↳
In-reply-to
»
Hmm, mine also resolves a leading tilde in these variables. And if
⤋ Read More
$HOME is not specified it tries to resolve the user's home directory by user.Current().HomeDir. Maybe that's overkill, I have to check the XDG spec.
Ok, the standard library implementation is wonky at best, at least in regards to XDG, because it really doesn’t implement it properly. https://github.com/golang/go/issues/62382 I stick to my own code then. It doesn’t properly support anything else than Linux or Unixes that use XDG, but personally, I don’t care about them anyway. And the cross-platform situation is a giant mess. Unsurprisingly.
↳
In-reply-to
»
@lyse Well, I used SnipMate years ago (until 2012). IIRC, it’s more than just “insert a bit of text here”, it can also jump to the correct next location(s) and stuff like that. Don’t remember why I stopped using it.
⤋ Read More
@movq@www.uninformativ.de Thanks! I’ll have a look at SnipMate. Currently, I’m (mis)using the abbreviation mechanism to expand a code snippet inplace, e.g.
autocmd FileType go inoreab <buffer> testfunc func Test(t *testing.T) {<CR>}<ESC>k0wwi
or this monstrosity:
autocmd FileType go inoreab <buffer> tabletest for _, tt := range []struct {<CR> name string<CR><CR><BS>}{<CR> {<CR> name: "",<CR><BS>},<CR><BS>} {<CR> t.Run(tt.name, func(t *testing.T) {<CR><CR>})<CR><BS>}<ESC>9ki<TAB>
But this of course has the disadvantage that I still have to remove the last space or tab to trigger the expansion by hand again. It’s a bit annoying, but better than typing it out by hand.
↳
In-reply-to
»
@lyse Yeah I remember you said some days back that your interest in compilers was rekindled by my work on mu (µ) 😅
⤋ Read More
@lyse@lyse.isobeef.org I can tell you this right now, writing assembly / machine code is fucking hard work™ 😓 I’m sure @movq@www.uninformativ.de can affirm 🤣 And when it all goes to shit™ (which it does often), man is debugging fucking hard as hell! Without debug symbols I can’t use the regular tools like lldb or gdb 😂
↳
In-reply-to
»
@lyse Yeah I remember you said some days back that your interest in compilers was rekindled by my work on mu (µ) 😅
⤋ Read More
@prologic@twtxt.net Yeah, the parser part is what I typically enjoy. Haven’t really looked into code generation itself.
I’m currently looking at your µ commits from the last few days. Holy cow! :-)
Whoo! I fixed one of the hardest bugs in mu (µ) I think I’ve had to figure out. Took me several days in fact to figure it out. The basic problem was, println(1, 2) was bring printed as 1 2 in the bytecode VM and 1 nil when natively compiled to machine code on macOS. In the end it turned out the machine code being generated / emitted meant that the list pointers for the rest... of the variadic arguments was being slot into a register that was being clobbered by the mu_retain and mu_release calls and effectively getting freed up on first use by the RC (reference counting) garbage collector 🤦♂️
↳
In-reply-to
»
Hmmm I need to figure out a way to reduce the no. of lines of code / complexity of the ARM64 native code emitter for mu (µ). It's insane really, it's a whopping ~6k SLOC, the next biggest source file is the compiler at only ~800 SLOC 🤔
⤋ Read More
@shinyoukai@neko.laidback.moe Nah it’s more like there’s a lot of repeated code, because when you go from source language to intermediate representation to machine code, well you just end up writing a lot of the same patterns over and over again. I need to dedupe this I think.
↳
In-reply-to
»
Hmmm I need to figure out a way to reduce the no. of lines of code / complexity of the ARM64 native code emitter for mu (µ). It's insane really, it's a whopping ~6k SLOC, the next biggest source file is the compiler at only ~800 SLOC 🤔
⤋ Read More
The compiler technique I’m using here is to not “emit” most of the runtime if it’s actually never used in your program, and also dropping dead code in the SSA pass.
Hmmm I need to figure out a way to reduce the no. of lines of code / complexity of the ARM64 native code emitter for mu (µ). It’s insane really, it’s a whopping ~6k SLOC, the next biggest source file is the compiler at only ~800 SLOC 🤔
↳
In-reply-to
»
My little toy operating system from last year runs in 16-bit Real Mode (like DOS). Since I’ve recently figured out how to switch to 64-bit Long Mode right after BIOS boot, I now have a little program that performs this switch on my toy OS. It will load and run any x86-64 program, assuming it’s freestanding, a flat binary, and small enough (< 128 KiB code, only uses the first 2 MiB of memory).
⤋ Read More
@movq@www.uninformativ.de I think I can get binaries even smaller with a bit more work and effort 🤔 But yeah still working on the native code generation (at least for macOS targets)
↳
In-reply-to
»
My little toy operating system from last year runs in 16-bit Real Mode (like DOS). Since I’ve recently figured out how to switch to 64-bit Long Mode right after BIOS boot, I now have a little program that performs this switch on my toy OS. It will load and run any x86-64 program, assuming it’s freestanding, a flat binary, and small enough (< 128 KiB code, only uses the first 2 MiB of memory).
⤋ Read More
@movq@www.uninformativ.de Oh that’s fine, Mu can compile to native code and so far binaries. at least on macOS are in the order of Kb in size 😂
My little toy operating system from last year runs in 16-bit Real Mode (like DOS). Since I’ve recently figured out how to switch to 64-bit Long Mode right after BIOS boot, I now have a little program that performs this switch on my toy OS. It will load and run any x86-64 program, assuming it’s freestanding, a flat binary, and small enough (< 128 KiB code, only uses the first 2 MiB of memory).
Here I’m running a little C program (compiled using normal GCC, no Watcom trickery):
https://movq.de/v/b27ced6dcb/los86%2D64.mp4
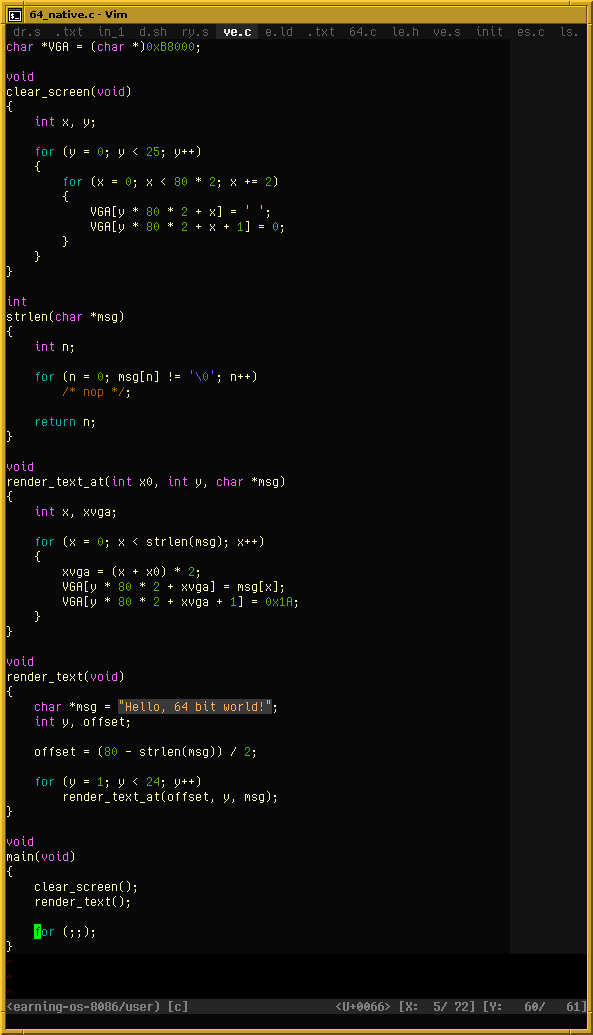
Next steps could include:
- Use Rust instead of C for that 64-bit program?
- Provide interrupt service routines. (At the moment, it just keeps interrupts disabled.)
↳
In-reply-to
»
@movq wow! what is assembler?
⤋ Read More
@prologic@twtxt.net You write so much code … it’s incredible. 😅
↳
In-reply-to
»
@movq wow! what is assembler?
⤋ Read More
@movq@www.uninformativ.de @kiwu@twtxt.net it just so happens to be a happy coincidence that I’m extending mu’s capabilities to now include a native toolchain-free compiler (doesn’t rely on any external gcc/clang or linkers, etc) that lowers the mu source code into an intermediate representation / IR (what @movq@www.uninformativ.de refers to as “thick layers of abstractions”…) and finally to SSA + ARM64 + Mach-O encoder to produce native binary executables (at least for me on my Mac, Linux may some later?) 🤣
Got a nice conspiracy theory for you:
https://mastodon.social/@mcc/115670290552252848
Actually wait I just thought about this and realized that the precise timing of the ACTUAL GitHub seed bank, by which I mean the Arctic Code Vault, on 2020-02-02, makes it more or less a perfect snapshot of pre-Copilot GitHub. Also precisely timed before we all got brain damage from COVID. This is the only remaining archive of source code by people with a fully working sense of smell
(Bonus points because the Arctic World Archive is located in Svaldbard and that’s the name of the AI in Stacey Kade’s “Cold Eternity”.)
I cleaned up all my of AoC (Advent of Code) 2025 solutions, refactored many of the utilities I had to write as reusable libraries, re-tested Day 1 (but nothing else). here it is if you’re curious! This is written in mu, my own language I built as a self-hosted minimal compiler/vm with very few types and builtins.
I finished all 12 days of Advent of Code 2025! #AdventOfCode https://adventofcode.com — did it in my own language, mu (Go/Python-ish, dynamic, int/bool/string, no floats/bitwise). Found a VM bug, fixed it, and the self-hosted mu compiler/VM (written in mu, host in Go) carried me through. 🥳
I just completed “Printing Department” - Day 4 - Advent of Code 2025 #AdventOfCode https://adventofcode.com/2025/day/4 – Again, I’m doing this in mu, a Go(ish) / Python(ish) dynamic langugage that I had to design and build first which has very few builtins and only a handful of types (ints, no flots). 🤣
I just completed “Lobby” - Day 3 - Advent of Code 2025 #AdventOfCode https://adventofcode.com/2025/day/3 – Again, I’m doing this in mu, a Go(ish) / Python(ish) dynamic langugage that I had to design and build first which has very few builtins and only a handful of types (ints, no flots). 🤣
I just completed “Gift Shop” - Day 2 - Advent of Code 2025 #AdventOfCode https://adventofcode.com/2025/day/2 – But again, I’m solving this in my own language mu that I had to build first 🤣
I just completed “Secret Entrance” - Day 1 - Advent of Code 2025 #AdventOfCode https://adventofcode.com/2025/day/1 — However I did it in my own toy programming language called mu, which I had to build first 🤣
↳
In-reply-to
»
Advent of Code 2025 starts tomorrow. 🥳🎄
⤋ Read More
Alright, Advent of Code is over:
https://www.uninformativ.de/blog/postings/2025-12-12/0/POSTING-en.html
It’s been quite the time sink, especially with the DOS games on top, but it was fun. 🥳
In case you’re wondering: All puzzles (except for part 2 of day 10) were doable in Python 1 on SuSE Linux 6.4 and ran in a finite time on the Pentium 133. Puzzle 10/2 might have been doable as well if I had better education. 🤣
my MIND is a MACHINE that turns ILLEGIBLE CODE into ILLEGIBLE CODE

i’ve learned a lot of lessons from writing my notes app, gonna apply this to bbycll and refactor the code to make it way more legible cause my custom templating system is only kind of a giant mess
↳
In-reply-to
»
In case you haven’t seen it yet:
⤋ Read More
@prologic@twtxt.net Here you go:
(LTT = “Linus Tech Tips”, that’s the host.)
LTT: There was a recent thing from a major tech company, where developers were asked to say how many lines of code they wrote – and if it wasn’t enough, they were terminated. And there was someone here that was extremely upset about that approach to measuring productivity, because–
Torvalds: Oh yeah, no, you shouldn’t even be upset. At that point, that’s just incompetence. Anybody who thinks that’s a valid metric is too stupid to work at a tech company.
LTT: You do know who you just said that about, right?
Torvalds: No.
LTT: Oh. Uh, he was a prominent figure in the, uh, improved efficiency of the US government recently.
Torvalds: Oh. Apparently I was spot on.
↳
In-reply-to
»
@prologic Bwahahaha! I tried to establish some form of “convention” for commit messages at work (not exactly what you linked to, though), but it’s a lost cause. 😂 Nobody is following any of that. Nobody wants to invest time in good commit messages. People just want to get stuff done.
⤋ Read More
@lyse@lyse.isobeef.org My theory is that these people simply don’t do “code archeology”. When something breaks, they don’t reach for git log. They simply don’t experience the pain that comes with bad commits / commit messages.
Or is that different in your company? 😅
↳
In-reply-to
»
@prologic Bwahahaha! I tried to establish some form of “convention” for commit messages at work (not exactly what you linked to, though), but it’s a lost cause. 😂 Nobody is following any of that. Nobody wants to invest time in good commit messages. People just want to get stuff done.
⤋ Read More
@movq@www.uninformativ.de Same. :‘-( I just don’t get how people do code archeology with all their shit messages and huge commits changing a gazillion of different things. I always try to lead by setting good examples, but nofuckingbody is picking up on that. At all. Even when bringing this up every now and then.
↳
In-reply-to
»
Working on day 3 of the Advent of Code 2025: https://adventofcode.com/
⤋ Read More
@itsericwoodward@itsericwoodward.com Nice to see someone else also participating! 🥳
(Btw, they don’t want us to share our inputs: https://www.reddit.com/r/adventofcode/wiki/faqs/copyright/inputs/ Yeah, it’s a bit annoying. I also have to do quite a bit of filtering on my repo …)
↳
In-reply-to
»
Advent of Code 2025 starts tomorrow. 🥳🎄
⤋ Read More
Most of the Advent of Code action happens on the Fediverse, I’m afraid:
https://tilde.zone/@movq/115595022987289988
There’s just way more people over there who participate. 🥴
Working on day 3 of the Advent of Code 2025: https://adventofcode.com/
My solutions repo: https://git.itsericwoodward.com/eric/aoc-2025
↳
In-reply-to
»
AoC Day #1 solution (mu): https://gist.mills.io/prologic/d3c22bcbc22949939b715a850fe63131
⤋ Read More
@prologic@twtxt.net Using your own language?! That’s really nice! I hope you get home soon so you can give the code a try. 😅
↳
In-reply-to
»
AoC Day #1 solution (mu): https://gist.mills.io/prologic/d3c22bcbc22949939b715a850fe63131
⤋ Read More
I actually can’t progress to day two till I get home 🤣 – I haven’t pushed the code for the mu compiler yet 🤦♂️ So no-one can check my work even if they were so kind 🤣
↳
In-reply-to
»
AoC Day #1 solution (mu): https://gist.mills.io/prologic/d3c22bcbc22949939b715a850fe63131
⤋ Read More
completely untested as i have no remote way of running mu code from Vietnam 🤣
Thinking about doing Advent of Code in my own tiny language mu this year.
mu is:
- Dynamically typed
- Lexically scoped with closures
- Has a Go-like curly-brace syntax
- Built around lists, maps, and first-class functions
Key syntax:
- Functions use
fnand braces:
fn add(a, b) {
return a + b
}
- Variables use
:=for declaration and=for assignment:
x := 10
x = x + 1
- Control flow includes
if/elseandwhile:
if x > 5 {
println("big")
} else {
println("small")
}
while x < 10 {
x = x + 1
}
- Lists and maps:
nums := [1, 2, 3]
nums[1] = 42
ages := {"alice": 30, "bob": 25}
ages["bob"] = ages["bob"] + 1
Supported types:
int
bool
string
list
map
fn
nil
mu feels like a tiny little Go-ish, Python-ish language — curious to see how far I can get with it for Advent of Code this year. 🎄
Advent of Code 2025 starts tomorrow. 🥳🎄
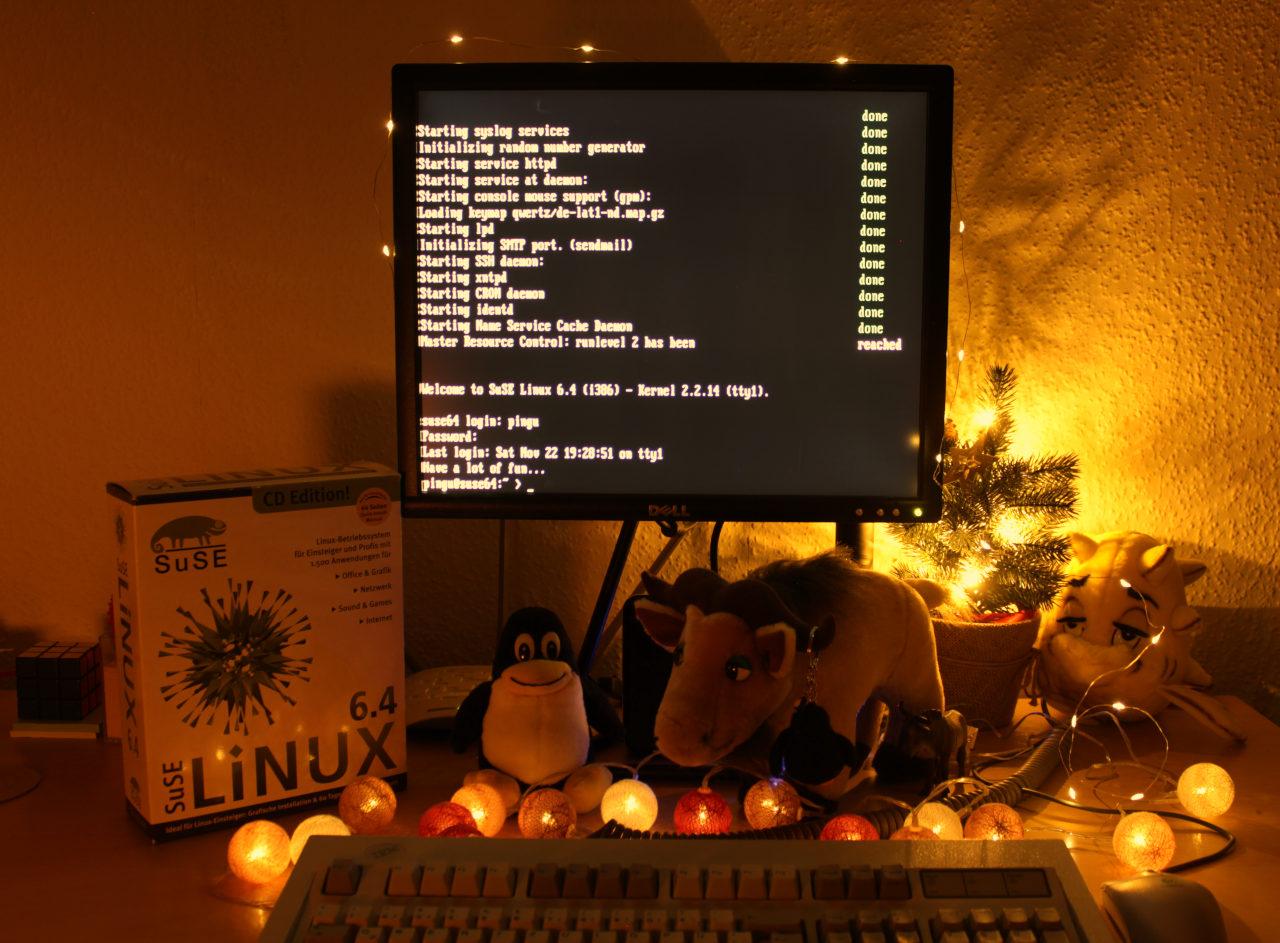
This year, I’m going to use Python 1 on SuSE Linux 6.4, writing the code on my trusty old Pentium 133 with its 64 MB of RAM. No idea if that old version of Python will be fast enough for later puzzles. We’ll see.
↳
In-reply-to
»
Yeah, how? We are facing this very problem.
⤋ Read More
@movq@www.uninformativ.de I see problems with that, yes. Case in point:

↳
In-reply-to
»
Hmmm 🧐 I'm annectodaly not convinced so-called "AI"(s) really save time™. -- I have no proof though, I would need to do some concrete studies / numbers... -- But, there is one benefit... It can save you from typing and from worsening RSI / Carpal Tunnel.
⤋ Read More
@prologic@twtxt.net AI is slot machines for coders:
- “Before starting tasks, developers forecast that allowing AI will reduce completion time by 24%. After completing the study, developers estimate that allowing AI reduced completion time by 20%. Surprisingly, we find that allowing AI actually increases completion time by 19%–AI tooling slowed developers down.” https://metr.org/blog/2025-07-10-early-2025-ai-experienced-os-dev-study/
- “Stack Overflow data reveals the hidden productivity tax of ‘almost right’ AI code”: https://venturebeat.com/ai/stack-overflow-data-reveals-the-hidden-productivity-tax-of-almost-right-ai-code
The same intermittent reward operant conditioning that gets people addicted to gambling and thinking that if they follow certain rituals they’ll win “next time” drives people’s beliefs that AI tools are making them more productive when they’re making them less productive. I’m going to guess that a side effect of this is that people think they’re typing less when in the longer term they’re typing the same amount or more when you factor in the productivity loss (as far as I’ve read the studies don’t measure this so I’m only guessing).
People are also being rapidly de-skilled by this technology: the more they use it, the more their actual skills atrophy. “Continuous exposure to AI might reduce the ADR (adesoma detection rate) of standard non-AI assisted colonoscopy, suggesting a negative effect on endoscopist behaviour.” (science speak for saying that radiologists get worse at seeing tumors in scans once they’ve used AI): https://www.thelancet.com/journals/langas/article/PIIS2468-1253(25)00133-5/abstract
Nobody who cares about the future should be using this stuff for anything.
since there are quite literally no note taking apps that work for me, i’ve began writing my own! to get started real quick i adapted the core part of bbycll’s backend and it works so nicely — which speaks volumes to the quality of the code! should really break it out into a custom framework. i’m also realizing how easy it would be to get bbycll v1 ready…but this is probably more important since it’ll allow me to get my life in order ^^’
↳
In-reply-to
»
One can tell holidays are abound; even twtxt slows down to almost a halt.
⤋ Read More
@bender@twtxt.net Once Advent of Code starts, I’ll start spamming, don’t worry. 😅
All my newly added test cases failed, that movq thankfully provided in https://git.mills.io/yarnsocial/twtxt.dev/pulls/28#issuecomment-20801 for the draft of the twt hash v2 extension. The first error was easy to see in the diff. The hashes were way too long. You’ve already guessed it, I had cut the hash from the twelfth character towards the end instead of taking the first twelve characters: hash[12:] instead of hash[:12].
After fixing this rookie mistake, the tests still all failed. Hmmm. Did I still cut the wrong twelve characters? :-? I even checked the Go reference implementation in the document itself. But it read basically the same as mine. Strange, what the heck is going on here?
Turns out that my vim replacements to transform the Python code into Go code butchered all the URLs. ;-) The order of operations matters. I first replaced the equals with colons for the subtest struct fields and then wanted to transform the RFC 3339 timestamp strings to time.Date(…) calls. So, I replaced the colons in the time with commas and spaces. Hence, my URLs then also all read https, //example.com/twtxt.txt.
But that was it. All test green. \o/
↳
In-reply-to
»
My goodness, a new level of stupidity.
⤋ Read More
I just noticed this pattern:
uninformativ.de 201.218.xxx.xxx - - [22/Nov/2025:06:53:27 +0100] "GET /projects/lariza/multipass/xiate/padme/gophcatch HTTP/1.1" 301 0 "" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36"
www.uninformativ.de 103.10.xxx.xxx - - [22/Nov/2025:06:53:28 +0100] "GET http://uninformativ.de/projects/lariza/multipass/xiate/padme/gophcatch HTTP/1.1" 400 0 "" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36"
Let me add some spaces to make it more clear:
uninformativ.de 201.218.xxx.xxx - - [22/Nov/2025:06:53:27 +0100] "GET /projects/lariza/multipass/xiate/padme/gophcatch HTTP/1.1" 301 0 "" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36"
www.uninformativ.de 103.10.xxx.xxx - - [22/Nov/2025:06:53:28 +0100] "GET http://uninformativ.de/projects/lariza/multipass/xiate/padme/gophcatch HTTP/1.1" 400 0 "" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36"
Some IP (from Brazil) requests some (non-existing, completely broken) URL from my webserver. But they use the hostname uninformativ.de, so they get redirected to www.uninformativ.de.
In the next step, just a second later, some other IP (from Nepal) issues an HTTP proxy request for the same URL.
Clearly, someone has no idea how HTTP redirects work. And clearly, they’re running their broken code on some kind of botnet all over the world.
I was looking at some ancient code and then thought: Hmm, maybe it would be a good idea to see more details in this error message. Which of the values don’t line up. On the other hand, that feature isn’t probably used anyway, because it’s a bit ugly to use (historically evolved). And on top of that, most teams need something slightly different, if they deal with that sort of thing.
I still told my workmates about it, so they could also have a look at it and we can decide tomorrow what to do about it. Speaking of the devil, no kidding, not even half an hour later, a puzzled tester contacted me. She received exactly that rather useless error message. Looks like I had an afflatus. ;-)
It’s interesting, though, that in all those years, nobody stumbled across this before. At least we now know for sure that this is not dead code. :-)
↳
In-reply-to
»
FTR, I see one (two) issues with PyQt6, sadly:
⤋ Read More
@movq@www.uninformativ.de I think I now remember having similar problems back then. I’m pretty sure I typically consulted the Qt C++ documentation and only very rarely looked at the Python one. It was easy enough to translate the C++ code to Python.
Yeah, the GIL can be problematic at times. I’m glad it wasn’t an issue for my application.
For those curious, the new Twtxt <-> ActivityPub bridge I’m building (bidirectional) simply requires three things:
- You register your Twtxt feed to the bridge: https://bridge.twtxt.net
- You verify that you in fact own/control the feed by putting the verification code somewhere on/in your feed (doesn’t matter where or how)
- You proxy/forward requests for
/.well-known/webfingerto the Bridgebridge.twtxt.net.
I’m still testing through and ironing out bugs 🐛 Please be patient! 🙏
↳
In-reply-to
»
verify: be6b4443c96a602b1947
⤋ Read More
technically I can put the Bridge verificaiton code in my feed’s metadata so no-one really ever sees or notices it 🤔 Maybe I’ll add a first-class button/field thingy in yarnd so users can “register their feed” straight from their pod? 🤔
↳
In-reply-to
»
Hmmm, looks like my twt hash algorithm implementation calculates incorrect values. Might be the tilde in the URL that throws something off. :-? At least yarnd and jenny agree on a different hash.
⤋ Read More
@lyse@lyse.isobeef.org Yeah, I noticed that too. I haven’t double-checked my code, though. Maybe it has something to do with selecting the correct URL? I mean, these feeds don’t have any # url = fields, so maybe that’s it?
↳
In-reply-to
»
Hmmm all these
⤋ Read More
tilde.club feeds have no # nick and is messing with yarnd's behavior 😅
@bender@twtxt.net Just wrote better code with tests 🤣
My goodness, a new level of stupidity.
The bots are now doing things like this:
GET http://uninformativ.de/projects/lariza/feednotify/datenstrahler/slinp/countty HTTP/1.1
- That URL does not exist.
- By including
http://uninformativ.dein that request, this instructs the webserver to do an HTTP proxy request. Of course, this isn’t allowed on my webserver (and shouldn’t by allowed on any normal webserver), resulting in HTTP 400. And even if it were, the target would be the exact same server, making a proxy request unnecessary.
And of course, it’s not just 50 hits like this or 100 or 1’000 or 10’000. No, it’s over 150’000 in the last 2 days. All from vastly different IP ranges of different cloud hosters.
This almost looks like a DDoS attack, but it’s just completely stupid. This feels more like some idiot vibe coded a crawler.
↳
In-reply-to
»
I should work on my client again and add some new features. Like adding a new feed directly in the client and not having to go to the config first. And showing a preview of a feed before actually adding it. Also, a search would be something to add. And finally combining my
⤋ Read More
User-Agent analyzer with my subscription list to spot new feeds automatically.
@lyse@lyse.isobeef.org an advent of code, I love it! Go, Lyse, go!
↳
In-reply-to
»
@bender Thanks for this illustration, it completely “misunderstood” everything I wrote and confidently spat out garbage. 👌
⤋ Read More
@prologic@twtxt.net Let’s go through it one by one. Here’s a wall of text that took me over 1.5 hours to write.
The criticism of AI as untrustworthy is a problem of misapplication, not capability.This section says AI should not be treated as an authority. This is actually just what I said, except the AI phrased/framed it like it was a counter-argument.
The AI also said that users must develop “AI literacy”, again phrasing/framing it like a counter-argument. Well, that is also just what I said. I said you should treat AI output like a random blog and you should verify the sources, yadda yadda. That is “AI literacy”, isn’t it?
My text went one step further, though: I said that when you take this requirement of “AI literacy” into account, you basically end up with a fancy search engine, with extra overhead that costs time. The AI missed/ignored this in its reply.
Okay, so, the AI also said that you should use AI tools just for drafting and brainstorming. Granted, a very rough draft of something will probably be doable. But then you have to diligently verify every little detail of this draft – okay, fine, a draft is a draft, it’s fine if it contains errors. The thing is, though, that you really must do this verification. And I claim that many people will not do it, because AI outputs look sooooo convincing, they don’t feel like a draft that needs editing.
Can you, as an expert, still use an AI draft as a basis/foundation? Yeah, probably. But here’s the kicker: You did not create that draft. You were not involved in the “thought process” behind it. When you, a human being, make a draft, you often think something like: “Okay, I want to draw a picture of a landscape and there’s going to be a little house, but for now, I’ll just put in a rough sketch of the house and add the details later.” You are aware of what you left out. When the AI did the draft, you are not aware of what’s missing – even more so when every AI output already looks like a final product. For me, personally, this makes it much harder and slower to verify such a draft, and I mentioned this in my text.
Skill Erosion vs. Skill EvolutionYou, @prologic@twtxt.net, also mentioned this in your car tyre example.
In my text, I gave two analogies: The gym analogy and the Google Translate analogy. Your car tyre example falls in the same category, but Gemini’s calculator example is different (and, again, gaslight-y, see below).
What I meant in my text: A person wants to be a programmer. To me, a programmer is a person who writes code, understands code, maintains code, writes documentation, and so on. In your example, a person who changes a car tyre would be a mechanic. Now, if you use AI to write the code and documentation for you, are you still a programmer? If you have no understanding of said code, are you a programmer? A person who does not know how to change a car tyre, is that still a mechanic?
No, you’re something else. You should not be hired as a programmer or a mechanic.
Yes, that is “skill evolution” – which is pretty much my point! But the AI framed it like a counter-argument. It didn’t understand my text.
(But what if that’s our future? What if all programming will look like that in some years? I claim: It’s not possible. If you don’t know how to program, then you don’t know how to read/understand code written by an AI. You are something else, but you’re not a programmer. It might be valid to be something else – but that wasn’t my point, my point was that you’re not a bloody programmer.)
Gemini’s calculator example is garbage, I think. Crunching numbers and doing mathematics (i.e., “complex problem-solving”) are two different things. Just because you now have a calculator, doesn’t mean it’ll free you up to do mathematical proofs or whatever.
What would have worked is this: Let’s say you’re an accountant and you sum up spendings. Without a calculator, this takes a lot of time and is error prone. But when you have one, you can work faster. But once again, there’s a little gaslight-y detail: A calculator is correct. Yes, it could have “bugs” (hello Intel FDIV), but its design actually properly calculates numbers. AI, on the other hand, does not understand a thing (our current AI, that is), it’s just a statistical model. So, this modified example (“accountant with a calculator”) would actually have to be phrased like this: Suppose there’s an accountant and you give her a magic box that spits out the correct result in, what, I don’t know, 70-90% of the time. The accountant couldn’t rely on this box now, could she? She’d either have to double-check everything or accept possibly wrong results. And that is how I feel like when I work with AI tools.
Gemini has no idea that its calculator example doesn’t make sense. It just spits out some generic “argument” that it picked up on some website.
3. The Technical and Legal Perspective (Scraping and Copyright)The AI makes two points here. The first one, I might actually agree with (“bad bot behavior is not the fault of AI itself”).
The second point is, once again, gaslighting, because it is phrased/framed like a counter-argument. It implies that I said something which I didn’t. Like the AI, I said that you would have to adjust the copyright law! At the same time, the AI answer didn’t even question whether it’s okay to break the current law or not. It just said “lol yeah, change the laws”. (I wonder in what way the laws would have to be changed in the AI’s “opinion”, because some of these changes could kill some business opportunities – or the laws would have to have special AI clauses that only benefit the AI techbros. But I digress, that wasn’t part of Gemini’s answer.)
tl;drExcept for one point, I don’t accept any of Gemini’s “criticism”. It didn’t pick up on lots of details, ignored arguments, and I can just instinctively tell that this thing does not understand anything it wrote (which is correct, it’s just a statistical model).
And it framed everything like a counter-argument, while actually repeating what I said. That’s gaslighting: When Alice says “the sky is blue” and Bob replies with “why do you say the sky is purple?!”
But it sure looks convincing, doesn’t it?
Never againThis took so much of my time. I won’t do this again. 😂
↳
In-reply-to
»
@bender Thanks for this illustration, it completely “misunderstood” everything I wrote and confidently spat out garbage. 👌
⤋ Read More
@movq@www.uninformativ.de this I find more worrisome, and saw no mention of it on your text: Right-Wing Chatbots Turbocharge America’s Political and Cultural Wars (gift article).
Enoch, one of the newer chatbots powered by artificial intelligence, promises “to ‘mind wipe’ the pro-pharma bias” from its answers. Another, Arya, produces content based on instructions that tell it to be an “unapologetic right-wing nationalist Christian A.I. model.”