published: ‘You don’t have to maintain server to run open source software’ https://copyleftculture.com//using-open-source.html
published: ‘Why do I use copyleft-licensed software?’ https://copyleftculture.com/why-copyleft.html
↳
In-reply-to
»
Wait! What's going on?! 🧐
⤋ Read More
@prologic@twtxt.net Gemini has an answer for you:
This is a conversation thread from a twtxt network, detailing a user’s (movq) frustration with the Mastodon “export data” feature and their consideration of self-hosting a fediverse alternative. Here’s a summary:
- movq’s initial issue:
- movq is concerned about the volatility of their data on their current Mastodon instance due to a broken “export data” feature.
- They contacted the admins, but the issue remains unresolved.
- This led them to contemplate self-hosting.
- movq is concerned about the volatility of their data on their current Mastodon instance due to a broken “export data” feature.
- Alternative fediverse software suggestions:
- kat suggests gotosocial as a lightweight alternative to Mastodon.
- movq agrees, and also mentions snac as a potential option.
- kat suggests gotosocial as a lightweight alternative to Mastodon.
- movq’s change of heart:
- movq ultimately decides that self-hosting any fediverse software, besides twtxt, is too much effort.
- movq ultimately decides that self-hosting any fediverse software, besides twtxt, is too much effort.
- Resolution and compromise:
- The Mastodon admins attribute the export failure to the size of movq’s account.
- movq decides to set their Mastodon account to auto-delete posts after approximately 180 days to manage data size.
- Movq also mentions that they use auto-expiring links on twtxt to reduce data storage.
- The Mastodon admins attribute the export failure to the size of movq’s account.
I now subscribed to most feeds in my Go tt reimplementation that I already followed with the old Python tt. Previously, I just had a few feeds for testing purposes in my new config. While transfering, I “dropped” heaps of feeds that appeared to be inactive.
This might motivate me to actually “finish” the new client, so that it could become my daily driver. No need to use the old software stack any longer. Let’s see how bad this goes.
↳
In-reply-to
»
When will the flat UI craze end? Can I get my buttons, scrollbars, and toolbars back, please?
⤋ Read More
Although, most software I use is decentish in that regard.
Is that because you mostly use Qt programs? 🤔
I wish Qt had a C API. Programming in C++ is pain. 😢
↳
In-reply-to
»
When will the flat UI craze end? Can I get my buttons, scrollbars, and toolbars back, please?
⤋ Read More
@movq@www.uninformativ.de Where can I join your club? Although, most software I use is decentish in that regard.
I just noted today that JetBrains improv^Wcompletely fucked up their new commit dialog. There’s no diff anymore where I would also be able to select which changes to stage. I guess from now on I’m going to exclusively commit from only the shell. No bloody git integration anymore. >:-( This is so useless now, unbelievable.
↳
In-reply-to
»
I think I should try self-hosting some Mastodon thingy again.
⤋ Read More
@movq@www.uninformativ.de mastodon is probably the worst fedi software to self host tbh, you might wanna check out gotosocial? not to like pull you in another direction but idk masto is just suuuuper heavy lol
↳
In-reply-to
»
What does the #twtxt community think about having a p2p database to store all history? This will be managed by Registries.
⤋ Read More
@prologic@twtxt.net If it develops, and I’m not saying it will happen soon, perhaps Yarn could be connected as an additional node. Implementation would not be difficult for any client or software. It will not only be a backup of twtxt, but it will be the source for search, discovery and network health.
↳
In-reply-to
»
@prologic We can't agree on this idea because that makes things even more complicated than it already is today. The beauty of twtxt is, you put one file on your server, done. One. Not five million. Granted, there might be archive feeds, so it might be already a bit more, but still faaaaaaar less than one file per message.
⤋ Read More
If we don’t keep insisting on simplify and “The beauty of twtxt is, you put one file on your server, done. One.”, then people should just use ActivityPub-based software like Mastodon, PixelFed, etc. which are getting a lot of attention and uses migrating to the fediverse from meta/x here in Denmark over the last couple of months.
Comparing Fuchsia components and Linux containers
Fuchsia is a new (non-Linux) operating system from Google, and one of the key pieces of Fuchsia’s design is the component framework. Components on Fuchsia have many similarities with some of the container solutions on Linux (such as Docker): they both fetch content addressed blobs from the network, assemble those blobs into an isolated filesystem structure that holds all the dependencies necessary to run some piece of software, and … ⌘ Read more
Hacer software código opensource es desafiante y paulatinamente desgasta a su autor. Todo comienza con pasión y entusiasmo, por supuesto. Si logras repercusión, te enfrentas a una carrera de fondo que muchos terminan abandonando por las demandas constantes de usuarios que, a menudo, no valoran el trabajo ni contribuyen de manera significativa. Por mencionar un caso reciente: Hector Martin. Líder del proyecto Asahi Linux, quien dedicó años a adaptar Linux para los procesadores Apple Silicon, un logro técnico impresionante. Sin embargo, terminó renunciando debido a la presión de usuarios que exigían soporte y mejoras como si fueran clientes pagos.
La mayoría de los mantenedores no reciben ningún soporte económico. Solo unos pocos proyectos logran sostenibilidad financiera a través de patrocinios, mientras que la mayoría de los desarrolladores terminan con un segundo empleo no remunerado.
Sin un cambio en la forma en que se valora y apoya los proyectos Opensource, y no solo hablo de las grandes empresas multimillonarias. Sería una perdida para todos si acabaremos con un ecosistema de software archivado y abandonado.
Ahora te paso la pelota a ti, ¿cuando fue la última vez que apoyaste a un mantenedor de software opensource?
Blender-Rendered Movie ‘Flow’ Wins Oscar for Best Animated Feature, Beating Pixar
It’s a feature-length film “rendered on a free and open-source software platform called Blender,” reports Reuters. And it just won the Oscar for best animated feature film, beating movies from major studios like Disney/Pixar and Dreamworks.
In January Blender.org called Flow “the manifestation of Blender’s mission, … ⌘ Read more
Reading into the so-called CLEAN architecture reminds me of the work I did nearly two decades earlier called circuits hmmm 🧐
I read a lot about Clean Code, SOLID, TDD, DDD… now I’m discovering «A Philosophy of Software Design»… but nobody talks about the importance of the project architecture. Do we depend on the framework to do the work for us?
You know I’m a big fan of Clean Architecture, but I feel alone when I share my thoughts on social media or at work.
You have to think outside the framework.
I like gopher so far. Probably gonna increment the amount of gopher servers by 1 soon. Could also make custom client and server software for it, since it’s so simple.
Qualcomm gives OEMs the option of 8 years of Android updates
Starting with Android smartphones running on the Snapdragon 8 Elite Mobile Platform, Qualcomm Technologies now offers device manufacturers the ability to provide support for up to eight consecutive years of Android software and security updates. Smartphones launching on new Snapdragon 8 and 7-series mobile platforms will also be eligible to receive this extended support. ↫ Mike Genewich I mean, good news of cou … ⌘ Read more
1972 UNIX V2 “beta” resurrected from old tapes
There’s a number of backups of old DECtapes from Dennis Ritchie, which he gave to Warren Toomey in 1997. The tapes were eventually uploaded, and through analysis performed by Yufeng Gao, a lot of additional details, code, and software were recovered from them. A few days ago, Gao came back with the results from their analys of two more tapes, and on it, they found something quite special. Getting this recovered version to run was a bit of a … ⌘ Read more
NES86: x86 emulation on the NES
The goal of this project is to emulate an Intel 8086 processor and supporting PC hardware well enough to run the Embeddable Linux Kernel Subset (ELKS), including a shell and utilities. It should be possible to run other x86 software as long as it doesn’t require more than a simple serial terminal. ↫ NES86 GitHub page Is this useful in any meaningful sense? No. Will this change the word? No. Does it have any other purpose than just being fun and cool? Nope. None of that … ⌘ Read more
I finally got Ubuntu Software to find Kolourpaint and it installed, now when I run the APP nothing happens.
Dead, zip narda.
Stupid program , what is wrong?
AIDA64 drops support for Windows 95, 98, and ME
AIDA64, the popular benchmarking tool for Windows, released a new version today. I don’t particularly care about benchmarking – even less so benchmarking on Windows – but this new release comes with an interesting line in the release notes. Discontinued support for Windows 95, 98, Me ↫ AIDA64 v7.60 release notes Seeing a widely-used, popular piece of software drop support for Windows 95, 98, and ME only in this, the year of our lord, 2025 … ⌘ Read more
NASA has a list of 10 rules for software development https://www.cs.otago.ac.nz/cosc345/resources/nasa-10-rules.htm
Yesterday I was doing a lot of research on how #hyperdrive and the #holepunch project work. Would it be possible to use it to make #twtxt an easier gateway for new users? Could we stop using web servers?
My conclusion: We would end up being a #nostr. On the one hand it would become more complex to use, it would force the user to have software installed, and on the other hand the community would need a central proxy to make the routes accessible via HTTP. In other words, it’s not a good idea.
However, it’s an AMAZING technology. I want to start playing with it.
↳
In-reply-to
»
I have uploaded a new version of #twtxtel 🥳. It's now possible to view profiles, either your own or others. #twtxt #emacs Media @prologic @xuu
⤋ Read More
@xuu@txt.sour.is Thank you! A common mistake is to see Emacs as a text editor but it’s a Lisp interpreter with a text editor (among other software), so the limit is your imagination 😋. I’m glad you like it! 🙌
Cassette: a POSIX application framework featuring a retro-futurist GUI toolkit
Cassette is a GUI application framework written in C11, with a UI inspired by the cassette-futurism aesthetic. Built for modern POSIX systems, it’s made out of three libraries: CGUI, CCFG and COBJ. Cassette is free and open-source software, licensed under the LGPL-3.0. ↫ Cassette GitHub page Upon first reading this description, you might wonder what a “cassette-futurism aesthe … ⌘ Read more
SDL 3.2.0 released
SDL, the Simple DirectMedia Layer, has released version 3.2.0 of its development library. In case you don’t know what SDL is: Simple DirectMedia Layer is a cross-platform development library designed to provide low level access to audio, keyboard, mouse, joystick, and graphics hardware via OpenGL and Direct3D. It is used by video playback software, emulators, and popular games including Valve‘s award winning catalog and many Humble Bundle games. ↫ SDL website This new release has a lot of impr … ⌘ Read more
Right to root access
I believe consumers, as a right, should be able to install software of their choosing to any computing device that is owned outright. This should apply regardless of the computer’s form factor. In addition to traditional computing devices like PCs and laptops, this right should apply to devices like mobile phones, “smart home” appliances, and even industrial equipment like tractors. In 2025, we’re ultra-connected via a network of devices we do not have full control over. Much of this has t … ⌘ Read more
↳
In-reply-to
»
I am now using Streamlit at work to build admin interfaces and some internal application. It's amazing! I recommend it
⤋ Read More
@prologic@twtxt.net It’s opensource. You can run the software in your localhost or server. Cloud service is a free option.
↳
In-reply-to
»
should put together my new pi and set up the DIY KVM thing i'm doing but ehhh tired
⤋ Read More
@prologic@twtxt.net YESSS i’m gonna be using tiny pilot’s software on mine! i was inspired by jet too but mine won’t look nearly as cool lol
↳
In-reply-to
»
changing my video site's logo to this silly no thoughts head empty tux clip art. because i can. https://openclipart.org/detail/103855/tux-the-penguin
⤋ Read More
@kat@yarn.girlonthemoon.xyz after some fighting with this janky software (that i still love despite the jank) we now have stupid tux as our logo. slayyy
Acabo de descubrir este software y está genial https://kristall.random-projects.net/ 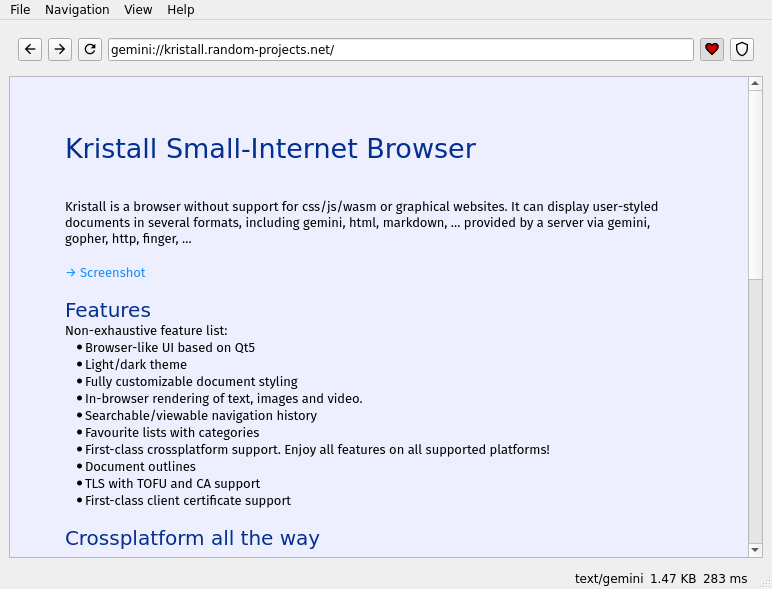
↳
In-reply-to
»
Are there any good Registry? I like to check the mentions.
⤋ Read More
I found 2 active Registries: tilde.instite and twtxt.envs.net . I think that is missing a repository or system for them to find each other. It is easy to share registry users. Your work is awesome! Maybe you are supporting twtxt with the pod and software around them. I am very busy with the Emacs client, but I like to work creating my own version of Registry using Django.
↳
In-reply-to
»
@eapl.me A way to have a more bluesky'ish handles in twtxt could be to take inspiration from Bridgy Fed and say:
⤋ Read More
If NICK = DOMAIN then only show @DOMAIN
So instead of @eapl.me@eapl.me it will just be @eapl.me
I’m just having a similar issue with a podcast I just uploaded on Castopod (which supports ActivityPub).
My first thought was creating a subdomain with the name of the podcast mordiscos.eapl.me
Then I watched that the software allows many podcasts in the same domain, so I had to pick a handle:
https://mordiscos.eapl.me/@podcast
So now I have @podcast@mordiscos.eapl.me when this one is ‘more correct’ @mordiscos@podcast.eapl.me or it could even be @mordiscos.eapl.me
I wasn’t aware of all that when I setup Castopod (documentation might improve a lot, IMO)
My point here is that it’s something important to think from the start, otherwise is painful to change if it’s already being used like that.
One thing I’ve learned over the many years now (approaching a decade and a half now) about self-hosting is two things; 1) There are many “assholes” on the open Internet that will either attack your stuff or are incompetent and write stupid shit™ that goes crazy on your stuff 2) You have to be careful about resources, especially memory and disk i/o. Especially disk i/o. this can kill your overall performance when you either have written software yourself or use someone else’s that can do unconfined/uncontrolled disk i/o causing everything to grind to a halt and even fail. #self-hosted
↳
In-reply-to
»
Goodbye Blender, I guess? 🤔
⤋ Read More
@aelaraji@aelaraji.com will all those run on his hardware? I don’t think @movq@www.uninformativ.de’s problem is the software, it is that his hardware has gotten too old. :-D
↳
In-reply-to
»
Forcing social media to open their algorithms: hostile to corporations
Forcing young people to not use social media: hostile to young people, helps prevent them from organizing
You think they did this for the benefit of the young people?
⤋ Read More
Btw about social: found very interesting thing about twitter:
The legal basis that X asserts in the filing is not terribly interesting. But what is interesting is that X has decided to involve itself at all, and it highlights that you do not own your followers or your account or anything at all on corporate social media, and it also highlights the fact that Elon Musk’s X is primarily a political project he is using to boost, or stifle, specific viewpoints and help his friends. In the filing, X’s lawyers essentially say—like many other software companies, and, increasingly, device manufacturers as well—that the company’s terms of service grant X’s users a “license” to use the platform but that, ultimately, X owns all accounts on the social network and can do anything that it wants with them.
all of the software sucks, but i have a solution! we’ll write even more software! get more people involved, make it the Ideal Career, then we can write AL̵L̴ O̵F TH̨E ̧C̀ODE̷S. mountains of shitty garbage that kind-of does the thing. software will still suck, but T͜HE̕N oh then we can write compilers that let us run the old shitty code inside of our mountain of new shitty code. now all of the code is in a giant pile and we’re using it to control space ships that definitely never crash. the more code the better! we can represent NaN easily in undefined systems! developers aren’t particularly bright, so the language is simple and easy for them to understand. we know this, that’s why it was made this way. the͡ moun͢tain ͠m̵us͜t ͠nȩver̢ ̴wa̡ve̴r̵. the more code the better. so instead of writing the code manually we c̴ómpilę t͞or̸t̕u͜red so̷u͜ls ͏i͞n͞to͝ ͟nice ͢b̀l̷oxe̡ls ̸of͠ ̸t̶an̡g͜l̀ed ͞n̢eu͏ra̡l͠ ̕ne̢t͏w͟orkś.̸ w̨e d͠on’t́ know how i̵t ̷w͟ork̡s, ̴but ̷t̴he model̢ ̶is̛ 5̛0GiB ́s̶o ͟i͞t s͞e͘rve͟s ̴tḩe̛ purpośe. WE̕ M͠US̴T B͢U̢ILD ͝T͞HE MO͝UN̶T̨A̵IN.
@prologic@twtxt.net to interact with locally running LLM, which software are you using? LM Studio, or Ollama, or…?
↳
In-reply-to
»
I don’t think calling the various PHP files making up “Timeline” a “Yarn pod” is accurate.
⤋ Read More
@bender@twtxt.net 😆 Would calling it a Single user Twtxt "Yarn Pod **Like**" software help you sleep better at night? And just in case things are not clear here, I’m being sarcastic (well, kinda…) and not trying to gaslight anyone. Think of my comment as Bromance or something like that LOL.
But seriously, Just like any UNIX-Like system to Unix™, as in non of them are UNIX™, but each of them is providing more or less similar experience and re-implementing what once was parts of “UNIX™ software” their own (more or less better) ways. Timeline is Yarn™ Pod like, (my personal take on the word pod is: “an instance of XYZ software acting an escape POD from X-BS for… ABC reasons.”) providing more or less of a similar experience, implementing some of Yarn.social Extensions, trying to add in some more …etc.
Otherwise, I don’t see the Yarn pod mention as some kind of malicious manoeuvre, but more of a tribute to what (might have) sparked inspiration for creating Timeline? Also, our friend @sorenpeter@darch.dk here has got a valid reason for using PHP (#tms7aka) so let’s let’s put our unease towards the language itself aside and maybe just help however/as much as we can in order to make internet (the World?) a better place.
↳
In-reply-to
»
So I am really curious, now that I am building upon @sorenpeter's Timeline app, how other users write/add their twtxt, and how you follow conversations. Comment svp!
⤋ Read More
Hey, @ I know. Just wondering the kind of apps or software and how you all stay up to date in conversations. Is it through webmentions?
↳
In-reply-to
»
Simplified twtxt - I want to suggest some dogmas or commandments for twtxt, from where we can work our way back to how to implement different feature like replies/treads:
⤋ Read More
@Codebuzz@www.codebuzz.nl Speed is an issue for the client software, not the format itself, but yes I agree that it makes the most sense to append post to the end of the file. I’m referring to the definition that it’s the first url = in the file that is the one that has to be used for the twthash computation, which is a too arbitrary way of defining something that breaks treading time and time again. And this is the case for not using url+date+message = twthash.
↳
In-reply-to
»
I'm not even supposed to do be doing any of this, I should be making stuff* with Shapes, forms and color instead of poking at software with a stick like a caveman. 😆
⤋ Read More
Alas, I can’t get myself to resist. Interacting with tech and software makes me feel like a kid in a candy shop: “I wanna taste all of it! Find my favorite Lollipop and wonder about where it came from, who made it? How is it possible to turn any kind of mushy juicy fruit into a hard, forever lasting candy in a freaking stick!? Oh, Wait!! Is THAT chocolate over there!!?”
I’m not even supposed to do be doing any of this, I should be making stuff* with Shapes, forms and color instead of poking at software with a stick like a caveman. 😆
*Stuff: Things I make and refuse to call Art, unless I have to in a resume and what not.
↳
In-reply-to
»
Yeah I know! My ship was sinking and I've just noticed. Patched up the holes and now we're back afloat.
⤋ Read More
@movq@www.uninformativ.de Although my recent breakage/down time was more of a result of human error than it is something to blame on software itself, I do get your point; and will highly probably end up going the same route in the near future. It’s just that in order to south my forever itching curiosity, I have to learn and try some things first.
Gentlemen, I have a pdf file (1.5MB) which I want to be able to block and copy text writing out of it, but it’s locked, preventing this. All I used to do was write it out by hand, or screen shot the text as an image.
Is there any software that opens pdf format for copying and pasting of the text?
More thoughts about changes to twtxt (as if we haven’t had enough thoughts):
- There are lots of great ideas here! Is there a benefit to putting them all into one document? Seems to me this could more easily be a bunch of separate efforts that can progress at their own pace:
1a. Better and longer hashes.
1b. New possibly-controversial ideas like edit: and delete: and location-based references as an alternative to hashes.
1c. Best practices, e.g. Content-Type: text/plain; charset=utf-8
1d. Stuff already described at dev.twtxt.net that doesn’t need any changes.
We won’t know what will and won’t work until we try them. So I’m inclined to think of this as a bunch of draft ideas. Maybe later when we’ve seen it play out it could make sense to define a group of recommended twtxt extensions and give them a name.
Another reason for 1 (above) is: I like the current situation where all you need to get started is these two short and simple documents:
https://twtxt.readthedocs.io/en/latest/user/twtxtfile.html
https://twtxt.readthedocs.io/en/latest/user/discoverability.html
and everything else is an extension for anyone interested. (Deprecating non-UTC times seems reasonable to me, though.) Having a big long “twtxt v2” document seems less inviting to people looking for something simple. (@prologic@twtxt.net you mentioned an anonymous comment “you’ve ruined twtxt” and while I don’t completely agree with that commenter’s sentiment, I would feel like twtxt had lost something if it moved away from having a super-simple core.)All that being said, these are just my opinions, and I’m not doing the work of writing software or drafting proposals. Maybe I will at some point, but until then, if you’re actually implementing things, you’re in charge of what you decide to make, and I’m grateful for the work.
↳
In-reply-to
»
Okay folks, I've spent all day on this today, and I think its in "good enough"™ shape to share:
⤋ Read More
@prologic@twtxt.net Thanks for writing that up!
I hope it can remain a living document (or sequence of draft revisions) for a good long time while we figure out how this stuff works in practice.
I am not sure how I feel about all this being done at once, vs. letting conventions arise.
For example, even today I could reply to twt abc1234 with “(#abc1234) Edit: …” and I think all you humans would understand it as an edit to (#abc1234). Maybe eventually it would become a common enough convention that clients would start to support it explicitly.
Similarly we could just start using 11-digit hashes. We should iron out whether it’s sha256 or whatever but there’s no need get all the other stuff right at the same time.
I have similar thoughts about how some users could try out location-based replies in a backward-compatible way (append the replyto: stuff after the legacy (#hash) style).
However I recognize that I’m not the one implementing this stuff, and it’s less work to just have everything determined up front.
Misc comments (I haven’t read the whole thing):
Did you mean to make hashes hexadecimal? You lose 11 bits that way compared to base32. I’d suggest gaining 11 bits with base64 instead.
“Clients MUST preserve the original hash” — do you mean they MUST preserve the original twt?
Thanks for phrasing the bit about deletions so neutrally.
I don’t like the MUST in “Clients MUST follow the chain of reply-to references…”. If someone writes a client as a 40-line shell script that requires the user to piece together the threading themselves, IMO we shouldn’t declare the client non-conforming just because they didn’t get to all the bells and whistles.
Similarly I don’t like the MUST for user agents. For one thing, you might want to fetch a feed without revealing your identty. Also, it raises the bar for a minimal implementation (I’m again thinking again of the 40-line shell script).
For “who follows” lists: why must the long, random tokens be only valid for a limited time? Do you have a scenario in mind where they could leak?
Why can’t feeds be served over HTTP/1.0? Again, thinking about simple software. I recently tried implementing HTTP/1.1 and it wasn’t too bad, but 1.0 would have been slightly simpler.
Why get into the nitty-gritty about caching headers? This seems like generic advice for HTTP servers and clients.
I’m a little sad about other protocols being not recommended.
I don’t know how I feel about including markdown. I don’t mind too much that yarn users emit twts full of markdown, but I’m more of a plain text kind of person. Also it adds to the length. I wonder if putting a separate document would make more sense; that would also help with the length.
↳
In-reply-to
»
(#lryyjla) @quark My money is on a SHA1SUM hash encoding to keep things much simpler:
⤋ Read More
@prologic@twtxt.net Wikipedia claims sha1 is vulnerable to a “chosen-prefix attack”, which I gather means I can write any two twts I like, and then cause them to have the exact same sha1 hash by appending something. I guess a twt ending in random junk might look suspcious, but perhaps the junk could be worked into an image URL like  . If that’s not possible now maybe it will be later.
. If that’s not possible now maybe it will be later.
git only uses sha1 because they’re stuck with it: migrating is very hard. There was an effort to move git to sha256 but I don’t know its status. I think there is progress being made with Game Of Trees, a git clone that uses the same on-disk format.
I can’t imagine any benefit to using sha1, except that maybe some very old software might support sha1 but not sha256.
We need more support summer software :(
↳
In-reply-to
»
On the Subject of Feed Identities; I propose the following:
⤋ Read More
@mckinley@twtxt.net To answer some of your questions:
Are SSH signatures standardized and are there robust software libraries that can handle them? We’ll need a library in at least Python and Go to provide verified feed support with the currently used clients.
We already have this. Ed25519 libraries exist for all major languages. Aside from using ssh-keygen -Y sign and ssh-keygen -Y verify, you can also use the salty CLI itself (https://git.mills.io/prologic/salty), and I’m sure there are other command-line tools that could be used too.
If we all implemented this, every twt hash would suddenly change and every conversation thread we’ve ever had would at least lose its opening post.
Yes. This would happen, so we’d have to make a decision around this, either a) a cut-off point or b) some way to progressively transition.
If some of you budding fathers want to know how I created a computer nerd to one day work for Facebook in the big USA, well you purchase a $1000 Xmas present, an enormous thick book with C++ programming, and say, you can play as many games as you like kids, but James has to create them using computer software.
SO James created once a 3D chess program with sound, took 6 months or so, really hard to beat, not based on logic moves point by point like other chess programs, this one was based on the depth of looking for patterns, set it to 5 moves ahead and you were toast every time. Nice program too, sadly gone over the years, computers suffer from bit rot. We used to try and mark rotten hard drive discs once as bad sectors, not sure how UBuntu does this these days, I see a dozen errors on the screen every time I load.
Today I would purchase for my kids AI CAD simulation software with metal 3D printer and get your child to build fancy 3D models and engines from scratch. This will make them an expert in the CAD AI industry by the time they are 14 years old. Sadly AI is here to stay and will spoil the Internet.