@prologic@twtxt.net For what it’s worth, the twt hash extension is specifically modeled after yarnd’s implementation with all the quirks coming from Go’s stdlib: https://twtxt.dev/exts/twt-hash.html#timestamp-format
“All timezones representing UTC must be formatted using the designated Zulu indicator Z rather than the numeric offsets +00:00 or -00:00. If the timestamp does not explicitly include any timezone information, it must be assumed to be in UTC.”
Hello everyone ! 👋 Behold I bring you (after many years) the launch of the Twtxt App 😅 – Ye, this is a Desktop and Mobile app built as a Progressive Web App (PWA) using a little framework (Swag) I put together iafter some experiments @xuu@txt.sour.is and I did in Go and HTMX and Service Workers.
The App is offline-first and supports installing to Desktop and Mobile (add to Home screen) and supports a number of publishing backends, including Yarn.social’s yarnd Pod, Github, Codeberg/Gitea, and a little tiny twtd Twtxt server (See: https://git.mills.io/yarnsocial/twtd).
Please try it out, no need for any account(s) or such, works with your existing feed(s) (as long as the publishing backends work well enough for you!). Please give me feedback! 🙏
Also, did you know the Twtxt Search Engine is back? 🎉
This is a neat tool for comparing several public DNS resolvers (some of which were new to me) on various criteria; includes a speed test. https://evilbit.de/dns-resolver-guide.html
↳
In-reply-to
»
Finally finished another meme one, I always wanted. It took forever, to get it right, so I really hope people get the reference.
Media
⤋ Read More
@lyse@lyse.isobeef.org Thanks! You had one of the strangest guesses so far, first one I had to look up. 😄 It is a reference to a (human) cop/detective, from a 2019 videogame. Since there’s no spoilers tag on Twtxt, the name of the file on my site, includes the correct answer.
↳
In-reply-to
»
I complain about this a lot:
⤋ Read More
@movq@www.uninformativ.de Oooph! Web development is tidious.
I also include width and height from now on in my galleries.
↳
In-reply-to
»
Numbered headings in blog posts, yay or nay?
⤋ Read More
@movq@www.uninformativ.de I reckon section numbers are not really needed for articles. But if you number them, the anchors should probably not contain the section number, just the title. Especially for articles that may receive updates.
It’s probably another story for specifications. They’re kinda fixed and thus I found it useful in the past to include the section numbers in the anchors, so they show up in URLs when linking to specific sections. W3C RFCs only include the numbering in the anchors. This makes URLs fairly short, but it would be also nice to directly see what kind of section that URL actually links to.
↳
In-reply-to
»
@movq Yeah, that would also be fine with me. I certainly do like the "arbitrary" in your comment.
⤋ Read More
I now decided to include the alternatives: https://lyse.isobeef.org/code-readability/#alternative-timestamp-formattings
So I’ve been working on GoNIX the last few days… Which is derived from µLinux – At least it’s entire build process. GoNIX however has a 100% Go userland, including the init process, package and service management.
Now… As an experiment, because I was able to make much process on enhancing the build tools and package management, I decided to see if I could build a “Desktop” Gui of sorts…
I still wanted it to be fairly minimal and lightweight. So I went with wayland (of course) and labwc and yambar. So far I’m liking the result 👌 42 packages in the wayland-desktop meta port. Not too bad. Not sure if I can slim that down anymore… But trying to avoid Mesa/GL as that drags in far too much “cruft”.
balloon added a twtxt central page, including a timeline.
Nightfall Shore resident balloon has been doing a lot of work improving the district! balloon added a twtxt central page, including a timeline.
↳
In-reply-to
»
Oh boy, I absolutely hate this stupid trend of not writing changelogs anymore! Why the fuck would one seriously consider it to be a viable option to just let some shitty bot spew all merge requests on a goddamn GitHub release?! First of all, these merge request titles suck balls. The order of the changes in this "changelog" is completely random (well, probably merge time, which is as useless as the dick on the Pope). They are not grouped by anything at all. Additions, changes, removals, deprecations, etc. randomly mixed up in one giant list. And then "Add feature X", seventeen kilometers further down "Revert 'Add feature X'". Fuck you! Don't include this shit in the first place!
⤋ Read More
@movq@www.uninformativ.de I just ran across another thing. At least I personally couldn’t care less about CI infrastructure changes. Whether they’re using github action a or b or c or version v or w, it is not of my interest. At all. (It might be useful to estimate the supply chain attack risk, though.) If the maintainers want to include them in the changelog – and there are probably people to whom this information is crucial – it’s probably best to document CI infrastructure changes in their own section.
↳
In-reply-to
»
Oh boy, I absolutely hate this stupid trend of not writing changelogs anymore! Why the fuck would one seriously consider it to be a viable option to just let some shitty bot spew all merge requests on a goddamn GitHub release?! First of all, these merge request titles suck balls. The order of the changes in this "changelog" is completely random (well, probably merge time, which is as useless as the dick on the Pope). They are not grouped by anything at all. Additions, changes, removals, deprecations, etc. randomly mixed up in one giant list. And then "Add feature X", seventeen kilometers further down "Revert 'Add feature X'". Fuck you! Don't include this shit in the first place!
⤋ Read More
@movq@www.uninformativ.de You may want to include another antipattern to avoid in your article:
- bump $same_dependency from 1.0.0 to 1.0.1
- bump $same_dependency from 1.0.1 to 1.0.2
- bump $same_dependency from 1.0.2 to 1.1.0
- bump $same_dependency from 1.1.0 to 1.2.0
Oh boy, I absolutely hate this stupid trend of not writing changelogs anymore! Why the fuck would one seriously consider it to be a viable option to just let some shitty bot spew all merge requests on a goddamn GitHub release?! First of all, these merge request titles suck balls. The order of the changes in this “changelog” is completely random (well, probably merge time, which is as useless as the dick on the Pope). They are not grouped by anything at all. Additions, changes, removals, deprecations, etc. randomly mixed up in one giant list. And then “Add feature X”, seventeen kilometers further down “Revert ‘Add feature X’”. Fuck you! Don’t include this shit in the first place!
Fits absolutely perfect in the pattern of rapid decline.
I must rip out all dependencies as soon as possible whose maintainers just don’t give a shit.
I was just about to stop my feature freeze and include standard.site in the IndieConnector. Almost.https://maurice-renck.de/en/blog/2026/indieconnector-and-standard-site
↳
In-reply-to
»
@lyse Ah, I almost thought so (that you wrote it by hand), but then I looked at the source code and saw the TOC and I was like: “Naah, probably not. I would be way too lazy to do that manually.” 😅 And indeed … ha.
⤋ Read More
@lyse@lyse.isobeef.org Switching to Make might be a good idea, though, because the whole thing is purely sequential at the moment … It takes close to 20 seconds (including the w3c verification which runs the Java checker). It’s not unusable, but it could be better. 😅
↳
In-reply-to
»
@movq Thanks. I noticed the
⤋ Read More
<updated> of the feed, too. But for some reason, some articles were suddenly marked as new.
Aha, yesterday’s newly added support for LC_TIME to render localized timestamps also broke the feed parsing with my LANG=de_DE.UTF-8 and LC_CTYPE=de_DE.UTF-8 environment. :-)
Atom feeds make use of RFC 3339 timestamps. They are first converted into RFC 882 timestamp representation, which is the one that RSS feeds use. However, this conversion now results in localized RFC 882 timestamps, which cannot be parsed into Unix timestamp numbers via curl_getdate(…). I bet that it doesn’t know about the localization at all and expects English month and weekday names. Looking at its docs, I reckon that function was selected because of its myriad of supported timestamp formats: https://curl.se/libcurl/c/curl_getdate.html RFC 3339 is not included, though, hence the transformation up front.
The intermediate Item objects in the parser domain use std::string for the timestamp representation. This isn’t all that silly, because Newsboat supports all sorts of different feed formats with different timestamp formats. These RFC 883 timestamps are centrally parsed into time_t.
Speaking of time: It’s time to go to bed after this late bug hunting fun. :-)
↳
In-reply-to
»
@lyse (Do you want to be linked on that page? Do you want your name to be there at all? 🤔)
⤋ Read More
@movq@www.uninformativ.de I really like your style of writing, btw. It’s much calmer and less aggressive then mine. :-) When I turned my bullet points into paragraphs, I got a bit mad in the process.
Sure, feel free to include anything you want. Regarding citing, this is where twtxt falls short in my opinion. Especially with feed rotation, classic links die quickly. Message hashes only help so much. Nobody outside the twtxt universe knows how to deal with them. So, not perfect for inclusion on a web page. Linking to a thread or message on some yarnd instance might be the more user-friendly option. But the disadvantage is that it’s “just” a mirror, not the primary or original source. In all reality, this could be considered splitting hairs, though.
I should have probably written a proper article. That would have given me time to review the result more carefully, too. ;-) Perhaps that’s something for the future. But honestly, I’m not sure if I really want to waste my time and energy on that subject. So many other fun or useless things come to mind right away that I could do instead. 8-)
So, yeah, do whatever feels best to you. I don’t mind being cited or linked, but I also don’t mind not to be cited or not to be linked to. :-D Not a helpful answer, I know. Sorry. ;-) But anyway, thanks for asking, mate! I do appreciate it.
To finish my thought, linking to my frontpage is probably also useless, since I deliberatly do not have a table of contents there. In fact, my entire frontpage is rather silly.
↳
In-reply-to
»
I’ve started collecting reasons against AI usage here, so I don’t have to repeat myself all the time:
⤋ Read More
Of course, @movq@www.uninformativ.de! Most of my points are also included in your list.
First of all, programming is what I really do enjoy the most. So, it doesn’t make any sense at all to not do this anymore. “But you could use your now free time to do something much cooler and more valuable!”, others might reply. Fuck no, I don’t want to waste my time with other shit that doesn’t fulfill me, why on earth would I want to do that?
All this hallucination reduces quality badly. In my experience, it’s also happening much more rapidly than I expected. Even though developers are still supposed to own and understand whatever has been generated under their name and even be responsible for that, the sad reality is that teammates often blindly trust the AI output. “But I asked the AI and it told me that $this was impossible”, “I’ve no idea either, but the AI just generated it” are responses I get more often. What really makes my angry is when I point out a flaw and suggest an alternative and this is the reaction. It happened several times that just trying it out and seeing it clearly work to proof my point only took me half a minute, but people still did something handwavy else instead.
The learning effect is drastically reduced. The more time I spend on a topic, the better the odds that whatever I learned actually makes it over into long-term memory. It’s like if a collegue just says “do it like that” or “this solves your problem”, but neither explains the why or how. Somehow, people are still convinced that it’s a completely different story when you replace the human counterpart with a computer program in this equation.
Skills are unlearned. It’s like with automation in general, just much worse. You end up in a state where you’ve no clue how anything works under the hood or how to actually find out important information that are needed to solve your problem. You’re screwed when a process breaks out of the blue. Even though it can become also rather terrible, with classical automation you’re typically still be able to decipher how exactly the thing was supposed to do something.
The energy consumption is sooo high, I absolutely do not want to be a part in burning down our planet. I’m sure I find (and probably have long found without knowing) other ways to contribute to worsen our climate crisis.
The scraper part is already covered in detail in your list. :-)
I’m convinced that license and copyright violations are only played down or even refused entirely because companies want to make big money quickly. With the work of others of course. Their double standards are obvious, they still try to actively keep their own stuff secret and out of any training sets. At most for internal use only. Virtually noone in charge is interested in good long-term solutions. Short-term for the win, when disaster eventually strikes, the causers are long gone, the responsibilities in other hands.
Vendor lock-in is something that lots of folks are only realizing very slowly. It’s completely crazy to me. This drug dealer routine should be well-known by now. It’s fucking everywhere. Yet, people are always surprised when they found themselves caught in it.
Adding new AI stuff only increases complexity. But complexity is the enemy that everybody should fear and reduce as much as possible. Of course, this is not limited to AI at all. And everywhere I look around, people in charge looooove to make things way more complicated than they ever need to be. Yet, simplicity is the real art and much harder to achieve.
I don’t understand why we have to go back full force to the ambiguity of natural languages. This alone should be more than enough to realize what a stupid idea all that is. Linked to that is that the “instruction set” is interpreted differently with newer model versions. I mean, is has to be. Why else would somebody want to upgrade in the first place than to get more Powerful™ Features™?
Some people argue that with AI the democratization is empowered. However, in my view, the exact opposite is the case. Models are getting so large that you can basically not run them locally or even train them. So, you have to rely on whatever the vendor offers you and runs for you. In the end, this only gives the owners more power, the multi billionaires. Not exactly what I understand by democratization.
Finally, technology assessments are missing completely. Or they are faked such that mostly only the (questionable) benefits are listed. But all the negative impact is just ignored.
Let’s keep some popcorn around for when this all explodes. :-)
I’m pleased to announce that express-twtkpr (my ExpressJS library for hosting, editing, and posting to a twtxt.txt file) continues to crawl towards a full release with another (pre-alpha) update published to NPM. This update includes a whole new plugin system, and even a (little) more documentation. Check it out, if you dare (and use it at your own risk): https://www.npmjs.com/package/express-twtkpr
And speaking of plugins, here’s where the fun’s at: announcing express-twtkpr-core-plugins, a set of 3 plugins for your TwtKpr install: emojiButton, uploadButton, and postToMastodon. Like express-twtkpr, this set of plugins is still in pre-alpha, and lacks documentation, examples, tests, installation flexibility, or polish (so also use them at your own risk). Other than that, they work great: https://www.npmjs.com/package/express-twtkpr-core-plugins
https://itsericwoodward.com/images/bba54e39.png
https://itsericwoodward.com/images/e472ea48.png
https://itsericwoodward.com/images/65b23473.png
{kind=link}
{kind=link}
{kind=link}
Stay tuned for more! 🤘
↳
In-reply-to
»
been a while, what's everyone been working on lately?
⤋ Read More
@kiwu@twtxt.net Working on my game Frontier Crown – Going to push a new version today hopefully that includes much improved graphics, expanded ruleset and scope.
The auDA, and some 3rd-party identify service and my Registrar are a joke!
WOW! I just had to share this little story I ran into today.
I tried to register a .AU Domain the other day, only for it to instantly fail.
I emailed support, which took several days to respond, only for them to respond by saying (paraphased):
We’re sorry, but the identify checks failed. The 3rd-aprty service doesn’t tell us why, But, please make sure that the ID you used matches the Full Name, including any Middle name(s).
I used my Passport number. Which of course has my First, Middle and Last Name.
I can only assume at this point that the checks failed on the missing “Middle name”. Why? Because the Registrar I use has a database and user interface for “contacts” that only have support for First name and Last name. NO Middle Name.
🤦♂️ This is basically stupid at this point. Systems cannot be trusted at the most fundamental level, no matter how good they are.
Until we figure out how to build a system that allows an individual to prove to another entity that they are who they say they are without a shred of doubt (i.e: cryptographically), we’re stuffed.
There is literally nothing I can do in this case. The auDA are at fault. The 3rd-party identify service (unknown) are at fault. The registrar are at fault. Hell, even the Passport office are at fault for even bothering to or requiring a Middle name.
How has “identity” come to this?
I won our only game of Magic for this week with my (yet-to-be published) “Bolas Triumphant” deck: 5 players over 3 hours, including 4 board wipes (one of which came from my Nicol Bolas, God-Pharaoh), and I even got to cast Omniscience via a Fae of Wishes. I can’t speak for everyone, but I know I had a good time. 😁
↳
In-reply-to
»
Just cancelled my sponsorship of two developers on Github, sorry 😞 -- I'm not going to sponsor going forward if no-one else can be bothered to. It seems silly to be the sole sponsor of another's work or project 🤦♂️
⤋ Read More
@prologic@twtxt.net I sponsor no one. If getting paid is the aim, form a business, or sell a product. I donate to just causes, though, including sponsorship to the dispossessed.
↳
In-reply-to
»
Eehhh, what the hell is going on here!?
⤋ Read More
@lyse@lyse.isobeef.org AI result ahead, feel free to ignore.
I “asked” the AI at work the same question out of morbid curiousity. It “said” that SQLite converts that integer to floating point internally on overflows and then, when converting back, the x86 instruction cvttsd2si will turn it into 0x8000000000000000, even if the actual floating point value is outside of that range. So, yes, it allegedly actually saturates, as a side effect of the type conversion.
I couldn’t find anything about that automatic conversion in SQLite’s manual, yet, but an experiment looks like it might be true:
sqlite> select typeof(1 << 63);
╭─────────────────╮
│ typeof(1 << 63) │
╞═════════════════╡
│ integer │
╰─────────────────╯
sqlite> select typeof((1 << 63) - 1);
╭──────────────────────╮
│ typeof((1 << 63) ... │
╞══════════════════════╡
│ real │
╰──────────────────────╯
As for cvttsd2si, this source confirms the handling of 0x8000000000000000 on range errors: https://www.felixcloutier.com/x86/cvttsd2si
The following C program also confirms it (run through gdb to see cvttsd2si in action):
<a href="https://yarn.girlonthemoon.xyz/search?q=%23include">#include</a> <stdint.h>
<a href="https://yarn.girlonthemoon.xyz/search?q=%23include">#include</a> <stdio.h>
int
main()
{
int64_t i;
double d;
/* -3000 instead of -1, because `double` can’t represent a
* difference of -1 at this scale. */
d = -9223372036854775808.0 - 3000;
i = d;
printf("%lf, 0x%lx, %ld\n", d, i, i);
return 0;
}
(Remark about AI usage: Fine, I got an answer and maybe it’s even correct. But doing this completely ruined it for me. It would have been much more satisfying to figure this out myself. I actually suspected some floating point stuff going on here, but instead of verifying this myself I reached for the unethical tool and denied myself a little bit of fun at the weekend. Won’t do that again.)
What do the Gopher Troopers think of the following? The Gopher protocol is a nearly-forgotten network protocol from the early 1990s, designed to serve and navigate text-based menus and documents over the Internet. While its far less common than HTTP/HTTPS today, there are still some security risks associated with Gopher and Gopher space. Lets break them down carefully: 1. Lack of Encryption Problem: Gopher was designed long before widespread use of SSL/TLS. All dataincluding credentials, file transfers, and menu selectionsis transmitted in plaintext. Impact: Anyone intercepting traffic (e.g., via a network sniffer, public Wi-Fi, or a compromised router) can read sensitive information, including usernames and passwords. 2. No Authentication or Access Control Problem: Gopher servers rarely implement robust authentication; access control is usually limited or non-existent. Impact: Unauthorized users might browse sensitive directories or download private files, particularly if servers are misconfigured. 3. Server Software Vulnerabilities Problem: Modern OSes can still run legacy Gopher servers, but the software is often unmaintained. Impact: Old software may contain buffer overflows, directory traversal bugs, or command injection vulnerabilities that attackers could exploit. 4. Malicious Gopher Links Problem: Gopher menus can contain links that point to scripts or other servers, similar to hyperlinks in HTTP. A client following a malicious link could inadvertently: Download malware Access sensitive internal network resources (server-side request forgery) Impact: Could serve as a vector for attacks if a user opens content from untrusted sources. 5. Legacy Protocol Weaknesses Problem: Gopher lacks modern web security mechanisms like: Content security policies Same-origin policies Cross-site request forgery protection Impact: If Gopher is bridged to other services (like modern browsers via gateways), old vulnerabilities may be exposed. 6. Information Leakage Problem: Gopher servers often provide directory listings without restriction. Impact: Sensitive files, backup directories, and internal documents may be exposed unintentionally. 7. Bridging Risks Problem: Some modern browsers access Gopher via gateways (HTTP-to-Gopher proxies). These bridges may: Expose sensitive internal resources to the gateway Introduce logging or tracking that wouldnt exist on pure Gopher Impact: Attacks could occur indirectly through insecure intermediaries. Key Takeaways Gopher is inherently insecure due to its design in a pre-HTTPS era. Main threats: eavesdropping, unauthorized access, malware delivery, and exploitation of unpatched server software. Safe practice: Use Gopher only in isolated, trusted environments, or through secure HTTP(S) gateways with proper sanitization.
↳
In-reply-to
»
For the first time in years, I managed to get out and throw a round of disc golf. Had a good time playing Vietnam Veterans Park in Kannapolis, throwing +10 over 9 holes, with my only par being thanks to a 40' "putt" with my MRV. And the weather was perfect.
⤋ Read More
@lyse@lyse.isobeef.org For reasons I can’t fully explain, we have a bunch of courses in the area, most in public parks (they integrate nicely since they can be built with the existing landscape, only adding some yellow baskets, concrete starting pads, and maybe signs).
In my experience, the main difference between a disc golfer and a frisbee thrower is that the disc golfer will often have a bag full of different shapes of discs (including drivers of varying ranges and/or putters). Even in my small bag, I’ve got some long range drivers (a Beast, a Cheetah, a Valkyrie, and a Wraith), my aforementioned MRV (Mid-Range Vector), an ultralight Aero (which feels similar to a “standard” frisbee), and 2 “rubber” putters (softer plastic, less “bouncy”).
{kind=link}
↳
In-reply-to
»
In the interest of fairness and hopefully for the last time, I ever have to address this, Google has flip-flopped again and promised "sideloading" will not be removed from their version of Android, but instead have to be enabled in the developer settings, using the following "advanced flow":
Media
To be perfectly clear, this still falls short of what I wanted, but at this point, it is a compromise I'm willing to take, over further pursuing this, through the various available European courts, myself.
⤋ Read More
@bender@twtxt.net both, but neither directly. I know every workaround there is, including those used by developers, to test apps, while working on them. However if “sideloading” becomes so tedious, even the more technical users, cannot be bothered to do it, competing appstores and independent developers, not wanting to send their money and ID to Google, loose users at such rate, they likely won’t be able to justify continuing to maintain their projects, people like me rely on.
↳
In-reply-to
»
Hello twtxt! I still exist. I have a baby now and put some pictures at https://photos.falsifian.org/ . Album HTML loosely inspried by @lyse
⤋ Read More
@falsifian@www.falsifian.org Congrats, mate, no sleep at night anymore! ;-D That’s a cool age measuring blanket. Haven’t seen something like that before.
Btw. the index.html includes an out of place </ul>. And I just wanna let you know that the full-size photos don’t load for me over here across the pond. They always run into a timeout after a few slooow percent. But no worries. :-)
👋 Looking for other interested folks to continue to evolve the development of Salty.im 🙏 I’ve been hard™ at work on the v2 branch and @doesnm.p.psf.lt@doesnm.p.psf.lt has been incredibly helpful so far. Be great ot have a few more folks to join us, some of the v2 highlights include:
- Double Ratchet by default.
- Group Chat (sender/client fan-out for now)
- Much better TUI with background agent.
- Mobile App coming soon™ (iOS in progress, Android next, same codebase)
I spent the day today integrating @xuu@txt.sour.is’s double ratcheting work and ratchet library back into the reference client/broker implementation saltyim as a v2 branch. I completely redesigned and rewrite the salty-chat TUI client as well, which now includes proper notifications and a background agent that keeps running so you never miss any messages. It all “just works”™ and I’m quite happy with the outcome! 🤩 #saltyim #revamp
@movq@www.uninformativ.de if they haven’t, I would recommend a “subtle” nudge. You know, like leaving an advert flier at their door for a “Basic English (including swearing words!) for Dummies” book, or something like that. :-D :-P
@movq@www.uninformativ.de my mum, who hand washed clothes for many, many years, would stare at you, incredulously, and tell you, “have fun with that!”. Hand washing a ton of clothes, including sheets, etc., is a royal, glorious, pain! Now drying it, when you live on the land of eternal sunshine, is a different matter.
↳
In-reply-to
»
Btw @movq you've inspired me to try and have a good 'ol crack at writing a bootloader, stage1 and customer microkernel (µKernel) that will eventually load up a Mu (µ) program and run it! 🤣 I will teach Mu (µ) to have a
⤋ Read More
./bin/mu -B -o ... -p muos/amd64 ... target.
Whohoo! 🥳  You have no idea how great a feeling this is! This includes the Mu stdlib and runtime as well, not just some simple stupid program, this means a significant portion of the runtime and stdlib “just works”™ 🤣
You have no idea how great a feeling this is! This includes the Mu stdlib and runtime as well, not just some simple stupid program, this means a significant portion of the runtime and stdlib “just works”™ 🤣
Okay, I had heard of “River” before but I was not aware of this:
https://codeberg.org/river/river
River defers all window management policy to a separate window manager implementing the river-window-management-v1 protocol. This includes window position/size, pointer/keyboard bindings, focus management, window decorations, desktop shell graphics, and more.
This sounds promising and it follows the old X11 model. River does all the nasty Wayland work and I can make just the WM? 🤔🤯
↳
In-reply-to
»
@lyse Ah, the lower right corner is different on purpose: It’s where you can click and drag to resize the window. https://movq.de/v/cbfc575ca6/vid-1767977198.mp4 Not sure how to make this easier to recognize. 🤔 (It’s the only corner where you can drag, btw.)
⤋ Read More
@lyse@lyse.isobeef.org It’s not super comfortable, that’s right.
But these mouse events come with a caveat anyway:
ncurses uses the XM terminfo entry to enable mouse events, but it looks like this entry does not enable motion events for most terminal emulators. Reporting motion events is supported by, say, XTerm, xiate, st, or urxvt, it just isn’t activated by XM. This makes all this dragging stuff useless.
For the moment, I edited the terminfo entry for my terminal to include motion events. That can’t be a proper solution. I’m not sure yet if I’m supposed to send the appropriate sequence manually …
And the terminfo entries for tmux or screen don’t include XM at all. tmux itself supports the mouse, but I’m not sure yet how to make it pass on the events to the programs running inside of it (maybe that’s just not supported).
To make things worse, on the Linux VT (outside of X11 or Wayland), the whole thing works differently: You have to use good old gpm to get mouse events (gpm has been around forever, I already used this on SuSE Linux). ncurses does support this, but this is a build flag and Arch Linux doesn’t set this flag. So, at the moment, I’m running a custom build of ncurses as a quick hack. 😅 And this doesn’t report motion events either! Just clicks. (I don’t know if gpm itself can report motion events, I never used the library directly.)
tl;dr: The whole thing will probably be “keyboard first” and then the mouse stuff is a gimmick on top. As much as I’d like to, this isn’t going to be like TUI applications on DOS. I’ll use “Windows” for popups or a multi-window view (with the “WindowManager” being a tiny little tiling WM).
mu (µ) now has builtin code formatting and linting tools, making µ far more useful and useable as a general purpose programming language. Mu now includes:
- An interpreter for quick “scriptinog”
- A native code compiler for building native executables (Darwin / macOS only for now)
- A builtin set of developer tools, currently: fmt (-fmt), check (-check) and test (-test).
@shinyoukai@neko.laidback.moe Because you might not want to commit all changed files in a single commit. I very often make use of this and create several commits. In fact, I like to git add --patch to interactively select which parts of a file go in the next commit. This happens most likely when refactoring during a feature implementation or bug fix. I couldn’t live without that anymore. :-)
If you have a much more organized way of working where this does not come up, you can just git commit --all to include all changed files in the next commit without git adding them first. But new files still have to be git added manually once.
My little toy operating system from last year runs in 16-bit Real Mode (like DOS). Since I’ve recently figured out how to switch to 64-bit Long Mode right after BIOS boot, I now have a little program that performs this switch on my toy OS. It will load and run any x86-64 program, assuming it’s freestanding, a flat binary, and small enough (< 128 KiB code, only uses the first 2 MiB of memory).
Here I’m running a little C program (compiled using normal GCC, no Watcom trickery):
https://movq.de/v/b27ced6dcb/los86%2D64.mp4
https://movq.de/v/b27ced6dcb/c.png
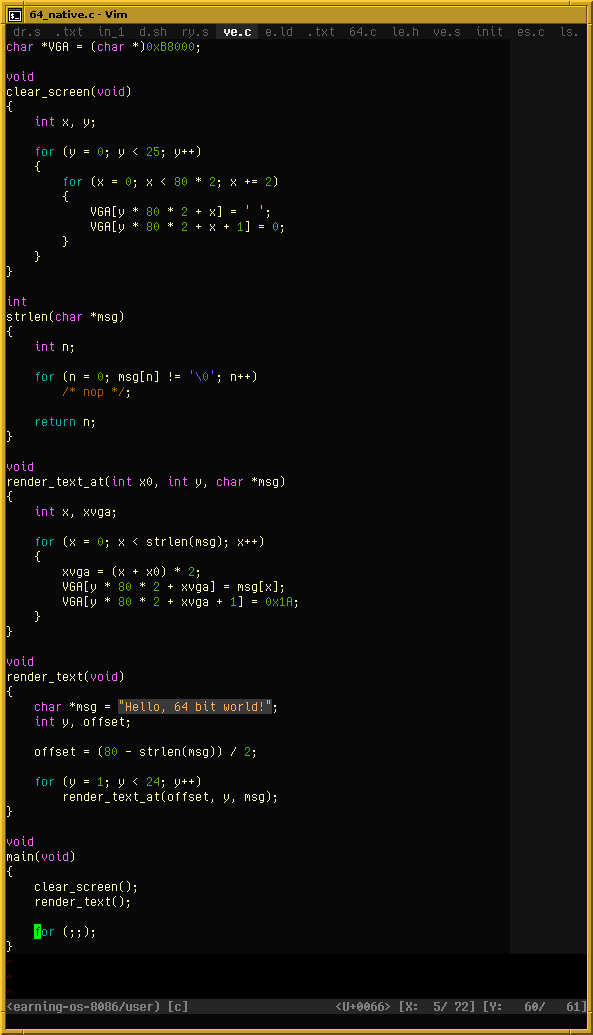{kind=link}
Next steps could include:
- Use Rust instead of C for that 64-bit program?
- Provide interrupt service routines. (At the moment, it just keeps interrupts disabled.)
↳
In-reply-to
»
@movq wow! what is assembler?
⤋ Read More
@movq@www.uninformativ.de @kiwu@twtxt.net it just so happens to be a happy coincidence that I’m extending mu’s capabilities to now include a native toolchain-free compiler (doesn’t rely on any external gcc/clang or linkers, etc) that lowers the mu source code into an intermediate representation / IR (what @movq@www.uninformativ.de refers to as “thick layers of abstractions”…) and finally to SSA + ARM64 + Mach-O encoder to produce native binary executables (at least for me on my Mac, Linux may some later?) 🤣
Yes, I agree. Read the bible. You’ll learn why most of the world, including f****d up politics plays a massive role. Don’t be lost. READ.
Thinking about doing Advent of Code in my own tiny language mu this year.
mu is:
- Dynamically typed
- Lexically scoped with closures
- Has a Go-like curly-brace syntax
- Built around lists, maps, and first-class functions
Key syntax:
- Functions use
fnand braces:
fn add(a, b) {
return a + b
}
- Variables use
:=for declaration and=for assignment:
x := 10
x = x + 1
- Control flow includes
if/elseandwhile:
if x > 5 {
println("big")
} else {
println("small")
}
while x < 10 {
x = x + 1
}
- Lists and maps:
nums := [1, 2, 3]
nums[1] = 42
ages := {"alice": 30, "bob": 25}
ages["bob"] = ages["bob"] + 1
Supported types:
int
bool
string
list
map
fn
nil
mu feels like a tiny little Go-ish, Python-ish language — curious to see how far I can get with it for Advent of Code this year. 🎄
../ isn’t supported in SSI includes
I’m kind of tired of late of telling support folks, for example, ym registrar, how to do their fucking goddamn jobs 🤦♂️
Hi James,
Thank you for your patience.
There are several reasons why a .au domain registration might fail or be cancelled, including inaccurate registrant information, ineligibility for a .au domain licence, or issues related to Australian law.
For a full list of possible reasons, please see this article: https://support.onlydomains.com/hc/en-gb/articles/6415278890141-Why-has-my-au-domain-registration-been-cancelled
If you believe none of these reasons apply to your case, please let us know so we can investigate further.
Best regards,
Yes, so tell me support person, why the fuck did it fail?! 🤬
Geologic Core Sample
 ⌘ Read more
⌘ Read more
Realized that I don’t have to include
My goodness, a new level of stupidity.
The bots are now doing things like this:
GET http://uninformativ.de/projects/lariza/feednotify/datenstrahler/slinp/countty HTTP/1.1
- That URL does not exist.
- By including
http://uninformativ.dein that request, this instructs the webserver to do an HTTP proxy request. Of course, this isn’t allowed on my webserver (and shouldn’t by allowed on any normal webserver), resulting in HTTP 400. And even if it were, the target would be the exact same server, making a proxy request unnecessary.
And of course, it’s not just 50 hits like this or 100 or 1’000 or 10’000. No, it’s over 150’000 in the last 2 days. All from vastly different IP ranges of different cloud hosters.
This almost looks like a DDoS attack, but it’s just completely stupid. This feels more like some idiot vibe coded a crawler.
↳
In-reply-to
»
For the innocent bystanders (because I know that I won’t change @bender’s opinion):
⤋ Read More
@lyse@lyse.isobeef.org @bender@twtxt.net I’m not very knowledgable regarding the two points you mentioned, hence I didn’t include them in my list. But, yeah, from what I’ve heard, it doesn’t look good.
Java’s Swing is allegedly in “maintenance mode”, so I doubt it’s a good idea to use it for new programs. For example, I very much doubt that it will ever support Wayland.
The replacement is supposed to be JavaFX, but that’s not included in JREs – anymore! It used to be, now it’s not, even though it’s well over 15 years old now.
This whole thing (“Java GUIs”) appears to have stagnated a lot. Probably because everything is web stuff these days …
https://www.oracle.com/java/technologies/javafx/faq-javafx.html#6
↳
In-reply-to
»
Der ganze Vorgang ist archetypisch für die seit Jahrzehnten völlig ohne Not stattfindende politische Selbstverzwergung Europas.
⤋ Read More
@movq@www.uninformativ.de My impression also is that good sysadmins are missing. No wonder if they all get laid off because they’re “not doing anything” and developers can just operate their shit themselves. Or so the bosses and plenty devs think. Sadly, that’s the general view.
Hell no, devops is bullshit in my opinion. Most developers (including myself) are rather bad at administrating. A good sysadmin offers other skills. Great admins appear to just sit around, but they’re much more proactively working than programmers who also operate the same stuff. The latter have a waaay more reactive work model in comparison. When things have already gone south. The sysadmin, on the other hand, would have noticed and thus prevented the vast majority very early on when it was far from becoming a problem in the future.
At least that’s my personal experience in all those years in different projects and what my mates tell me from their companies. Sure, skills can be learned, but it’s just not happening (enough). And obviously, there are people out there who excel in both disciplines, but they are rare. Most fall in one of the categories. Not to forget, plenty are just bad at everything. :-)
↳
In-reply-to
»
Of course, all things optional is fine. Like, it will be ignored (just like
⤋ Read More
banner would) for clients having no knowledge of it.
@zvava@twtxt.net It is a common UI element in most social platform after all, it’s easy to include when planning something similar.