↳
In-reply-to
»
Hehe! it's done! 🤡
⤋ Read More
@doesnm@doesnm.p.psf.lt nah, I’m fine without a web ui. But I like what the dev did with the 2009 facebook/VK look, it kind of feels notsalgic. (the tld is a .me not a .com if anyone else wants to take a look atit)
↳
In-reply-to
»
Confession:
⤋ Read More
@kat@yarn.girlonthemoon.xyz Off-topic areas are always a good idea. :-) Web forums often had those. And web forums are actually what I had in mind, @bender@twtxt.net. 😅 (While I do have a certain nostalgia for it now, Usenet has always been a bit weird to me. Can’t really explain why.)
↳
In-reply-to
»
Hehe! it's done! 🤡
⤋ Read More
@aelaraji@aelaraji.com Lol gts is so popular. But if choicing something with fancy web ui maybe Smithereen is best option. Example instance: https://friends.grishka.com
↳
In-reply-to
»
@kat That's what I was going for at first, I already have my compose file to go
⤋ Read More
up -d, but then I took a look at a couple of #Snac instances at the last second and they looked pretty dope! Now I'm stuck in my own head 😅
@aelaraji@aelaraji.com which snac instance did you see that looked pretty dope? On the ones I saw in the past, I found their web frontend to be rather messy (even more so on mobile).
@peron@texto-plano.xyz compartió una web para generar tonos para el GRUB en Mastodon, acá la comparto también https://t.ly/xZh-s
↳
In-reply-to
»
To the parents or teachers: How do you teach kids to program these days? 🤔
⤋ Read More
We’re all old farts. When we started, there weren’t a lot of options. But today? I’d be completely overwhelmed, I think.
Hence, I’d recommend to start programming with a console program. As for the language, not sure. But Python is probably a good choice
That’s what I usually do (when we have young people at work who never really programmed before), but it doesn’t really “hit” them. They’ve seen so much, crazy graphics, web pages, it’s all fancy. Just some text output is utterly boring these days. ☹️ And that’s my problem: I have no idea how I could possibly spark some interest in things like pointers or something “low-level” like that. And I truly believe that you need to understand things like pointers in order to program, in general.
↳
In-reply-to
»
To the parents or teachers: How do you teach kids to program these days? 🤔
⤋ Read More
I should probably clarify: Which language/platform? Something graphical or web-based right from the beginning or do you start with a console program?
The VTech Socratic method
We’ve had a lot of fun with VTech’s computers in the past on this blog. Usually, they’re relatively spartan computers with limited functionality, but they did make something very interesting in the late 80s. The Socrates is their hybrid video game console/computer design from 1988, and today we’ll start tearing into it. ↫ Leaded Solder web log Now we’re in for the good stuff. A weird educational computer/game console/toy thing from the late ’80s, by VTech. I have a massive soft s … ⌘ Read more
Oddly, in defense of Google keeping Chrome
As much as I’m a fan of breaking up Google, I’m not entirely sure carving Chrome out of Google without a further plan for what happens to the browser is a great idea. I mean, Google is bad, but but things could be so, so much worse. OpenAI would be interested in buying Google’s Chrome if antitrust enforcers are successful in forcing the Alphabet unit to sell the popular web browser as part of a bid to restore competition in search, an OpenAI execu … ⌘ Read more
Exciting new for Python 3.14!
t-string, not to be confused with f-string, to avoid malicious code and make life easier for web developers.
https://davepeck.org/2025/04/11/pythons-new-t-strings/
#python
Hmmm there’s a bug somewhere in the way I’m ingesting archived feeds 🤔
sqlite> select * from twts where content like 'The web is such garbage these days%';
hash = 37sjhla
feed_url = https://twtxt.net/user/prologic/twtxt.txt/1
content = The web is such garbage these days 😔 Or is it the garbage search engines? 🤔
created = 2024-11-14T01:53:46Z
created_dt = 2024-11-14 01:53:46
subject = #37sjhla
mentions = []
tags = []
links = []
sqlite>
is it like… ethical to offer access to certain self hosted services as patreon exclusives. like i wanna offer the IRC client/bouncer i hosted which seems ok i think because i’ve seen pico.sh offer their instances of that as paid services. but the other ones i have in mind are alt web frontends for stuff like imgur and pinterest. and i just feel weird about it for some reason. idk i’m trying to think of ways to support my server stuff but every time i come up with something it feels weird
↳
In-reply-to
»
guys i may be stupid. i confused IRC bouncer with IRC server
⤋ Read More
@prologic@twtxt.net oooh this looks interesting!!! maybe i could play around with it in docker and see how to integrate it with caddy layer4 for TLS + my existing web client and bouncer!!
↳
In-reply-to
»
guys i may be stupid. i confused IRC bouncer with IRC server
⤋ Read More
@movq@www.uninformativ.de i tried ngircd but couldn’t figure it out T__T i left it at the web client and bouncer for now but i might toy with an IRC server another time!
I asked ChatGPT what it knows about Twtxt 😂 And surprisingly it’s rather accurate:
Twtxt is a minimalist, decentralized microblogging format introduced by John Downey in 2016. It uses plain text files served over HTTP—no accounts, databases, or APIs.
In 2020, James Mills (@prologic@twtxt.net) launched Yarn.social, an extended, federated implementation with user discovery, threads, mentions, and a full web UI.
Both share the same .twtxt.txt format but differ in complexity and social features.
↳
In-reply-to
»
jenny really isn’t well equipped to handle edits of my own twts.
⤋ Read More
@movq@www.uninformativ.de wouldn’t editing your own twtxts cause the same issue Yarnd (or any other client) has, which is breaking any replies to it? Under which conditions would this work the best? When copying the twtxt.txt file asynchronously? In my case I copy the twtxt.txt file to its web root right away, but I figure I could not do that, which would give me a set period of time to edit without worries.
The captchas have become sentient: we’re working on fixing the captcha issue
As some of you may have noticed, we’ve been having some issues with captchas. The powers that be – which isn’t me, I don’t know anything about web development – are looking into it, and once we’ve pinpointed the problem we’ll get it fixed. It’s annoying us too, so we want this resolved as quickly as possible. OSNews readers just trying to visit the site to read some tech stuff shou … ⌘ Read more
↳
In-reply-to
»
@eapl.me You asked me for private keys for testing purposes. I have added it to the bottom of this page: https://dm-echo.andros.dev/
It will soon be running. It won't be long now.
⤋ Read More
well, I suggested that in https://eapl.me/timeline/conv/k2ob6bq
The idea was to help those following the spec in https://twtxt.dev/exts/directmessage.Html, to replicate the steps and validate whether your implementation gives the same result.
BTW, you could add a link to the spec in the echo web.
AI problems, top to bottom:
1: Open AI nerds, believe fine tuning a language model algorithm, will eventually produce an AGI god.
2: Subpar artists and techbros who can’t code, convinced AI image bashing and vibe coding, will help convince the dumber parts of Internet, they are a real deal.
3: Parasites, using AI to scam people, because they just want passive income, selling crap, made by an automated process.
Side: Adobe&co, killing Flash/old web, pricing new artists and developers out, to face learning curves of free tools, or use AI, peddled as solution.
↳
In-reply-to
»
The photo series covering old stuff continues. This time, Gundelsheim. Actually, mostly the castle hotel Horneck, I hardly took any photos from the town itself. I really should have, though. Let me just blame… aehm… yeah, the rain! It's totally the rain's fault!! When it started to drizzle, I actually took the first photos, so it's a total lie. https://lyse.isobeef.org/schlosshotel-horneck-in-gundelsheim-2025-03-30/
⤋ Read More
@david@collantes.us This pink tree I featured in a few shots is a magnolia tree. I haven’t noticed any particular smell, it just looks pretty. :-) That’s a close-up:  (I only noticed the spider and its web when I reviewed my photos.)
(I only noticed the spider and its web when I reviewed my photos.)
↳
In-reply-to
»
@lyse you must be loved by all the web developers in town! But ok, I have added all the missing semicolons, that should technically be there, but them not being there, does not make a difference.
⤋ Read More
@lyse@lyse.isobeef.org I do agree “the rules of the web”, are far too loose - at least the syntax ones. I do think backwards compatibility is necessary.
As for my website, it might be visually very similar, to how it looked since its creation, many years ago, but it is frequently improved. Features that originally used JavaScript, changed to HTML and CSS components, code simplified, optimised to withstand browser updates and new screen resolutions,… Even a good chunk of the errors on your list, were already addressed and I plan to address the rest soon.
Just find it a bit depressing, that my attempt to bring back some of the old Internet spirit, by making a hidden easteregg page page for this years April 1st, was met with people complaining about April fools day jokes and you insinuating my website sucks.
↳
In-reply-to
»
@lyse you must be loved by all the web developers in town! But ok, I have added all the missing semicolons, that should technically be there, but them not being there, does not make a difference.
⤋ Read More
@thecanine@twtxt.net And this is exactly why there are quirks modes in browsers…
I’m actually glad I don’t have to deal with all this web shit and work with compilers that hit me in the face when I do something illegal. :-)
↳
In-reply-to
»
There's a secret art easter egg thing, hidden on my website ( https://thecanine.ueuo.com ), for this years April fools event - it's been there for a few weeks, but now I can finally give hints.
⤋ Read More
@lyse@lyse.isobeef.org you must be loved by all the web developers in town! But ok, I have added all the missing semicolons, that should technically be there, but them not being there, does not make a difference.
Font color change inside every summary element, was a very deliberate choice, to color the text, but leave the arrow black (same as website background). But ok, I rewrote the CSS to hide the arrows and make all summaries white - since this also works better, with some dark theme enforcing browser extensions.
HOWEVER “p” as a child element of “summary” is a thing, that as far as I know, all browsers respect and if a font color is applied only once, I don’t think it matters, if it’s done through HTML or CSS, you smart ass.
↳
In-reply-to
»
I think I should try self-hosting some Mastodon thingy again.
⤋ Read More
@prologic@twtxt.net In all seriousness: Don’t worry, I’m not going to host some Fediverse thingy at the moment, probably never will. 😅
But I do use it quite a lot. Although, I don’t really use it as a social network (as in: following people). I follow some tags like #retrocomputing, which fills my timeline with interesting content. If there was a traditional web forum or mailing list or even a usenet group that covered this topic, I’d use that instead. But that’s all (mostly) dead by now. ☹️
The brokenness of the web can be examined by opening about:compat in Firefox.
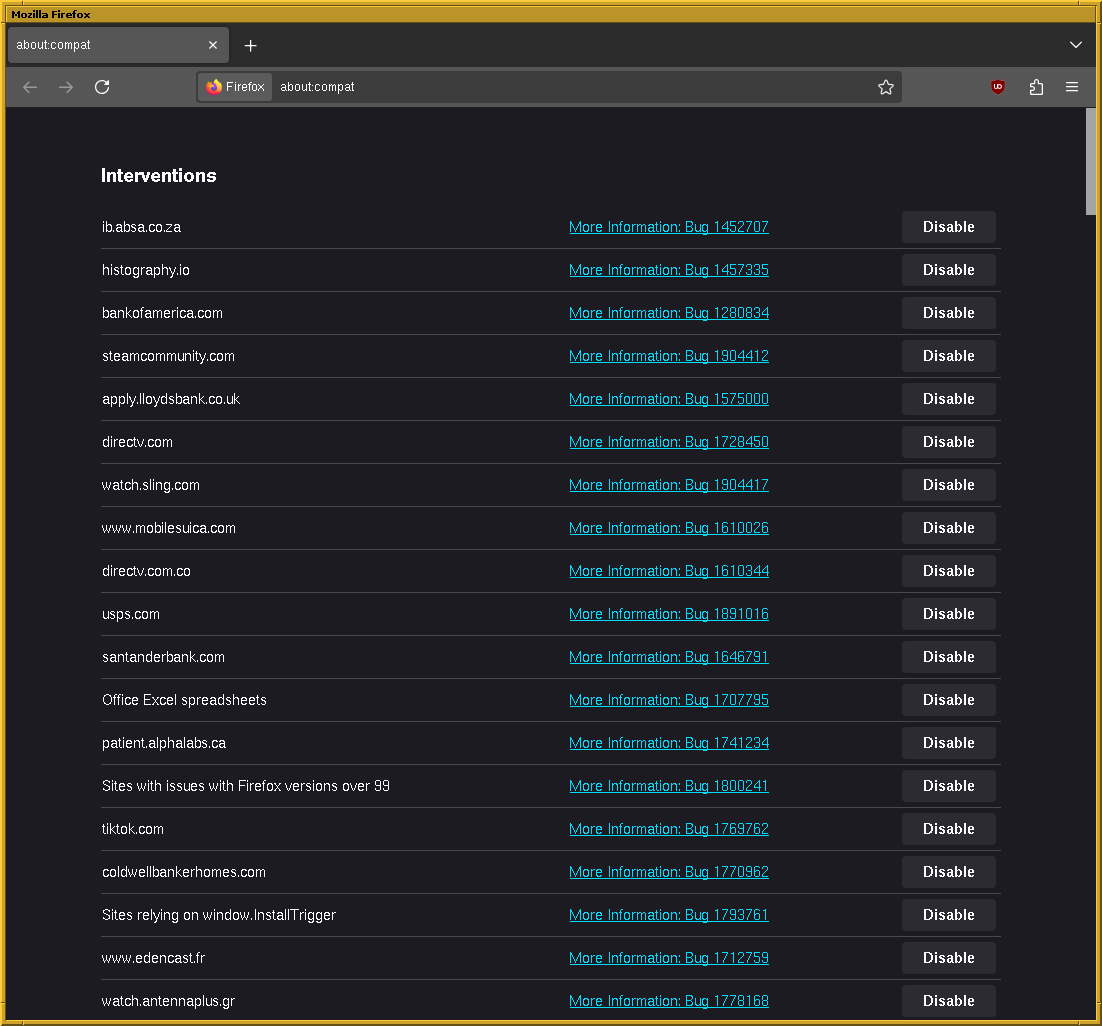
Lots and lots of workarounds for specific websites.
Playing multimedia with Dillo
What if you want to use a web browser like Dillo, which lacks JavaScript support and can’t play audio or video inside the browser? Dillo doesn’t have the capability to play audio or video directly from the browser, however it can easily offload this task to other programs. This page collects some examples of how to do watch videos and listen to audio tracks or podcasts by using an external player program. In particular we will cover mpv with yt-dlp which supports YouTube … ⌘ Read more
↳
In-reply-to
»
When will the flat UI craze end? Can I get my buttons, scrollbars, and toolbars back, please?
⤋ Read More
@movq@www.uninformativ.de Yeah, most of the graphical applications are actually KDE programs:
- KMail – e-mail client
- Okular – PDF viewer
- Gwenview – image viewer
- Dolphin – file browser
- KWallet – password manager (I want to check out
passone day. The most annoying thing is that when I copy a password, it says that the password has been modified and asks me whether I want to save the changes. I never do, because the password is still the same. I don’t get it.)
- KPatience – card game
- Kdenlive – video editor
- Kleopatra – certificate manager
Qt:
- VLC – video player
- Psi – Jabber client (I happily used Kopete in the past, but that is not supported anymore or so. I don’t remember.)
- sqlitebrowser – SQLite browser
Gtk:
- Firefox – web browser
- Quod Libet – music player (I should look for a better alternative. Can’t remember why I had to move away from Amarok, was it dead? There was a fork Clementine or so, but I had to drop that for some unknown reason, too.)
- Audacity – audio editor
- GIMP – image editor
These are the things that are open right now or that I could think of. Most other stuff I actually do in the terminal.
In the past™, I used the Python KDE4 bindings. That was really nice. I could pass most stuff directly in the constructor and didn’t have to call gazillions of setters improving the experience significantly. If I ever wanted to do GUI programming again, I’d definitely go that route. There are also great Qt bindings for Python if one wanted to avoid the KDE stuff on top. The vast majority I do for myself, though, is either CLI or maybe TUI. A few web shit things, but no GUIs anymore. :-)
Memory safety for web fonts in Chrome: Google replaces FreeType with Rust-based alternative
There’s no escaping Rust, and the language is leaving its mark everywhere. This time around, Chrome has replaced its use of FreeType with Skrifa, a Rust-based replacement. Skrifa is written in Rust, and created as a replacement for FreeType to make font processing in Chrome secure for all our users. Skifra takes advantage of Rust’s memory safety, and … ⌘ Read more
Gopher holes are not on the web, they are in gopher space
wahhh i wanna work towards my dream of offering pay as you can web hosting (static & dynamic) but i don’t know how!!!!! i keep drifting towards hosting panels but i don’t exactly have fresh linux servers for those nor do i like the level of access they require. so i’m like ok i can do the static site part with SFTP chroot jails and a front-end like filebrowser or something…. but then what about the dynamic sites!!!!!!! UGH
granted i doubt i’d get much interest in dynamic sites but i’d like to do this old school where i can offer people isolated mySQL databases or something for some project (i’m thinking PHP based fanlistings), which means i could do it the old school way of… people ask me to run it and i do it for them. but i kind of want to let people have access to be able to do it themselves just short of giving them SSH access which isn’t happening
are gopher holes not websites? they’re on the web after all
↳
In-reply-to
»
What does the #twtxt community think about having a p2p database to store all history? This will be managed by Registries.
⤋ Read More
pls elaborate on a ‘p2p database’, ‘all story’ and ‘Registries’.
My first thought takes me to something like secure-scuttlebutt which it’s painful to sync data using clients, and too slow compared to downloading a text file.
Also I’d like for twtxt to avoid becoming an ActivityPub. Works well but it’s uses too many resources IMO.
https://kingant.net/2025/02/mastodon-the-cost-of-running-my-own-server/
I’m defending being able to self-host your Web client (like you’d do with a Wordpress, twtxt is a micrologging, at the end), instead of federated instances, so in a first thought I’d say Registries have many disadvantages being the first one that someone has to maintain them active.
La web https://thedataschools.com/ tiene bastante y buen material para aprender SQL y otros lenguajes.
Genode OS Framework 25.02 released
The prime feature is the continuation of the multi-monitor topic of the previous release, covering multi-monitor window management and going as far as seamlessly integrating multi-monitor virtual machines (Section Multi-monitor window management and virtual machines). The second and long anticipated feature is the Chromium engine version 112 in combination with Qt 6.6.2, which brings our port of the Falkon web browser on par with the modern web (Section Qt, WebE … ⌘ Read more
Alors oui, il y a https://ladigitale.dev mais je cherche juste une page web facile à auto-héberger (html, js) <@ladigitale>
Web page readability on the CLI https://xn–gckvb8fzb.com/reader-web-page-readability-on-the-cli/
Chromium Ozone/Wayland: the last mile stretch
Lets start with some context, the project consists of implementing, shipping and maintaining native Wayland support in the Chromium project. Our team at Igalia has been leading the effort since it was first merged upstream back in 2016. For more historical context, there are a few blog posts and this amazing talk, by my colleagues Antonio Gomes and Max Ihlenfeldt, presented at last year’s Web Engines Hackfest. Especially due to the Lacros pr … ⌘ Read more
On my hit list of assholes tech giants that break the rules and are bad web citizens:
Microsoft
Google
Alibaba
Open AI
more to come…
Yesterday I was doing a lot of research on how #hyperdrive and the #holepunch project work. Would it be possible to use it to make #twtxt an easier gateway for new users? Could we stop using web servers?
My conclusion: We would end up being a #nostr. On the one hand it would become more complex to use, it would force the user to have software installed, and on the other hand the community would need a central proxy to make the routes accessible via HTTP. In other words, it’s not a good idea.
However, it’s an AMAZING technology. I want to start playing with it.
It would appear that Google’s web crawlers are ignoring the robots.txt that I have on https://git.mills.io/robots.txt with content:
User-agent: *
Disallow: /
Evidence attached (see screenshots): 
 – I think its the the Small Web community band together and file a class action suit(s) against Microsoft.com Google.com and any other assholes out there (OpenAI?) that violate our rights and ignore requests to be “polite” on the web. Thoughts? 💭
– I think its the the Small Web community band together and file a class action suit(s) against Microsoft.com Google.com and any other assholes out there (OpenAI?) that violate our rights and ignore requests to be “polite” on the web. Thoughts? 💭