted back to that document. At least twice a week, often several times a day. I was very glad that we put in this effort. Of course, writing the changelog took its time, but it was worth every minute and more. Reading a many months old item, it was immediately clear. I was our best customer in that regard.
Now, it’s just the same auto shitshow with MR titles in a rolling date-versioned release scheme. It’s just our team who has to deal with that, though. I think I’m the only one who is not a fan of it.
↳
In-reply-to
»
Apologies to anyone who's seen an uptick in twtxt pings from me today... I've been working on shoe-horning my twtxt reader (TwtStrm) into my editor (TwtKpr, aka the
⤋ Read More
express-twtkpr npm library), and it kind ran amok a few times. So again, sorry - I've added a minimum 10-minute cool-down period between pulls which should help (I hope 🙂).
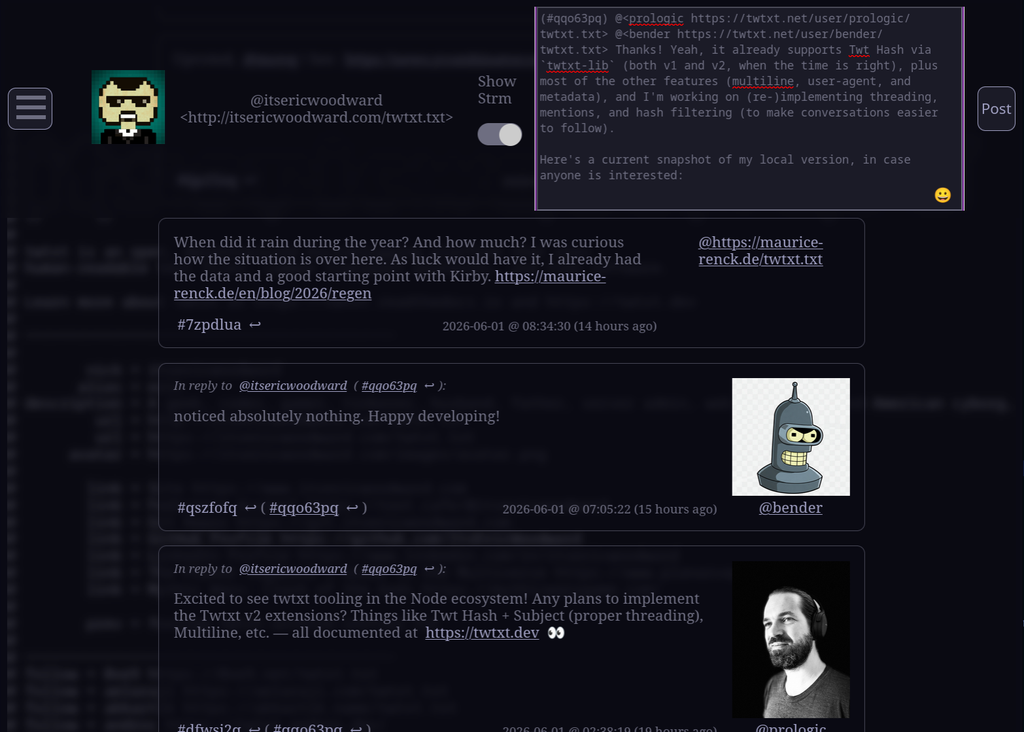
@prologic@twtxt.net @bender@twtxt.net Thanks! Yeah, it already supports Twt Hash via twtxt-lib (both v1 and v2, when the time is right), plus most of the other features (multiline, user-agent, and metadata), and I’m working on (re-)implementing threading, mentions, and hash filtering (to make conversations easier to follow).
Here’s a current snapshot of my local version, in case anyone is interested:
/https://baldo.cat/media/photos/IMG_8961.jpeg)
/https://baldo.cat/media/photos/IMG_8923.jpeg)
-¡Nadie me quiere dar mimos!-
/https://baldo.cat/media/photos/IMG_8814.jpeg) #catsoftwtxt
#catsoftwtxt
/https://baldo.cat/media/photos/IMG_8624.jpeg)
↳
In-reply-to
»
Fuck me dead, our sky burned down once again! https://lyse.isobeef.org/abendhimmel-2026-04-28/
⤋ Read More
@prologic@twtxt.net @movq@www.uninformativ.de @bender@twtxt.net Thank you very much! <3
I only filtered out the noise floor of the camera itself. I selected one second of “silence” in Audacity and used the “Effect” → “Noise reduction” (Rausch-Verminderung in German) dialog with its default settings. I repeated that two or three times in total with different sections of “silence”. It’s very hard to find something where there is really no other bird singing in the background. But in contrast to the original audio, the edited version is noticeably more squeaky I find.
Oh, and I increased the volume. Especially after the noise reduction, everything is a bit quieter.
I got rather lucky, only a few cars went by and my microphone is too shitty, to really pick it up. :-D It’s kinda drowned out by the background noise. 45 seconds into the video, a car passes. Also at 1:10 without a doubt. I’m sure there were actually many were. Most of them passed behind me, the mic is facing away from that sound source. Of course, the densely built-up area still reflects a lot.
It also helped that Azabache is a loud singer himself. Fortunately, no idiots screaming either.
If you want to compare yourself or play around to see what other improvements you are able to achieve, I uploaded the original from the camera in the same directory under the lovely name DSCN5687.MOV. It’s 236.1 MiB in size.
↳
In-reply-to
»
Fuck me dead, our sky burned down once again! https://lyse.isobeef.org/abendhimmel-2026-04-28/
⤋ Read More
@lyse@lyse.isobeef.org Omg, that’s quiet. Did you do some filtering on this? No traffic noise? No drunk men shouting? 😳
↳
In-reply-to
»
@lyse Those are some very colorful shots. 👌 It was pretty warm here as well, health issues prevented me from going out, though.
⤋ Read More
Thanks, @movq@www.uninformativ.de! Oh no, get well, mate!
Yes, our singer is a male I’m pretty sure. Of course, it’s hard to tell after sunset whether our blackbird wears a black or brown feather coat, but during daylight I’ve always only seen black ones sit on this roof ridge. It appears that Wikipedia is backing this up a little bit: https://de.wikipedia.org/wiki/Amsel#Reviergesang
I just added a video. Hmm, filtering the background camera noise also makes the audio rather squeaky. :-(
¡Hoy cumplo 2 añitos!
/https://baldo.cat/media/photos/IMG_8111.jpeg) #catsoftwtxt
#catsoftwtxt
Cat-ólico
/https://baldo.cat/media/photos/IMG_8175.jpeg) #catsoftwtxt
#catsoftwtxt
-¿Qué viene quién y cuándo?-
/https://baldo.cat/media/photos/IMG_7910.jpeg) #catsoftwtxt
#catsoftwtxt
/https://baldo.cat/media/photos/IMG_7872.jpeg)
/https://baldo.cat/media/photos/final.jpeg)
Solo tú y yo, por siempre
/https://baldo.cat/media/photos/IMG_7130.jpeg) #catsoftwtxt
#catsoftwtxt
↳
In-reply-to
»
The original twt is unavailable. It may have been edited or deleted, or is from an unknown or muted feed.
⤋ Read More
@shinyoukai@neko.laidback.moe Do we now need ad filters in twtxt clients, too? O_o I hope not! Personally, I cannot stand the “Sent with my crappy $phone/$app” e-mail footers.
But congrats on your client. :-)
there’s something very soothing in spreadsheets to compute filters parts values and frequencies #electronics
/https://baldo.cat/media/photos/IMG_6983.jpeg)
↳
In-reply-to
»
Working on day 3 of the Advent of Code 2025: https://adventofcode.com/
⤋ Read More
@itsericwoodward@itsericwoodward.com Nice to see someone else also participating! 🥳
(Btw, they don’t want us to share our inputs: https://www.reddit.com/r/adventofcode/wiki/faqs/copyright/inputs/ Yeah, it’s a bit annoying. I also have to do quite a bit of filtering on my repo …)
CatGPT
/https://baldo.cat/media/photos/IMG_6793.jpeg) #catsoftwtxt
#catsoftwtxt
/https://baldo.cat/media/photos/IMG_6779.jpeg)
Anyone on my pod (twtxt.net) finding the new Filter(s) useful at all? 🤔 
First Dates: Baldo. 2 años. «Ronronea conmigo durante toda la noche.»
/https://baldo.cat/media/photos/1124A147-0140-4BCB-B764-12FCDE93E535.jpeg) #catsoftwtxt
#catsoftwtxt
Diferencia entre gato poralizado y no polarizado
/https://baldo.cat/media/photos/IMG_6629.jpeg) #catsoftwtxt
#catsoftwtxt
-Yo no estoy en peligro, Skyler. Yo soy el peligro. Un sanguinario depredador se abalanza sobre un lindo minino, ¿y tú crees que ese soy yo? No. ¡Yo soy el que salta!-
/https://baldo.cat/media/photos/IMG_6519.jpeg) #catsoftwtxt
#catsoftwtxt
Soñando que vence a Scar
/https://baldo.cat/media/photos/IMG_6469.jpeg) #catsoftwtxt
#catsoftwtxt
↳
In-reply-to
»
I just successfully used my own SnipMail service with a real business, whoohoo! 🥳
⤋ Read More
@prologic@twtxt.net @movq@www.uninformativ.de Same here, I give each service a dedicated e-mail address. It’s very interesting to see how e-mail addresses are transferred to other actors. Luckily, this only happens rarely. But it does happen. In surprising ways.
Aliases not only help to fight spam, but are also a great way to specify filter rules to sort e-mails.
/https://baldo.cat/media/photos/IMG_6356.jpeg)
-¿Y… sueles acurrucarte mucho por aquí?-
/https://baldo.cat/media/photos/IMG_6259.jpeg) #catsoftwtxt
#catsoftwtxt
Disfraz de Halloween 🎃 : ojos flotantes
/https://baldo.cat/media/photos/IMG_6287.jpeg) #catsoftwtxt
#catsoftwtxt
¡Feliz Halloween 🎃 🧛!
/https://baldo.cat/media/photos/IMG_5964.jpeg) #catsoftwtxt
#catsoftwtxt
Color negro brillante e irresistible.
/https://baldo.cat/media/photos/IMG_5888.jpeg) #catsoftwtxt
#catsoftwtxt
- ¿Te gusta el nuevo pienso? Es bajo en calorías. -
/https://baldo.cat/media/photos/IMG_5864.jpeg) #catsoftwtxt
#catsoftwtxt
Evitando que mi humano trabaje para darme mimitos.
/https://baldo.cat/media/photos/IMG_4889.jpeg) #catsoftwtxt
#catsoftwtxt
Soy el detective Baldo. Aún recuerdo cuando esa gatita salvaje entró en mi caja contoneando su cola. Le habían robado el cascabel de oro. Acepté el caso sin dudarlo, quería meter los bigotes en ese caso. Olía a pescado podrido.
/https://baldo.cat/media/photos/IMG_5286.jpeg) #catsoftwtxt
#catsoftwtxt
-¡Deja de estudiar y hazme caso!-
/https://baldo.cat/media/photos/IMG_5283.jpeg) #catsoftwtxt
#catsoftwtxt
/https://baldo.cat/media/photos/IMG_5230.jpeg)
I have a Python script that transforms the original YouTube channel Atom feed into a more useful Atom feed by removing the spam description and replacing it with the video duration, filtering out videos by title, duration, etc. I just updated it to exclude the damn Shorts garbage more efficiently. Finally, YouTube updated their Atom feed generation, so that the video URL contains /short/ if it’s of this useless kind. Never thought that they ever actually will improve their Atom feeds. Thank you, much appreciated!
-Me gusta mi nueva cestita-
/https://baldo.cat/media/photos/IMG_5136.jpeg) #catsoftwtxt
#catsoftwtxt
Se ha ido la colonia que había fuera y el “jefe” que me pegaba. ¡Ya puedo subir otra vez!
/https://baldo.cat/media/photos/IMG_5067.jpeg) #catsoftwtxt
#catsoftwtxt
Yin-cat
/https://baldo.cat/media/photos/IMG_4996.jpeg) #catsoftwtxt
#catsoftwtxt
Mejorando sus técnicas de camuflaje para cazar moscas
/https://baldo.cat/media/photos/IMG_4857.jpeg) #catsoftwtxt
#catsoftwtxt
Fresquito
/https://baldo.cat/media/photos/IMG_4747.jpeg) #catsoftwtxt
#catsoftwtxt
Batdo
/https://baldo.cat/media/photos/batdo.jpg) #catsoftwtxt
#catsoftwtxt
- Esta almohada me gusta. ¡Pa mi! -
/https://baldo.cat/media/photos/IMG_4714.jpeg) #catsoftwtxt
#catsoftwtxt
Meh, the stupid shorts get longer. I need to increase my duration filter in order to ban all this garbage.
Las 50 sombras de Baldo
/https://baldo.cat/media/photos/IMG_4673.jpeg) #catsoftwtxt
#catsoftwtxt