↳
In-reply-to
»
@bender Really? 🤔
⤋ Read More
@prologic@twtxt.net the simplest thing to do is to completely forgo hashing anything because we are communicating using plain text files right now :3 while i agree hashes are incredibly helpful in the backend im not sure it has a place outside of it, it basically eliminates two core design principals of twtxt (human readability and integrating well with unix command line utilities) and makes new clients more difficult to build than it should be
↳
In-reply-to
»
I just created a zs blogging template which I'm going to use for https://prologic.blog and I might starting writing long-form again soon™ 🔜 So far the "blogging" template/engine (if you weill) is quite simple. It comprises essentially of an
⤋ Read More
index.md a prehook and a few utilities:
@bender@twtxt.net Yes I did about a week or so ago. It took me a lot of effort to get the content even rendered in the first place. LOL I had to basically export my blog as HTML (can you believe that?!) – The Hugo export just didn’t work at all 🤣
↳
In-reply-to
»
mobile navigation bar :3
⤋ Read More
@zvava@twtxt.net love the direction this is heading, hope this soon evolves into a basic Android app, usable with any instance.
↳
In-reply-to
»
@dce You should try los86! 8-)
⤋ Read More
@lyse@lyse.isobeef.org I’m looking for an OS that runs better than Windows (🤮) and through which I can do basic stuff like read RSS feeds and browse geminispace; but which I can also learn from.
Hmm, gnu.org is slow as heck. Shorter HTML pages load in about ten seconds. This complete AWK manual all in one large HTML page took a full minute: https://www.gnu.org/software/gawk/manual/gawk.html Is there maybe some anti AI shenanigans going on?
In any case, I find the user guide super interesting. My AWK skills are basically non-existent, so I finally decided to change that. This document is incredibly well written and makes it really fun to keep reading and learning. I’m very impressed. So far, I made it to section 1.6, happy to continue.
↳
In-reply-to
»
Welp, my rent's gone out and my student loan won't be in for another week, so I'm not spending anything for a while. How's everyone else's September going?
⤋ Read More
@dce@hashnix.club Ooops 😅 Hope you still have enough money for the basics 🤗 I’m doing okay though!
↳
In-reply-to
»
The bots have begun to access my website way more often. I’m getting about 120k hits on https://www.uninformativ.de/git/ now in a couple of hours.
⤋ Read More
@movq@www.uninformativ.de Right now I’m basically just blocking entire ASN(s) at this point and large blocks of IP(s) from Anthropic, OPenAI, Microsoft and others.
Distrobox is pretty handy and kind of amazed I haven’t played with it before now. I wanted to quickly try out Proton’s Authenticator they just released, but they only had binaries for Ubuntu and Fedora (naturally), but I’m on Void Linux on this laptop.
Installed the latest basic Fedora image with Distrobox, used dnf to install the downloaded rpm file within it, and presto, running the app within Void like I’d just downloaded it though the normal repos.
Desktop SSH->Pinephone->here. This is crazy. Sxmo is the best UI for the Pinephone, and maybe phones in general. Insane: basically dwm on a phone with gestures and built-in yt-dlp + mpv (among others).
This setup is so handy (and smart) for some cases. It basically “flips” the container netns architecture. Cool as hell.
↳
In-reply-to
»
Been spending a lot of time researching campers as I want to / plan to upgrade our current Camper Trailoer (forward fold) Stoney Creek XL-FF6 to a slightly larger Hybrid Camper/Caravan with ensuite, internal kitchenette, external full hitchen, pop-top roof and twin bunks.
⤋ Read More
@prologic@twtxt.net well, the ones down there (on your list) are pretty minimal, basic even. Yet, their pricing is super high (number wise, haven’t checked the equivalent from AUD to USD).
Someone did a thing:
https://social.treehouse.systems/@ariadne/114763322251054485
I’ve been silently wondering all the time if this was possible, but never investigated: Keep doing X11 but use Wayland as a backend.
This uses XWayland’s “rootful” mode, which basically just gives you a normal Wayland window with all the X11 stuff happening inside of it:
https://www.phoronix.com/news/XWayland-Rootful-Useful
In other words, put such a window in fullscreen and you (more or less) have good old X11 running in a Wayland window.
(For me, personally, this won’t be the way forward. But it’s a very interesting project.)
↳
In-reply-to
»
OH, FUCK ME DEAD! On the way home from today's walk I saw easily 800 fireflies! Yes, over eight hundred! That was absolutely amazing. First time this year and already this many. Crazy! They were just fricking everywhere in the entire forest. I counted to one hundred and then stopped. The darker it got, the more fireflies came out and glowed around. :-) There were spots where in under ten seconds I counted 20 glowworms. Super sick. Soooo beautiful. <3
⤋ Read More
Hahaha, I’m sure there were well over one thousand fireflies today! Basically at all times I could watch at least 15 of them around me. At better spots where one could see a few meters into the forest, there were easily 30 individuals, probably more. One even landed on my small finger. I didn’t feel anything at all, but my finger glowed. :-) Awwww! After a 20 meters ride it took off.
But it looks like I have to go already at 21:30 at sunset the next days. Today, I left the house at 22:00 and all the above happend in the first half. The second half of the walk was rather boring, maybe just around 70 glowworms in total. The extremely busy route yesterday was virtually dead this time I came around. They all have already gone to sleep, or something like that.
I also encountered two toads. I nearly stepped on the first one, but it luckily jumped to the side in time. No animals harmed.
I did a “lecture”/“workshop” about this at work today. 16-bit DOS, real mode. 💾 Pretty cool and the audience (devs and sysadmins) seemed quite interested. 🥳
- People used the Intel docs to figure out the instruction encodings.
- Then they wrote a little DOS program that exits with a return code and they used uhex in DOSBox to do that. Yes, we wrote a COM file manually, no Assembler involved. (Many of them had never used DOS before.)
- DEBUG from FreeDOS was used to single-step through the program, showing what it does.
- This gets tedious rather quickly, so we switched to SVED from SvarDOS for writing the rest of the program in Assembly language. nasm worked great for us.
- At the end, we switched to BIOS calls instead of DOS syscalls to demonstrate that the same binary COM file works on another OS. Also a good opportunity to talk about bootloaders a little bit.
- (I think they even understood the basics of segmentation in the end.)
The 8086 / 16-bit real-mode DOS is a great platform to explain a lot of the fundamentals without having to deal with OS semantics or executable file formats.
Now that was a lot of fun. 🥳 It’s very rare that we do something like this, sadly. I love doing this kind of low-level stuff.
Okay, here’s a thing I like about Rust: Returning things as Option and error handling. (Or the more complex Result, but it’s easier to explain with Option.)
fn mydiv(num: f64, denom: f64) -> Option<f64> {
// (Let’s ignore precision issues for a second.)
if denom == 0.0 {
return None;
} else {
return Some(num / denom);
}
}
fn main() {
// Explicit, verbose version:
let num: f64 = 123.0;
let denom: f64 = 456.0;
let wrapped_res = mydiv(num, denom);
if wrapped_res.is_some() {
println!("Unwrapped result: {}", wrapped_res.unwrap());
}
// Shorter version using "if let":
if let Some(res) = mydiv(123.0, 456.0) {
println!("Here’s a result: {}", res);
}
if let Some(res) = mydiv(123.0, 0.0) {
println!("Huh, we divided by zero? This never happens. {}", res);
}
}
You can’t divide by zero, so the function returns an “error” in that case. (Option isn’t really used for errors, IIUC, but the basic idea is the same for Result.)
Option is an enum. It can have the value Some or None. In the case of Some, you can attach additional data to the enum. In this case, we are attaching a floating point value.
The caller then has to decide: Is the value None or Some? Did the function succeed or not? If it is Some, the caller can do .unwrap() on this enum to get the inner value (the floating point value). If you do .unwrap() on a None value, the program will panic and die.
The if let version using destructuring is much shorter and, once you got used to it, actually quite nice.
Now the trick is that you must somehow handle these two cases. You must either call something like .unwrap() or do destructuring or something, otherwise you can’t access the attached value at all. As I understand it, it is impossible to just completely ignore error cases. And the compiler enforces it.
(In case of Result, the compiler would warn you if you ignore the return value entirely. So something like doing write() and then ignoring the return value would be caught as well.)
↳
In-reply-to
»
Gopher server is back online and I’ll be phasing out Mastodon.
⤋ Read More
@bender@twtxt.net Both Gopher and Mastodon are a way for me to “babble”. 😅 I basically shut down Gopher in favor of Mastodon/Fedi last year. But the Fediverse doesn’t really work for me. It’s too focused on people (I prefer topics) and I dislike the addictive nature of likes and boosts (I’m not disciplined enough to ignore them). Self-hosting some Fedi thing is also out of the question (the minimalistic daemons don’t really support following hashtags, which is a must-have for me).
I’ll probably keep reading Fedi stuff, I just won’t post that much, I think.
Having some fun with SIRDS this morning.

What you should see: https://movq.de/v/dae785e733/disp.png
{kind=link}
And the tutorial I used for my C program: https://www.ime.usp.br/~otuyama/stereogram/basic/index.html
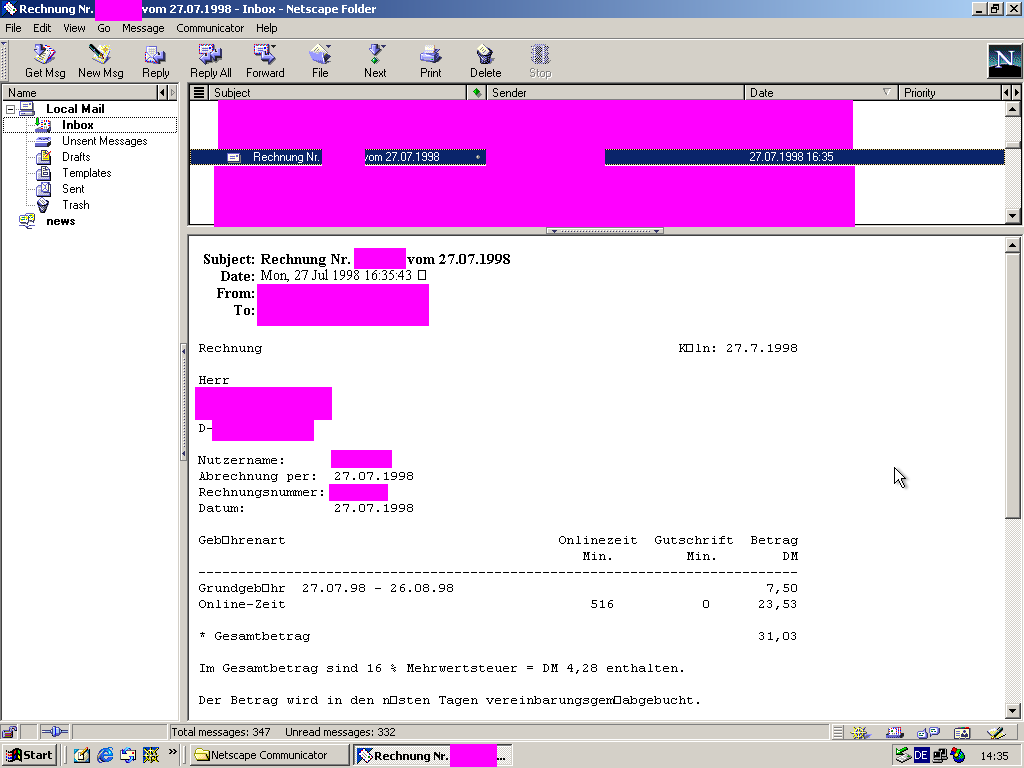
A bill from our ISP in 1998.
We’re talking about a month here, 1998-07-27 to 1998-08-26.
Basic fee: 7.50 DM (about 6€ today).
Online time: 516 minutes, 23.53 DM (about 20€ today).
That’s just the ISP costs, if I’m not mistaken. The underlying phone calls were pretty pricey as well.
Over the past few weeks I’ve been experimenting with and doing some deep learning and researching into neutral networks and evolutionary adaptation of them. The thing is I haven’t gotten very far. I’ve been able to build two different approaches so far with limited results. The frustrating part is that these things are so “random” it isn’t even funny. Like I can’t even get a basic ANN + GA to evolve a network that solves the XOR pattern every time with high levels of accuracy. 😞
↳
In-reply-to
»
@lyse what is the advantage for keeping it small? Will tt/tt2 bog down if your feed isn't rotated?
⤋ Read More
@bender@twtxt.net basically because we don’t readily use or support range hunters when requesting feeds it’s ideal to keep feed small for the time being at least until we think about writing up a formal specification for this, but it’s also only for Http hosted feeds
↳
In-reply-to
»
RIP GitHub https://github.blog/changelog/2025-05-08-updated-rate-limits-for-unauthenticated-requests/
⤋ Read More
@bender@twtxt.net Basically the way I’m reading this is 1 RPM. This is a rather aggressive rate limit actually. This basically makes Github inaccessible and useless for basically anything unless you’re logged in. You can basically kiss “pursuing” casually, anonymously goodbye.
Imagine if I imposed that kind of rate limit on twtxt.net?! 🤣
Also spent the morning continuing to think about a new design for EdgeGuard’s WAF. I’m basically going to build an entirely new pluggable WAF that will be designed to only consider Rate Limiting, IP/ASN-based filtering, JavaScript challenge handling, Basic behavioral analysis and Anomaly detection.
The only part of this design I’m not 100% sure about is the Javascript-based challenge handling? 🤔 I’m also considering making this into a “proof of work” requirement too, but I also don’t want to falsely block folks that a) turn Javascript™ off or b) Use a browser like links, elinks or lynx for example.
Hmmm 🧐
i started a little thing on my dreamwidth and called it a flash prompt box. basically it’s a limited time thing where people can prompt me for stuff i’m offering, like short fanfiction, photoshop-edited user icons, music recs, and a bit more! i’m having sooo much fun with it so far it’s been a blast just making stuff for friends :)
also more friends are making their own posts with the same concept which is SO cool to see
↳
In-reply-to
»
grafana is confusing af i deployed it again for my job (that is so wild to say...) and i'm like HOW DO THESE ALERTS WORK
⤋ Read More
Move beyond basic threshold alerts! Define clear Service Level Objectives (SLOs) and measure Service Level Indicators (SLIs) to track real user impact. Use Prometheus to alert when your SLOs are at risk, ensuring you focus on what truly matters to your users. #Monitoring #SRE #Prometheus
↳
In-reply-to
»
How do you stop a dog from barking? 🧐
⤋ Read More
@kat@yarn.girlonthemoon.xyz No no, it’s just barks at the slightest thing going on around the neighborhod 😃 like it just goes a bit nuts often 🤣 it was a rescue dog, two years old, and it wasn’t treated very well, a street dog. I think it’s just basically afraid of every human in the world 😢
↳
In-reply-to
»
Hey @kat If you see this, I'm aware of a bug. I'm trying to figure it out and fix it. bare with me 🤗 It is what's causing things to "stall" and to have to "restart". Sorry 😞
⤋ Read More
@kat@yarn.girlonthemoon.xyz Yeah right now I’m trying to see if I can “spread the CPU usage of fetching N feeds across M duration” so basically “smooth” out the spikes in CPU usage.
↳
In-reply-to
»
@kat @xuu Recommend you
⤋ Read More
git checkout main && git pull && make build. Few bug fixes 😄
@prologic@twtxt.net done! hey i got a question, you got any clue why my feeds aren’t updating? maybe it has to do with the new cache flag but i messed with that a bit and didn’t notice a difference. basically it’s like i have to manually restart yarnd to see new posts it’s really weird lol
i don’t think any of you know what a fan listing is but basically it was a fandom thing in the 2000s where people would make websites that other people could sign up for to show they’re a fan of something. more info here.
anyway i made a fan listing kinda thing in PHP to learn the language. it was fun af
↳
In-reply-to
»
To the parents or teachers: How do you teach kids to program these days? 🤔
⤋ Read More
@xuu@txt.sour.is Hahaha, that’s cool! You were (and still are) way ahead of me. :-)
We started with a simple traffic light phase and then added pedestrian crossing buttons. But only painting it on the canvas. In our computer room there was an actual traffic light on the wall and at the very end of the school year our IT basics teacher then modified the program to actually control the physical traffic light. That was very impressive and completely out of reach for me at the time. That teacher pulled the first lever for me ending up where I am now.
↳
In-reply-to
»
@xuu or @kat Do either of you have time this weekend to test upgrading your pod to the new
⤋ Read More
cacher branch? 🤔 It is recommended you take a full backup of you pod beforehand, just in case. Keen to get this branch merged and to cut a new release finally after >2 years 🤣
@kat@yarn.girlonthemoon.xyz Yes see UPGRADE.md – I believe @xuu@txt.sour.is is now running this live after a couple of hiccups and a bug fix. So yeah if you can, that would be cool, basically looking for early beta testers (I was the alpha tester 🤣)
↳
In-reply-to
»
@aelaraji oh nooo i've been there. i have to balance out my abnormal coffee consumption with my anxiety medication which can't be good lol
⤋ Read More
@kat@yarn.girlonthemoon.xyz my rule of thumb is try not to drink any caffeine past midday. This is basically based on experience and the half-life of caffeine in your system.
↳
In-reply-to
»
@prologic @bender @eapl.me I think opening another file is a bad idea because it adds complexity to the clients, breaks the single feed and I think keeping legacy clients will be more complex to add new features in the future. A modern approach is important.
I'll be honest, I'm a bit tired of the fight around the direct message. Perhaps, we can remove it as an extension and use the alternative @prologic . My suggestion apparently doesn't like to the community. I have no problem with remove it.
⤋ Read More
@bender@twtxt.net I use it. It’s not the feature I use the most in the fediverse, but I communicate this way with several friends. For example, it’s the main way I talk to the original creator of the twtxt-el repository, the way people greet me for the first time or the way they notify me of some bugs in the software I maintain. I can even tell you that it’s the main way I talk to some maintainers of the Emacs community. If there are any of you reading my words, speak up!
Why not have the same? There are things I want to say to @prologic@twtxt.net in private, why should I have to send him an email or private IRC? Or an public twt.
Of course, here’s a topic we’ve already talked about: what is twtxt for you? For me it will always be a social network, in microblogging format, but an asynchronous way of communicating. And having a tool to control visibility is basic 😄
I look forward to hearing from you @eapl.me@eapl.me !
↳
In-reply-to
»
“The Tree”™ in last winter:
⤋ Read More
@movq@www.uninformativ.de Oh, that’s beautiful!
I opened up all the photos in new tabs and went through them. For a second, I wondered that it was snowing at your place right now. :-D
That made me realize that so far we basically had nearly no April weather whatsoever. May might be full of it then, let’s see. :-)
↳
In-reply-to
»
@kate @eldersnake @abucci -- I've already spoken to @xuu on IRC about this, but the new
⤋ Read More
SqliteCache backend I'm working on here, what are your thoughts regarding mgirations from old MemoryCache (which is now gone in the codebase in this branch). Do you care to migrate at all, or just let the pod re-fetch all feeds? 🤔
@kate@yarn.girlonthemoon.xyz I’ll cut a release soon™, but still a few more things to iron out 🤣 One of the new challenges is figuring out what to do with the “Discover” view now that is has an unconfined limit, on my pod (at least) it’s now basically just “noise” 🤦♂️
css naked day, I missed that this year. css is messy anyway and i got a css book in german to learn the basics
↳
In-reply-to
»
A mate and I met at the scout yard to prepare an upcoming workshop. Boy did we have an amazing sunset when we left. The photos don't reflect it, it was a hell lot more beautiful in person: https://lyse.isobeef.org/plaetzle-2025-04-11/
⤋ Read More
@bender@twtxt.net @ionores@twtxt.net Yep, it’s extremely seldom that a photo turns out looking better than reality. Very rarely does that happen. But basically never with sunsets. ;-) Maybe once a leap year I’m very surprised to wonder how that subject wasn’t better in person but actually on film.
MacSSL: a port of Mbed-TLS for the classic Mac OS 7/8/9
Yesterday we had SDL2 for the classic Mac OS, today we have modern SSL/TLS for the classic Mac OS. This is a C89/C90 port of MbedTLS for Mac System 7/8/9. It works, and compiles under Metrowerks Codewarrior Pro 4. This is a basic app that performs a GET request on whatever is in api.h, and prints the result out to the text box (with a lot of debug information, of course). The idea of this project was to build an ‘app’ of … ⌘ Read more
SDL2 ported to Mac OS 9
Well, this you certainly don’t see every day. This is a “rough draft” of SDL2 for MacOS 9, using CodeWarrior Pro 6 and 7. Enough was done to get it building in CW, and the start of a “macosclassic” video driver was created. It DOES seem to basically work, but much still needs to be done. Event handling is just enough to handling Command-Q, there is no audio, etc etc etc. ↫ A cast of thousands The hardest part was a video driver for the classic Mac OS, which had to be created mostly f … ⌘ Read more
↳
In-reply-to
»
@kate @eldersnake @abucci -- I've already spoken to @xuu on IRC about this, but the new
⤋ Read More
SqliteCache backend I'm working on here, what are your thoughts regarding mgirations from old MemoryCache (which is now gone in the codebase in this branch). Do you care to migrate at all, or just let the pod re-fetch all feeds? 🤔
@abucci@anthony.buc.ci Apologies, the basic summary is as follows:
- Decided to rewrite the cache backend.
- It will now be a SQLite backend going forward.
- I’m planning on no data migration.
oh out of boredom yesterday i made my blog available via markdown files too so you can use charmbracelet/glow to read them in your terminal :)
basically i just set up a file directory on a path of my blog, organized the MD files by year, and so in theory you can navigate to that path and choose a folder, then copy a link to a markdown post and run this:
glow -p https://bubblegum.girlonthemoon.xyz/md/2025/2025-03-31%20premature%20reflections%20on%20sudden%20responsibility.md
and then as long as you have glow installed, you can read my posts from the terminal :D it’s so cool
This is sooo cool, it reminds me of learning QBasic (and then Visual Basic) in the 90s
Easylang story
https://easylang.online/apps/story.html
↳
In-reply-to
»
I got some assembly for you: https://images.gatesnotes.com/12514eb8-7b51-008e-41a9-512542cf683b/34d561c8-cf5c-4e69-af47-3782ea11482e/Original-Microsoft-Source-Code.pdf
⤋ Read More
@bender@twtxt.net I was a bit confused at first what that is: Apparently, it’s the source code of Altair BASIC: https://gizmonaut.net/soapflakes/EXE-199711.html
(Of course they have a user agent filter. 😂 Can’t download that PDF with wget.)
Hi, So i made a little MVP registry crawler tool for twtxt. It now has a basic UI to play with. It has a somewhat full history back to about 2018-ish. Plus some interesting bits that were timestamped to earlier.
Find it here: https://watcher.sour.is
Code base is found here: https://git.sour.is/sour-is/xt
↳
In-reply-to
»
An interesting episode about naming stuff, and some implications of the "Trademarks"
⤋ Read More
In Mexico you couldn’t register the word Sonora (state), nor Taqueria (kind of restaurant) as there are two common words, but perhaps the combination of both is trademarkable, I’m not sure, so many ‘taquerias’ here don’t file a trademark request. It’s usually “Taquería [LAST_NAME]” or “Taquería [PLACE]”.
At the same time, the word “taqueria” was trademarked in UK, like it would be “Paris” or “Pub” I guess, so basically Sonora Taqueria didn’t reply to the cease and desist, based on:
[Lizbeth García]: A brand may not use a word that is generic or descriptive of the products or services it is putting into circulation on the market.
Since he (Ismael, Taqueria’s representative) didn’t get any response, he decided to leave it in the hands of his law firm.
In early 2023, after all the noise on the internet and the mobilization caused by this case, an agreement was finally reached with Taquería to settle the matter peaceably.
In March 2023, Michelle and Sam decided to register the Sonora Taquería brand and logo with the UK Intellectual Property Office.
↳
In-reply-to
»
Hi! For anyone following the Request for Comments on an improved syntax for replies and threads, I've made a comparative spreadsheet with the 4 proposals so far. It shows a syntax example, and top pros and cons I've found:
https://docs.google.com/spreadsheets/d/1KOUqJ2rNl_jZ4KBVTsR-4QmG1zAdKNo7QXJS1uogQVo/edit?gid=0#gid=0
⤋ Read More
(I didn’t submit a proposal of my own, because it would basically just be a duplicate of another one. 😅)
Anyone interested in the PicoCalc? https://www.clockworkpi.com/product-page/picocalc #basic
↳
In-reply-to
»
Righto, now with added basic subject support. Hopefully!
⤋ Read More
Perfect!

I now also implemented basic replying by hitting a as in answering. What’s missing is automatically adding mentions in the message text template. That’s gonna be a bit more tricky, though.
↳
In-reply-to
»
(The previous message was written with
⤋ Read More
tt.) Now, this is the second attempt in tt2.
Righto, now with added basic subject support. Hopefully!
i really wanna learn golang it looks fun and capable and i can read it kind of but every time i try it i’m immediately stuck on basic concepts like “what the fuck is a pointer” (this has been explained to me and i still don’t get it). i did have types explained to me as like notes on code which makes sense a bit but i’m mostly lost on basic code concepts