My open letter, to the European Commission digital markets act team:
Hello,
I am joining other developers, concerned about Googles new plan, to approve every app and effectively destroy most of the competing 3rd party stores this way. The biggest one of these alternative stores, most known for their focus on user and developer privacy, already states, this would make it impossible for them to operate: https://f-droid.org/cs/2025/09/29/google-developer-registration-decree.html
Even communities like the XDA forum, where new developers are often introduced to the world of Android development, would likely be strongly impacted, as making, publishing and installing Android apps is made less accessible.
I am not just writing on their behalf, I run a small website myself (https://thecanine.ueuo.com/), that both provides legal modifications, for some android apps - for example adding an amoled dark theme, to the most popular XMPP chat client for Android, or increasing one of Androids keyboard apps height. This all comes after Googles previous changes to the Android operating system, that prevent users from installing old apps (old to Google, can mean only a couple of months, without an update - https://developer.android.com/google/play/requirements/target-sdk and the target version gets increased every year). I rely on apps developed by a single developer, even for things like making the pixel art presented on my website and sideloading as a way to make these apps work, before developers can catch up to Google’s new requirements - if Google is allowed to slowly kill these options, us digital artists will soon lose the tools we need to create digital art.
↳
In-reply-to
»
Hello again everyone! A little update on my twtxt client.
⤋ Read More
@zvava@twtxt.net @bender@twtxt.net At first I added it without thinking when planning the possible fields based on other UIs I was researching.
I was about to discard it but after thinking about it a bit I noticed that the services allowing to have a separated nick and display_name could unlock some good uses.
For example some added context or at-a-glance information like pronouns or statuses (like Artist [Accepting commissions] or App Name (v2.5)) while other used a more readable version of the nick (blog.domain.com became Person Name's Blog).
Of course it is absolutely optional and it can be safely ignored, but with my vision of being able to build more that a pure twtxt clients, giving it a first-class support just like the other known fields felt right to me.
All good things come to an end, I guess.
I have an Epson printer (AcuLaser C1100) and an Epson scanner (Perfection V10), both of which I bought about 20 years ago. The hardware still works perfectly fine.
Until recently, Epson still provided Linux drivers for them. That is pretty cool! I noticed today that they have relaunched their driver website – and now I can’t find any Linux drivers for that hardware anymore. Just doesn’t list it (it does list some drivers for Windows 7, for example).
I mean, okay, we’re talking about 20 years here. That is a very long time, much more than I expected. But if it still works, why not keep using it?
Some years ago, I started archiving these drivers locally, because I anticipated that they might vanish at some point. So I can still use my hardware for now (even if I had to reinstall my PC for some reason). It might get hacky at some point in the future, though.
This once more underlines the importance of FOSS drivers for your hardware. I sadly didn’t pay attention to that 20 years ago.
↳
In-reply-to
»
@zvava Mixing both addressing schemes combines the worst of both worlds in my opinion. Please don't do that.
⤋ Read More
@lyse@lyse.isobeef.org i would like to ditch hash addressing but as was pointed out it would be a pain in the ass to get clients currently working off of hashv1 to suddenly switch to location-based addressing instead of just hashv2 with the option to eventually phase it out — unless we can rally together all active client developers to decide on a location-based addressing specification (i still think my original suggestion of #<https://example.com/tw.txt#yyyy-mm-ddThh:mm:ssZ> is foolproof)
↳
In-reply-to
»
is the first
⤋ Read More
url metadata field unequivocally treated as the canon feed url when calculating hashes, or are they ignored if they're not at least proper urls? do you just tolerate it if they're impersonating someone else's feed, or pointing to something that isn't even a feed at all?
(#abcdefghijkl https://example.com/tw.txt#:~:text=2025-10-01T10:28:00Z), because it can be simply hacked in to clients currently on hashv1 and provides an off-ramp to location-based addressing
I like that property (an off-ramp to location-based addressing), so I think I could live with that approach. ✅
(I’m not sure why we’re using text fragments, though. Wouldn’t that link to the first occurence of 2025-10-01T10:28:00Z? That’s not necessarily correct. And, to be proper URLs that Firefox and Chromium understand, it would also need to be written as 2025%2D10%2D01T10:28:00Z. The dash carries meaning, sadly. I think all this just creates needless complication. How about we just go with https://example.com/tw.txt#2025-10-01T10:28:00Z?)
↳
In-reply-to
»
is the first
⤋ Read More
url metadata field unequivocally treated as the canon feed url when calculating hashes, or are they ignored if they're not at least proper urls? do you just tolerate it if they're impersonating someone else's feed, or pointing to something that isn't even a feed at all?
@alexonit@twtxt.alessandrocutolo.it prologic has me sold on the idea of hashv2 being served alongside a text fragment, eg. (#abcdefghijkl https://example.com/tw.txt#:~:text=2025-10-01T10:28:00Z), because it can be simply hacked in to clients currently on hashv1 and provides an off-ramp to location-based addressing (though i still think the format should be changed to smth like #<abc... http://example.com/...> so it’s cleaner once we finally drop hashes)
↳
In-reply-to
»
https://zsblog.mills.io/ for anyone interested. I think I still have some small tweaking to do befor eI use this for realz.
⤋ Read More
@prologic@twtxt.net need to work on the CSS. For example, the tags are too big, the code blocks (and the inline ones) are too small, the single posts have no date (intended?), and so on. It’s an alpha start!
↳
In-reply-to
»
TNO Threading (draft):
Each origin feed numbers new threads
⤋ Read More
Each origin feed numbers new threads
(tno:N). Replies carry both (tno:N) and (ofeed:<origin-url>). Thread identity = (ofeed, tno).
Example:
Alice starts thread href=”https://yarn.girlonthemoon.xyz/search?q=%2342:”>#42:**
2025-09-25T12:00:00Z (tno:42) Launching storage design review.
Bob replies:
2025-09-25T12:05:00Z (tno:42) (ofeed:https://alice.example/twtxt.txt
) I think compaction stalls under load.
Carol replies to Bob:
2025-09-25T12:08:00Z (tno:42) (ofeed:https://alice.example/twtxt.txt
) Token bucket sounds good.
↳
In-reply-to
»
Here is just a small list of things™ that I'm aware will break, some quite badly, others in minor ways:
⤋ Read More
I would personally rather see something like this:
2025-09-25T22:41:19+10:00 Hello World
2025-09-25T22:41:19+10:00 (#kexv5vq https://example.com/twtxt.html#:~:text=2025-09-25T22:41:19%2B10:00) Hey!
Preserving both content-based addressing as well as location-based addressing and text fragment linking.
↳
In-reply-to
»
Here is just a small list of things™ that I'm aware will break, some quite badly, others in minor ways:
⤋ Read More
@prologic@twtxt.net That is really great to hear!
If there are opposing opinions we either build a bridge or provide a new parallel road.
Also, I wouldn’t call my opinion a “stance”, I just wish for a better twtxt thanks to everyone’s effort.
The last thing we need to do is decide a proper format for the location-based version.
My proposal is to keep the “Subject extension” unchanged and include the reference to the mention like this:
// Current hash format: starts with a '#'
(#hash) here's text
(#hash) @<nick url> here's text
// New location format: valid URL-like + '#' + TIMESTAMP (verbatim format of feed source)
(url#timestamp) here's text
(url#timestamp) @<nick url> here's text
I think the timestamp should be referenced verbatim to prevent broken references with multiple variations (especially with the many timezones out there) which would also make it even easier to implement for everyone.
I’m sure we can get @zvava@twtxt.net, @lyse@lyse.isobeef.org and everyone else to help on this one.
I personally think we should also consider allowing a generic format to build on custom references, this would allow for creating threads using any custom source (manual, computed or external generated), maybe using a new “Topic extension”, here’s some examples.
// New format for custom references: starts with a '!' maybe?
(!custom) here's text
(!custom) @<nick url> here's text
// A possible "Topic" parse as a thread root:
[!custom] start here
[custom] simpler format
This one is just an idea of mine, but I feel it can unleash new ways of using twtxt.
↳
In-reply-to
»
Here is just a small list of things™ that I'm aware will break, some quite badly, others in minor ways:
⤋ Read More
@lyse@lyse.isobeef.org @prologic@twtxt.net Can’t we find a middle ground and support both?
The thread is defined by two parts:
- The hash
- The subject
The client/pod generate the hash and index it in it’s database/cache, then it simply query the subject of other posts to find the related posts, right?
In my own client current implementation (using hashes), the only calculation is in the hash generation, the rest is a verbatim copy of the subject (minus the # character), if this is the common implemented approach then adding the location based one is somewhat simple.
function setPostIndex(post) {
// Current hash approach
const hash = createHash(post.url, post.timestamp, post.content);
// New location approach
const location = post.url + '#' + post.timestamp;
// Unchanged (probably)
const subject = post.subject;
// Index them all
addToIndex(hash, post);
addToIndex(location, post);
addToIndex(subject, post);
}
// Both should work if the index contains both versions
getThreadBySubject('#abcdef') => [post1, post2, post3]; // Hash
getThreadBySubject('https://example.com#2025-01-01T12:00:00') => [post1, post2, post3]; // Location
As I said before, the mention is already location based @<example https://example.com/twtxt.txt>, so I think we should keep that in consideration.
Of course this will lead to a bit of fragmentation (without merging the two) but I think this can make everyone happy.
Otherwise, the only other solution I can think of is a different approach where the value doesn’t matter, allowing to use anything as a reference (hash, location, git commit) for greater flexibility and freedom of implementation (this probably need the use of a fixed “header” for each post, but it can be seen as a separate extension).
↳
In-reply-to
»
@zvava @lyse I also think a location based reference might be better.
⤋ Read More
@prologic@twtxt.net I can see the issues mentioned, but I think some can be fixed.
The current hash relies on a
urlfield too, by specification, it will use the first# url = <URL>in the feed’s metadata if present, that too can be different from the fetching source, if that field changes it would break the existing hashes too, a better solution would be to use a non-URL key like# feed_id = <UNIQUE_RANDOM_STRING>with theurlas fallback.We can prevent duplications if the reference uses that same url field too or the client “collapse” any reference of all the urls defined in the metadata.
I agree that hashing based on content is good, but we still use the URL as part of the hashing, which is just a field in the feed, easily replicable by a bot, also noting that edits can also break the hash, for this issue an alternative solution (E.g. a private key not included in the feed) should be considered.
For offline reading the source would be downloaded already, the fetching of non followed feeds would fill the gap in the same way mentions does, maybe I’m missing some context on this one.
To prevent collisions there was a discussion on extending the hash (forgot if that was already fixed or not), but without a fallback that would break existing clients too, we should think of a parallel format that maintains current implementations unchanged, we are already backward compatible with the original that don’t use threads at all, a mention style format for that could be even more user-friendly for those clients.
We should also keep in mind that the current mention format is already location based (@<example https://example.com/twtxt.txt>) so I’m not that worried about threads working the same way.
Hope to see some other thought about this matter. 🤓
↳
In-reply-to
»
@zvava @lyse I also think a location based reference might be better.
⤋ Read More
@alexonit@twtxt.alessandrocutolo.it @lyse@lyse.isobeef.org i really don’t understand why this was not the solution in the first place, given how simple twtxt is (mean to be), a reply should be as simple as #<https://example.com/twtxt.txt#2025-09-22T06:45Z> with the timestamp in an anchor link. the need for a mention is avoided like this as well since it’s already linking to the replied-to feed!
🐀💭 i should just implement it into bbycll and force it into existence
↳
In-reply-to
»
is there consensus on what characters should(n't) be allowed in
⤋ Read More
nicks? i remember reading somewhere whitespace should not be allowed, but i don't see it in the spec on twtxt.dev — in fact, are there any other resources on twtxt extensions outside of twtxt.dev?
@zvava@twtxt.net In tt, I recognize umlauts in nicks, but they cannot include whitespace, @, !, #, (, ), [, ], <, >, " (but ' is okay). Whitespace also acts as a separator between nick and URL. @<Hello World http://example.com> ends up exactly like that and is not a mention.
↳
In-reply-to
»
is there consensus on what characters should(n't) be allowed in
⤋ Read More
nicks? i remember reading somewhere whitespace should not be allowed, but i don't see it in the spec on twtxt.dev — in fact, are there any other resources on twtxt extensions outside of twtxt.dev?
@zvava@twtxt.net @movq@www.uninformativ.de I’m not entirely sure about the spaces, but maybe they were omitted to simplify parsing of mentions in the form of @<nick url>. If the next token after the @<nick does not look like a URL, it’s not a mention but regular text. This is just wild guessing, though.
Looking at the regex and tests in the original twtxt reference implementation seems to confirm that theory in the sense as it relies on whitespace as the delimiter:

Another thing about nicks is that the original twtxt reference implementation converts nicks to all lowercase:

You probably know this already, the original twtxt file format specification can be found here: https://twtxt.readthedocs.io/en/latest/user/twtxtfile.html
As for extensions, I don’t know of anything outside of twtxt.dev that has actually been (partially) implemented. However, there is also the issue tracker of the official reference implementation. You might wanna dig through that. For example, there is an alternative suggestions of multiline messages: https://github.com/buckket/twtxt/issues/157
↳
In-reply-to
»
Adding too this. The configuration example at the repository reads:
⤋ Read More
@quark@ferengi.one ooh, thanks for catching that! i forgot abt the caddy example when adding the config example
nick is nick bc it is parsed as a nickname just for the instance, though calling it instance_nick would probably be less confusing
↳
In-reply-to
»
@zvava I am getting
⤋ Read More
[2025/09/11 12:56:01.816] ⇒ please set config.host when trying to run "bbycll". How to bypass that tiny hurdle?
Adding too this. The configuration example at the repository reads:
{
"nick": "Example",
"description": "alice's twtxt instance!",
"host": "twtxt.example.com",
"admin": "alice"
}
Would it make more sense changing nick to instance_name or similar? Usually nick is reserved for users, like here, quark. Right? Also, is host the same FQDN to be used while proxying traffic to the application? That is, using the above configuration, it’s Caddy configuration would be:
twtxt.example.com {
encode
reverse_proxy :31212
}
Is that correct?
↳
In-reply-to
»
@zvava I am getting
⤋ Read More
[2025/09/11 12:56:01.816] ⇒ please set config.host when trying to run "bbycll". How to bypass that tiny hurdle?
On the configuration topic, the example at the repo reads like this:
“
↳
In-reply-to
»
wait why are so many of my post hashes not generating correctly ;w;
⤋ Read More
@zvava@twtxt.net I was about to suggest that you post some examples. By now, we’re pretty good at debugging hashing issues, because that happens so often. 😂 But it looks like you figured it out on your own. ✌️
↳
In-reply-to
»
@zvava I never used any of the social media platforms, that's why I'm probably ignorant.
⤋ Read More
Something like this, for example.
at first i dismissed the idea of likes on twtxt as not sensible…like at all — then i considered they could just be published in a metadata field (though that field could get really unruly after a while)
retwts are plausible, as “RE: https://example.com/twtxt.txt#abcdefg”, the hash could even be the original timestamp from the feed to make it human readable/writable, though im extremely wary of clogging up timelines
i thought quote twts could be done extremely sensibly, by interpreting a mention+hash at the end of the twt differently to when placed at the beginning — but the twt subject extension requires it be at the beginning, so the clean fallback to a normal reply i originally imagined is out of the question — it could still be possible (reusing the retwt format, just like twitter!) but i’m not convinced it’s worth it at that point
is any of this in the spirit of twtxt? no, not in the slightest, lmao
Directly via TCP/IP for example…
Dear dev.alessandrocutolo.it, do you really need to fetch my twtxt feed every 20-30 seconds? 😅 Not that it’s posing a problem, but I feel like this could be optimized. For example, how about using the if-modified-since request header: https://developer.mozilla.org/en-US/docs/Web/HTTP/Reference/Headers/If-Modified-Since
↳
In-reply-to
»
What’s Missing from “Retro”: gopher://midnight.pub/0/posts/2679
⤋ Read More
@movq@www.uninformativ.de having to go to a gopher proxy to see a text document better served on readily available web servers… 🤭, but I digress. Verbatim text:
What's Missing from "Retro"
~softwarepagan
------------------------------------------------------------------
You know, often, when I say I miss older ways of computing or
connecting online, people tell me "there's nothing stopping you
from doing that now!" and they are technicay correct in most cases
(though I can't, for example, chat with friends on MSN ever
again...) However, let me explain that while this type of thing can
*sort of* fill that hole in my heart, it isn't *the same.*
Say, for example, I wanted to connect with others over a BBS. This
wouldn't offer the same types of connections it used to. While
there are BBSes around with active users, they're no longer there
to discuss movies, Star Trek, D&D, games, etc. They're there to
discuss *BBSes.* The same can be said for Gopher, old-school forums
and all sorts of revival projects (such as Escargot, Spacehey,
etc.) Retrocomputing enthusiasts, while they have a variety of
interests, are often in these spaces to discuss the medium itself
and not other topics. This exists at a stark contrast from how
things were in the past, where a non-tech-inclined person may learn
the tech to connect with likeminded others (as I did as a
Zelda-obsessed kid.)
The same can be said of old media. People will say "well, nobody is
stopping you from watching old shows/movies now!" Again, they are
technically correct. I can go home right now and watch *Star Trek:
The Next Generation* to my heart's content. It will never again,
however, be current, or new. When something is new, it serves as a
shared cultural experience. Remember how "Game of Thrones* felt in
the mid-to-late 2010s? Yeah, that.
It's sad. I sustain myself on a mixed diet of old things, new
things, and new things intended for old millenials like me who like
old things. It can be bittersweet.
↳
In-reply-to
»
Speaking of manpages:
⤋ Read More
@kat@yarn.girlonthemoon.xyz On the one hand, all these programs have a very long history and the technology behind manpages is actually very powerful – you can use it to write books:
https://www.troff.org/pubs.html
I have two books from that list, for example “The UNIX programming environment”:

It’s a bit older, of course, but it looks and feels like a normal book, and it uses the same tech as manpages – which I think is really cool. 😎
It’s comparable to LaTeX (just harder/different to use) but much faster than LaTeX. You can also do stuff like render manpages as a PDF (man -Tpdf cp >cp.pdf) or as an HTML file (man -Thtml cp >cp.html). I think I once made slides for a talk this way.
On the other hand, traditional manpages (i.e., ones that are not written in mandoc) do not use semantic markup. They literally say, “this text is bold, that text over here is italics”, and so on.
So when you run man foo, it has no other choice but to show it in black, white, bold, underline – showing it in color would be wrong, because that’s not what the source code of that manpage says.
Colorizing them is a hack, to be honest. You’re not meant to do this. (The devs actually broke this by accident recently. They themselves aren’t really aware that people use colors.)
If mandoc and semantic markup was more commonly used, I think it would be easier to convince the devs to add proper customizable colors.
↳
In-reply-to
»
on my yarn pod nothing really embeds (not even images) so i'm looking at the embed rules part of the mod settings and i'm like... i don't know how to do any of this 😭😭😭
⤋ Read More
There is a missing feature I’ve been intending to add to though, which is that any link that looks like a URL that might be an image, for example, ends with .png or .jpg or whatever, we should just render that as an image and not expect users to wrap it in Markdown image links 
↳
In-reply-to
»
I have a Python script that transforms the original YouTube channel Atom feed into a more useful Atom feed by removing the spam description and replacing it with the video duration, filtering out videos by title, duration, etc. I just updated it to exclude the damn Shorts garbage more efficiently. Finally, YouTube updated their Atom feed generation, so that the video URL contains
⤋ Read More
/short/ if it's of this useless kind. Never thought that they ever actually will improve their Atom feeds. Thank you, much appreciated!
@kat@yarn.girlonthemoon.xyz @movq@www.uninformativ.de Sorry, I neither finished it nor in time. :-( That’s as good as it’s gonna get for the moment: https://git.isobeef.org/lyse/gelbariab/-/tree/master/rss-proxys?ref_type=heads
The README should hopefully provide a crude introduction. The example configuration file is documented fairly well, I believe (but maybe not). You probably still have to consult and maybe also modify the source code to fit your needs.
Let me know if you run into issues, have questions, wishes etc.
Here’s an example of X11/Xlib being old and archaic.
X11 knows the data type “cardinal”. For example, the window property _NET_WM_ICON (which holds image data for icons) is an array of “cardinal”. I am already not really familiar with that word and I’m assuming that it comes from mathematics:
https://en.wikipedia.org/wiki/Cardinal_number
(It could also be a bird, but probably not: https://en.wikipedia.org/wiki/Cardinalidae)
We would probably call this an “integer” today.
EWMH says that icons are arrays of cardinals and that they’re 32-bit numbers:
https://specifications.freedesktop.org/wm-spec/latest-single/#id-1.6.13
So it’s something like 0x11223344 with 0x11 being the alpha channel, 0x22 is red, and so on.
You would assume that, when you retrieve such an array from the X11 server, you’d get an array of uint32_t, right?
Nope.
Xlib is so old, they use char for 8-bit stuff, short int for 16-bit, and long int for 32-bit:
That is congruent with the general C data types, so it does make sense:
https://en.wikipedia.org/wiki/C_data_types
Now the funny thing is, on modern x86_64, the type long int is actually 64 bits wide.
The result is that every pixel in a Pixmap, for example, is twice as large in memory as it would need to be. Just because Xlib uses long int, because uint32_t didn’t exist, yet.
And this is something that I wouldn’t know how to fix without breaking clients.
We finally got a caliper donated for this year’s scout flea market. We didn’t sell it, but kept it ourselves. It will come in very handy every now and then in our material store. For example, I missed having a caliper in the past when sorting our random assortment of screws or measuring the depth of a hole. It’s a wee bit banged up (probably happened during transport) and didn’t come with a box, but the latter is now solved.
The lid and bottom came from a wardrobe back panel I got from a mate, the sides were rocket sticks in their former lives. I found some scrap of felt in our material store and some hinges laying around in the drawers of my own workshop.
Unfortunately, the table saw teared up the plywood veneer fibres badly, even though I put tape around to prevent that. This is the first time it didn’t work. At. All. To cover that up, I painted the box with some decades old tinting paint (price tag says Deutsche Mark, not Euro!) from my paint cabinet. It’s awesome, works absolutely perfectly and doesn’t smell the slightest bit. I reckon, this caliper box is plenty good enough for occasional use at our scout material store.

↳
In-reply-to
»
Xfce does one thing very right: It stores its settings in plain-text XML files. This allows me to easily read, track, and maybe even distribute these settings to other machines.
⤋ Read More
@lyse@lyse.isobeef.org @kat@yarn.girlonthemoon.xyz I spent so much time in the past figuring out if something is a dict or a list in YAML, for example.
What are the types in this example?
items:
- part_no: A4786
descrip: Water Bucket (Filled)
price: 1.47
quantity: 4
- part_no: E1628
descrip: High Heeled "Ruby" Slippers
size: 8
price: 133.7
quantity: 1
items is a dict containing … a list of two other dicts? Right?
It is quite hard for me to grasp the structure of YAML docs. 😢
The big advantage of YAML (and JSON and TOML) is that it’s much easier to write code for those formats, than it is with XML. json.loads() and you’re done.
HTTP referrers are quite broken, aren’t they?
Because of that recent storm on my blog, I had a peek at them. There’s a lot of garbage in there. For example, https://docs.freebsd.org/en/books/handbook/disks-virtual.html is supposed to refer to one of my blog posts …
What’s going on here?
↳
In-reply-to
»
PSA:
⤋ Read More
setpriv on Linux supports Landlock.
Another example:
$ setpriv \
--landlock-access fs \
--landlock-rule path-beneath:execute,read-file:/bin/ls-static \
--landlock-rule path-beneath:read-dir:/tmp \
/bin/ls-static /tmp/tmp/xorg.atom
The first argument --landlock-access fs says that nothing is allowed.
--landlock-rule path-beneath:execute,read-file:/bin/ls-static says that reading and executing that file is allowed. It’s a statically linked ls program (not GNU ls).
--landlock-rule path-beneath:read-dir:/tmp says that reading the /tmp directory and everything below it is allowed.
The output of the ls-static program is this line:
─rw─r──r────x 3000 200 07-12 09:19 22'491 │ /tmp/tmp/xorg.atom
It was able to read the directory, see the file, do stat() on it and everything, the little x indicates that getting xattrs also worked.
3000 and 200 are user name and group name – they are shown as numeric, because the program does not have access to /etc/passwd and /etc/group.
Adding --landlock-rule path-beneath:read-file:/etc/passwd, for example, allows resolving users and yields this:
─rw─r──r────x cathy 200 07-12 09:19 22'491 │ /tmp/tmp/xorg.atom
Something happened with the frame rate of terminal emulators lately. It looks like there’s a trend to run at a high framerate now? I’m not sure exactly. This can be seen in VTE-based terminals like my xiate or XTerm on Wayland. foot and st, on the other hand, are fine.
My shell prompt and cursor look like this:
$ █
When I keep Enter pressed, I expect to see several lines like so:
$
$
$
$
$
$
$ █
With the affected terminal emulators, the lines actually show up in the following sequence. First, we have the original line:
$ █
Pressing Enter yields this as the next frame:
$
█
And then eventually this:
$
$ █
In other words, you can see the cursor jumping around very quickly, all the time.
Another example: Vim actually shows which key you just pressed in the bottom right corner. Keeping j pressed to scroll through a file means I get to see a j flashing rapidly now.
(I have no idea yet, why exactly XTerm in X11 is fine but flickering in Wayland.)
↳
In-reply-to
»
Been spending a lot of time researching campers as I want to / plan to upgrade our current Camper Trailoer (forward fold) Stoney Creek XL-FF6 to a slightly larger Hybrid Camper/Caravan with ensuite, internal kitchenette, external full hitchen, pop-top roof and twin bunks.
⤋ Read More
@prologic@twtxt.net @bender@twtxt.net That’s what I thought as well, sounds way too expensive to me. But I have no idea what the prices are over here. Probably also astronomical. Campers sit around most of the time, one really would need to use them a lot to justify spending so much money on them.
But yeah, each to their own (expensive) hobbies. :-) I, for example, burn my money on tools that I don’t really™ need. :-P
↳
In-reply-to
»
@movq Yeah, luckily, there is the suckless project. I couldn't live without dmenu!
⤋ Read More
@lyse@lyse.isobeef.org dmenu is a great example.
There have been several attempts at porting dmenu from X11 to Wayland. Well, not exactly “porting” it, more like rewriting it from scratch. Turns out: It’s not that easy.
dmenu is super fast and reliable. None of the Wayland rewrites are (at least none of the popular ones that I know of). They are either bloated and/or slow.
It takes a lot of discipline and restraint to write simple software and not blow up the codebase. This is much harder than people think. It’s a form of art, really.
↳
In-reply-to
»
The lack of suckless-like simple, hackable software these days is appalling.
⤋ Read More
@movq@www.uninformativ.de This is a really good example of “simplicity” but achieves the intent and goals 👌
(Now, I don’t know if your screen reader can work with this. Let me know if it doesn’t.)
I don’t use a screen reader fortunately (actually they’re pretty garbage). So all good 👍 (I juse use full-screen zoom).
↳
In-reply-to
»
The lack of suckless-like simple, hackable software these days is appalling.
⤋ Read More
@prologic@twtxt.net Yeah, this really could use a proper definition or a “manifest”. 😅 Many of these ideas are not very wide spread. And I haven’t come across similar projects in all these years.
Let’s take the farbfeld image format as an example again. I think this captures the “spirit” quite well, because this isn’t even about code.
This is the entire farbfeld spec:
farbfeld is a lossless image format which is easy to parse, pipe and compress. It has the following format:
╔════════╤═════════════════════════════════════════════════════════╗
║ Bytes │ Description ║
╠════════╪═════════════════════════════════════════════════════════╣
║ 8 │ "farbfeld" magic value ║
╟────────┼─────────────────────────────────────────────────────────╢
║ 4 │ 32-Bit BE unsigned integer (width) ║
╟────────┼─────────────────────────────────────────────────────────╢
║ 4 │ 32-Bit BE unsigned integer (height) ║
╟────────┼─────────────────────────────────────────────────────────╢
║ [2222] │ 4x16-Bit BE unsigned integers [RGBA] / pixel, row-major ║
╚════════╧═════════════════════════════════════════════════════════╝
The RGB-data should be sRGB for best interoperability and not alpha-premultiplied.
(Now, I don’t know if your screen reader can work with this. Let me know if it doesn’t.)
I think these are some of the properties worth mentioning:
- The spec is extremely short. You can read this in under a minute and fully understand it. That alone is gold.
- There are no “knobs”: It’s just a single version, it’s not like there’s also an 8-bit color depth version and one for 16-bit and one for extra large images and one that supports layers and so on. This makes it much easier to implement a fully compliant program.
- Despite being so simple, it’s useful. I’ve used it in various programs, like my window manager, my status bars, some toy programs like “tuxeyes” (an Xeyes variant), or Advent of Code.
- The format does not include compression because it doesn’t need to. Just use something like bzip2 to get file sizes similar to PNG.
- It doesn’t cover every use case under the sun, but it does cover the most important ones (imho). They have discussed using something other than RGBA and decided it’s not worth the trouble.
- They refrained from adding extra baggage like metadata. It would have needlessly complicated things.
↳
In-reply-to
»
The lack of suckless-like simple, hackable software these days is appalling.
⤋ Read More
For example, I reckon software should treat stdout and stderr with care and never output logs or other such garbage to stdout that cannot possibly be useful in a UNIX pipeline 😅
↳
In-reply-to
»
The lack of suckless-like simple, hackable software these days is appalling.
⤋ Read More
@prologic@twtxt.net Ah, I’m referring to software that’s similar to that of suckless.org: Small, minimal codebases, small tools, but still useful. dmenu is probably the best example and also farbfeld.
Here’s the author of Anubis talking about some of their experiences:
https://xeiaso.net/blog/why-i-use-suckless-tools-2020-06-05/
(You can skip the long config and keybinds part.)
↳
In-reply-to
»
I bought the “remastered” versions of Grim Fandango and Forsaken on GOG, because they’re super cheap at the moment. Both have native Linux versions.
⤋ Read More
@eldersnake@we.loveprivacy.club This wasn’t always the case, though. Quake3, Quake4, Unreal Tournament 99 and 2004 are examples of games that used to run very well as native Linux games. But that was 20+ years ago …
↳
In-reply-to
»
Just realized: One of the reasons why I don’t like “flat UIs” is that they look broken to me. Like the program has a bug, missing pixmaps or whatever.
⤋ Read More
These are lists in your Inkscape example, right?
The font stuff? Yeah, that’s a scrollable list where you can select the current font.
↳
In-reply-to
»
Just realized: One of the reasons why I don’t like “flat UIs” is that they look broken to me. Like the program has a bug, missing pixmaps or whatever.
⤋ Read More
@movq@www.uninformativ.de Yes, flat UIs are broken! I’m used to that by now, but it’s still more work to recognize than when there are borders around buttons, etc.
These are lists in your Inkscape example, right? (I’m too lazy to start Inkscape myself and look at it. And writing this took longer than just seeing for myself, but here we are. I met up with one of my best schoolmate this morning and it’s fucking hot already. So I blame the heat.) Nested tabs are probably an own death sin in itself. I know, I know, the upper ones can be made into windows and dragged around, but still.
Just realized: One of the reasons why I don’t like “flat UIs” is that they look broken to me. Like the program has a bug, missing pixmaps or whatever.
Take this for example:
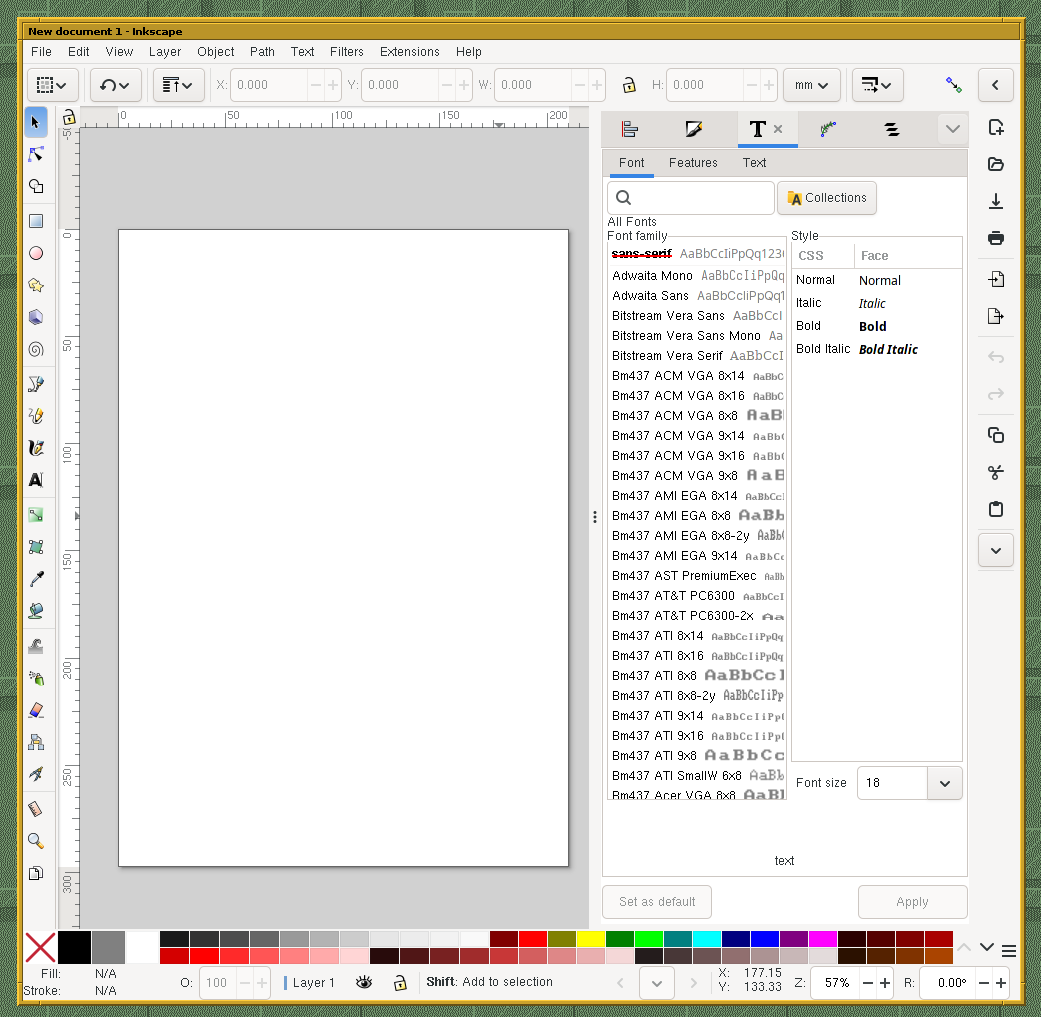
I’m talking about this area specifically:
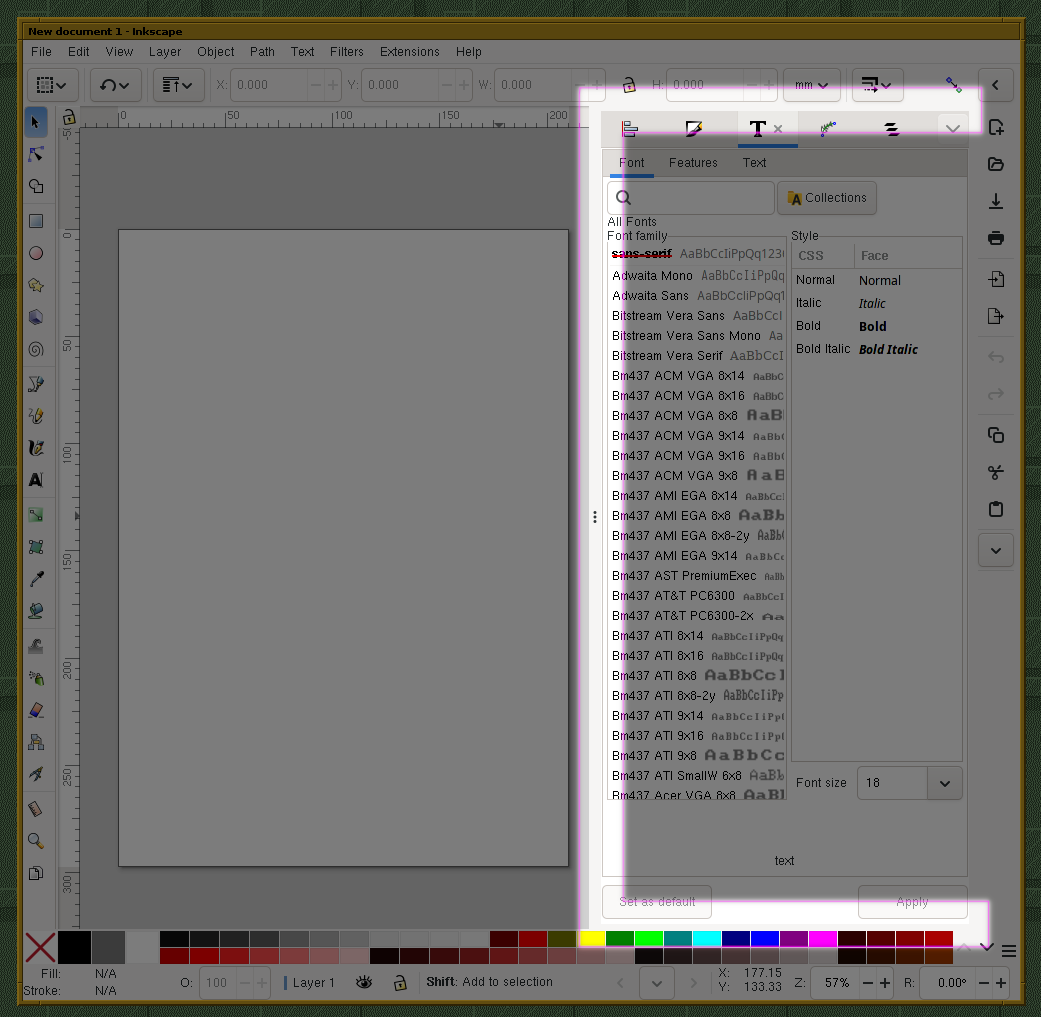
One UI element ends and the other one begins – no “transition” between them.
The style of old UIs like these two is deeply ingrained into my brain:
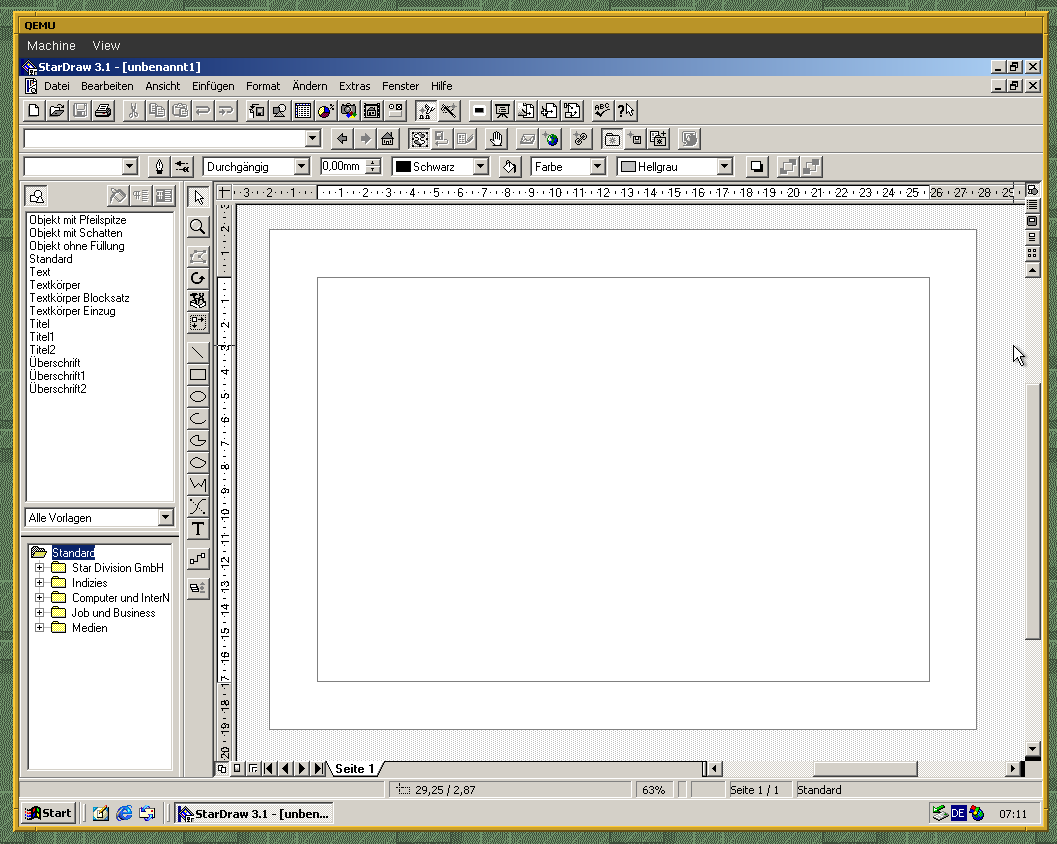
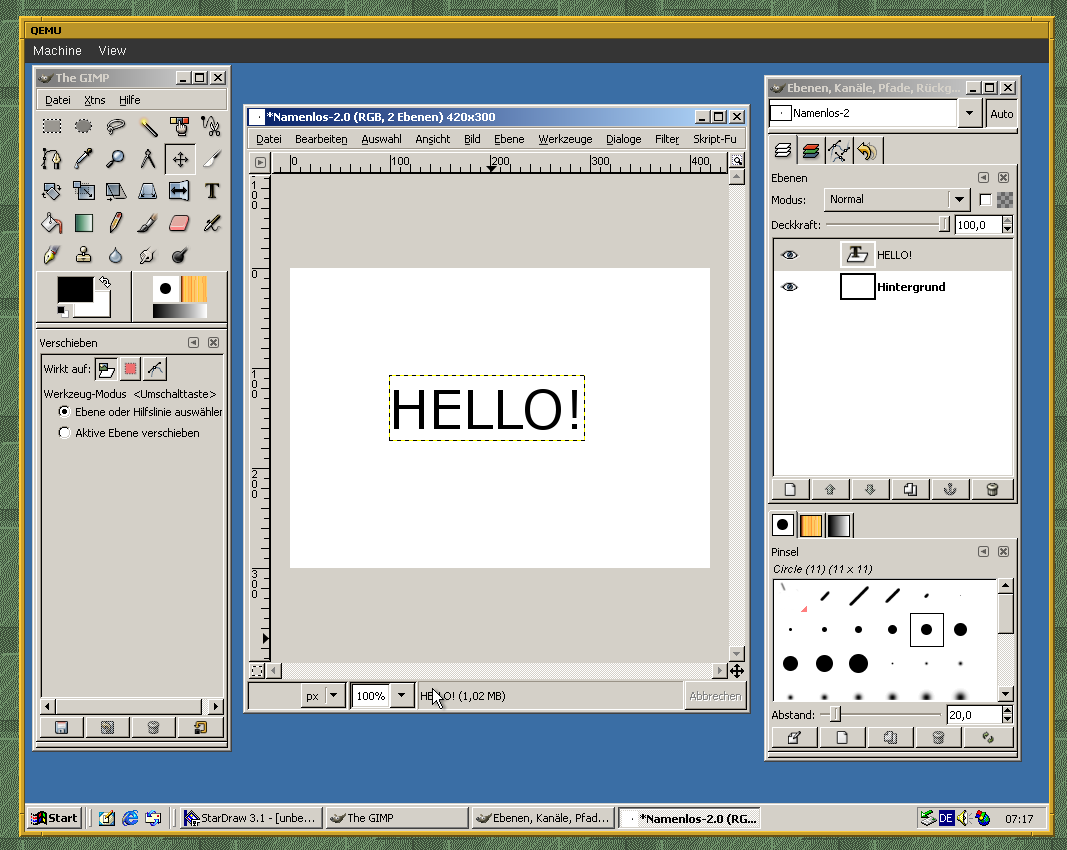
When all these little elements (borders, handles, even just simple lines, …) are no longer present, then the program looks buggy and broken to me. And I’m not sure if I’ll ever be able to un-learn that.
↳
In-reply-to
»
Fuck me sideways, Rust is so hard. Will we ever be friends?
⤋ Read More
@prologic@twtxt.net I’m trying to call some libc functions (because the Rust stdlib does not have an equivalent for getpeername(), for example, so I don’t have a choice), so I have to do some FFI stuff and deal with raw pointers and all that, which is very gnarly in Rust – because you’re not supposed to do this. Things like that are trivial in C or even Assembler, but I have not yet understood what Rust does under the hood. How and when does it allocate or free memory … is the pointer that I get even still valid by the time I do the libc call? Stuff like that.
I hope that I eventually learn this over time … but I get slapped in the face at every step. It’s very frustrating and I’m always this 🤏 close to giving up (only to try again a year later).
Oh, yeah, yeah, I guess I could “just” use some 3rd party library for this. socket2 gets mentioned a lot in this context. But I don’t want to. I literally need one getpeername() call during the lifetime of my program, I don’t even do the socket(), bind(), listen(), accept() dance, I already have a fully functional file descriptor. Using a library for that is total overkill and I’d rather do it myself. (And look at the version number: 0.5.10. The library is 6 years old but they’re still saying: “Nah, we’re not 1.0 yet, we reserve the right to make breaking changes with every new release.” So many Rust libs are still unstable …)
… and I could go on and on and on … 🤣
fn sub(foo: &String) {
println!("We got this string: [{}]", foo);
}
fn main() {
// "Hello", 0x00, 0x00, "!"
let buf: [u8; 8] = [0x48, 0x65, 0x6C, 0x6C, 0x6F, 0x00, 0x00, 0x21];
// Create a string from the byte array above, interpret as UTF-8, ignore decoding errors.
let lossy_unicode = String::from_utf8_lossy(&buf).to_string();
sub(&lossy_unicode);
}
Create a string from a byte array, but the result isn’t a string, it’s a cow 🐮, so you need another to_string() to convert your “string” into a string.
- https://doc.rust-lang.org/std/string/struct.String.html#method.from_utf8_lossy
- https://doc.rust-lang.org/std/borrow/enum.Cow.html
I still have a lot to learn.
(into_owned() instead of to_string() also works and makes more sense to me, it’s just that the compiler suggested to_string() first, which led to this funny example.)
Maybe you’ll enjoy this as well:
I still have one of my first modems, a Creatix LC 144 VF:

I think this was the modem that I used when I first connected to the internet, but I’m not sure.
I plugged it in again and it still works:
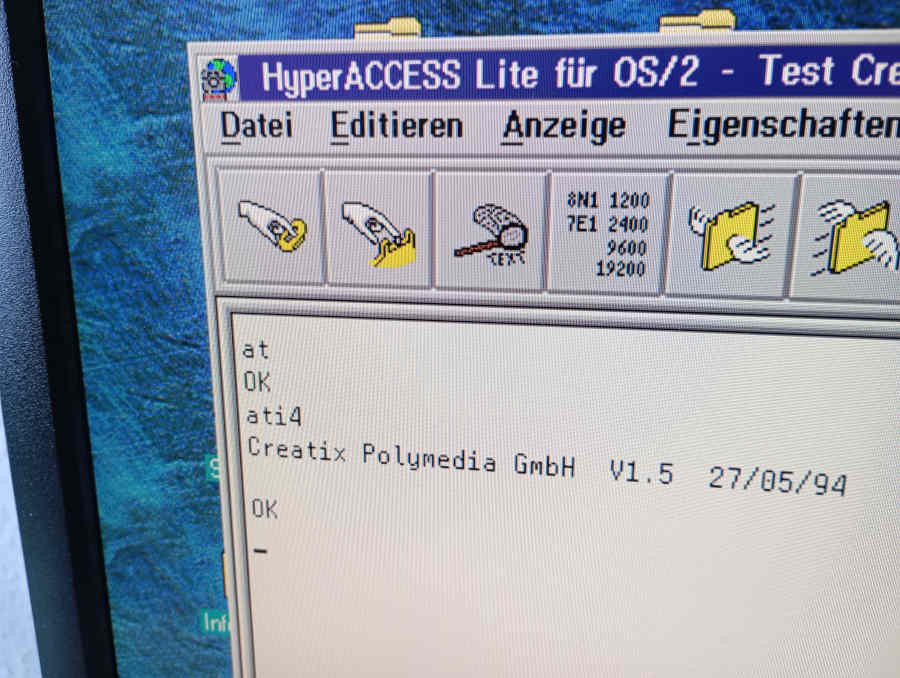

The firmware appears to be from 1994, which sounds about right. I don’t think we had internet access before that. We certainly did use local mailboxes, though. (Or BBS’s, as you might call them.)
I now want to actually use that modem again. For the moment, I can only use a phone to dial into it, I lack a second modem to actually establish a connection. Here’s a video:
Not spectacular, but the modem does answer after me entering ATA.
I bought another cheap old modem on eBay and am now waiting for it to arrive. Once it’s here, I want to simulate an actual dial-up session, hopefully from OS/2 or Windows 3.x.
↳
In-reply-to
»
i wish it was realistic for me to learn golang but every single time i try to comprehend any go code i'm like What the fuck am i looking at. why is all of this so short and condensed GIVE ME VERBOSE CODE
⤋ Read More
@kat@yarn.girlonthemoon.xyz I don’t like Golang much either, but I am not a programmer. This little site, Go by example might explain a thing or two.
↳
In-reply-to
»
i wish it was realistic for me to learn golang but every single time i try to comprehend any go code i'm like What the fuck am i looking at. why is all of this so short and condensed GIVE ME VERBOSE CODE
⤋ Read More
@kat@yarn.girlonthemoon.xyz In what way should it be more verbose? Can you give an example? 🤔
ejemplo de mi .config/twtxt/config https://termbin.com/vfp6 #twtxt #config #example
↳
In-reply-to
»
@thecanine @movq So I actually agree with you! I think Dustin is taking a bit of a "deep and dark" path here (depression), and there are many parallels to other types of activities that we can all talk to. "AI" or "LLM"(s) here should be no different. Use them, Don't use them. I don't really see how it takes away our creativity or critical thinking.
⤋ Read More
@prologic@twtxt.net What I meant, is that I will not say that someone is not really a writer, if they choose to have what they wrote, ran through some spelling and sentence structure checker, like the one included in MS Word, the average phone keyboard, or on reverso.net - given that they look over the output and make sure the corrections make sense.
Similarly, I won’t complain much, if someone uses AI, to remove backgrounds from images, where the AI can preform this task, as well as a human would and makes sure to check it afterwards, or use ai as a way to sort large quantities of images - usually done for science. An example of this, would be having terabytes of plant photos, from some cities camera system and having an AI analyse them, in an attempt to detect notable changes, like mold, parasites, or the plants needing more water.