↳
In-reply-to
»
among these options, 3
⤋ Read More
@eapl_en@eapl.me Good idea
↳
In-reply-to
»
What would you like the new twtxt logo to be?
Comments: https://git.mills.io/yarnsocial/twtxt.dev/issues/9#issuecomment-18960
Media
⤋ Read More
4, but I like the idea of @eapl_en@eapl.me
Yesterday I was doing a lot of research on how #hyperdrive and the #holepunch project work. Would it be possible to use it to make #twtxt an easier gateway for new users? Could we stop using web servers?
My conclusion: We would end up being a #nostr. On the one hand it would become more complex to use, it would force the user to have software installed, and on the other hand the community would need a central proxy to make the routes accessible via HTTP. In other words, it’s not a good idea.
However, it’s an AMAZING technology. I want to start playing with it.
↳
In-reply-to
»
Linear feeds are a dark pattern - A proposal for Mastodon
https://tilde.town/~dzwdz/blog/feeds.html
⤋ Read More
@eapl.me@eapl.me I like this idea. Another option would be to show a limited number of posts, with an option to see the omitted ones by user. Either way, I wonder how well that works with threading.
↳
In-reply-to
»
reviewing logs this morning and found i have been spammed hard by bots not respecting the
⤋ Read More
robots.txt file. only noticed it because the OpenAI bot was hitting me with a lot of nonsensical requests. here is the list from last month:
(I keep thinking that going back go Gopher or Gemini might be a good idea at this point. They don’t care about that, probably. 🫣)
↳
In-reply-to
»
Excellent article where you reflect on why it is important to write in your blog, even knowing that nobody will read it.
https://andysblog.uk/why-blog-if-nobody-reads-it/
At least this article does.
⤋ Read More
@andros@twtxt.andros.dev The article is a good reminder of the true blogging mindset. But let’s try to think beyond. 2 ideas: (1) writing “forces clarity, structures your thoughts, sharpens your perspective”. But it also generates thoughts in the sense of Heinrich von Kleist (1805). (2) You’re writing for “the future you, one right person, one day” but you are also writing for the AI. The idea of AI as an audience.
PebbleOS becomes open source, new Pebble device announced
Eric Migicovsky, founder of Pebble, the original smartwatch maker, made a major announcement today together with Google. Pebble was originally bought by Fitbit and in turn Fitbit was then bought by Google, but Migicovsky always wanted to to go back to his original idea and create a brand new smartwatch. PebbleOS took dozens of engineers working over 4 years to build, alongside our fantastic product and QA teams. Repro … ⌘ Read more
Okay, so the idea of the evening is to get a wallpaper with the current sky above my head with constellations, like https://stellarium-web.org/ can show… Need to script I guess ^^
↳
In-reply-to
»
hmmm? 🤔
⤋ Read More
@lyse@lyse.isobeef.org @prologic@twtxt.net 😆 There was something weird going on with my #Timeline instance, the text input box was visible even though I was logged out and I was able to twt from it … It has to do with cache because it wouldn’t disappear unless I whip my website’s cache from the browser.
Poke @sorenpeter@darch.dk and @eapl.me@eapl.me I have no Idea how to reproduce this.
↳
In-reply-to
»
It's ok for most encrypted protocols (In salty you can fetch other messages but can't decrypt). Btw i think recipient can be removed so if someone seen message they tried to decypt, if can't - its not message to you
⤋ Read More
here are a few ideas you might take into consideration when designing a secure IM https://developer.virgilsecurity.com/docs/e3kit/fundamentals/secure-instant-messaging/
Obviously if you’ve worked on something similar, you already know it, he
Pinellas County - 3 mile run: 3.15 miles, 00:09:39 average pace, 00:30:26 duration
legs feel really beat up but i have no idea why.
#running
↳
In-reply-to
»
I want to share a little idea for a new extension with the goal of adding direct messages in #twtxt https://github.com/tanrax/twtxt-direct-message-extension
⤋ Read More
interesting idea. I’m not personally interested on having DM conversations on twtxt (for now), although I see the community could be interested in.
I’d suggest to enable the Discussion section in your Github repo to receive comments, as we did for timeline https://github.com/sorenpeter/timeline/discussions
I want to share a little idea for a new extension with the goal of adding direct messages in #twtxt https://github.com/tanrax/twtxt-direct-message-extension
↳
In-reply-to
»
Would anyone object to the feeds.twtxt.net service having auth soon™ ? 🤔 I'm tired of the garbage feeds that it has accumulated over tie (spammers) and I want to a) clean it up b) lock it down somewhat.
⤋ Read More
@prologic@twtxt.net this is a great idea!
Would anyone object to the feeds.twtxt.net service having auth soon™ ? 🤔 I’m tired of the garbage feeds that it has accumulated over tie (spammers) and I want to a) clean it up b) lock it down somewhat.
The idea would be that you’d login with your Yarn.social account on some pod you control/operate or share with a nice person 🤣 – For those unfamiliar, this is called IndieAuth or IndieLogin. ALL Yarn.social pods are in fact valid (have been for years now) IndieAuth Providers. So I can just ust that. This also technically means you could login with your own domain too (more on that later…)
I have no idea what happened in/around instagram but, Holly Shi_ !! People have been pouring out of it and into #Pixelfed for hours now. 😆 way to go #Fedi
↳
In-reply-to
»
Noice! Media
⤋ Read More
@doesnmppsflt@doesnm.p.psf.lt It looks like it… Although they shouldn’t be empty since Timeline took care of sending those. I believe I have an idea as to why that happened, but will have to test before filing an issue.
curl: (3) URL rejected: Malformed input to a URL function. Writing sender in bash was BAD idea
↳
In-reply-to
»
good morning yarn friends. we need a funny name for yarn posters. what's something that fits the yarn theme.... i mean we quite literally have threads here. yarn threads. how epic is that. now us posters need a funny name too.
⤋ Read More
@prologic@twtxt.net wait thats so cute re: the yarn name! i had no idea! we’re all just keeping the yarn ball rolling…
Hmm, I just noticed that the feed template seems to be broken on your yarnd instance, @kat@yarn.girlonthemoon.xyz. Looking at your raw feed file (and your mates as well), line 6 reads:
# This is hosted by a Yarn.social pod yarn running yarnd ERSION@OMMIT go1.23.4
^^^^^^^^^^^^
Looks like the first letters of the version and commit got somehow chopped off. I’ve no idea what happened here, maybe @prologic@twtxt.net knows something. :-? I’m not familiar with the templating, I just recall @xuu@txt.sour.is reporting in IRC the other day that he’s also having great fun with his custom preamble from time to time.
That “broken” comment doesn’t hurt anything, it’s still a proper comment and hence ignored by clients. It’s just odd, that’s all.
↳
In-reply-to
»
The fact that the official Python docs don’t clearly state what a function returns, grinds my gears. This has cost me so much time over the years. You always have to read through a huge block of text.
⤋ Read More
@movq@www.uninformativ.de Yeah, the Python docs are more like a book. They absolutely shine if you have no idea and read them from top to bottom. The tutorial is baked right in. But they don’t work all that perfect as cheat sheets. I also remember looking for the return types way too long in the past.
I would have thought that this could be easily improved when type hints are in place. And it sure does: https://www.tornadoweb.org/en/stable/httpclient.html#tornado.httpclient.HTTPClient.fetch
Any idea What’s this "twtxtfeevalidator/0.0.1" UA about? I thought I could ask before throwing a 1000GB file at it 🪤 could it be the same ‘xt’ thing @lyse@lyse.isobeef.org was talking about the other day?
↳
In-reply-to
»
i recorded my first camcorder video!!!! it's just me practicing guitar after sooo long of not playing it. my acoustic, to be specific (well, it's an electric acoustic thing but i can play it without plugging it in lol, i do have a stratocaster though). it's capped at ~30 minutes because i used one mini DVD for it and decided i wasn't gonna use another one to extend the run time. so yeah. it was super fun! i hope i can share it soon, i'm ripping the disc with make MKV right now, then i'll re-encode to a web friendly format, and upload to my site and hope that works well
⤋ Read More
@kat@yarn.girlonthemoon.xyz Yiha! I reckon the video is a bit squished together on the horizontal axis. Maybe your video site messed something up in postprocessing? No idea. Anyway, you’re already better at guitar than I ever was.
If you don’t wanna buy a tripod, you could make yourself a makeshift one with some sort of a sandbag, cherry pit pillow or an old, cut off and sewn shut trouser leg section filled with rice, lentils, etc. This gives you a shapeable surface where you can simply rest the camcorder on. It allows for some limited vertical up and down pitch. Obviously, that won’t work for extreme angles, but might be just enough for your application of recording at your desk. You just have to watch out for the side to side roll, this could otherwise lead to a slanted sailboat video. ;-)
need to come up with ideas for camcorder videos… i have one but it’s just ‘talk in front of camera about fave songs i listened to in 2024’ and i wanna do more fun things even though rambling in front of cam is already fun af
i like this little ideas utility i’ve been using like i keep pulling up the idea table to see what i’ve added and it makes me wanna start one of them like the CLI app i wanna write in golang with charmbracelet’s bubbletea even though i only have a vague idea of what i want in a CLI app
i had ideas for my fancy new idea table list (https://github.com/IonicaBizau/idea) that i’ve fallen in love with but i forgot what they were…
really wanna make an ssh zine app inspired by a telnet zine cms i found on github. i’m gonna probably go ahead with the telnet zine idea i have if i can get people for it but if i could build my own ssh mirror for it with golang and the charmbracelet wish library that’d be epic
Hi everybody! I just created this account and I have absolutely no idea if this works… but it does seem promising!
↳
In-reply-to
»
@doesnm So the user should then set
⤋ Read More
nick = _@domain.tld in the twtxt.txt?
hmm any ideas how to fix this case when there is no nick and it on a shared tilde hosting? http://darch.dk/timeline/profile?url=https://tilde.club/~deepend/twtxt.txt
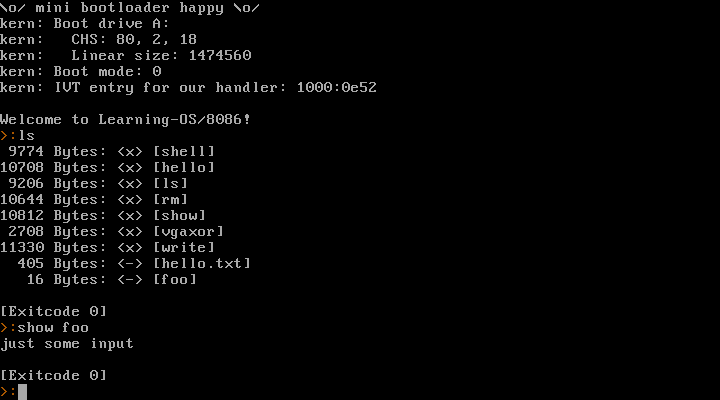
I’ve been making a little toy operating system for the 8086 in the last few days. Now that was a lot of fun!
I don’t plan on making that code public. This is purely a learning project for myself. I think going for real-mode 8086 + BIOS is a good idea as a first step. I am well aware that this isn’t going anywhere – but now I’ve gained some experience and learned a ton of stuff, so maybe 32 bit or even 64 bit mode might be doable in the future? We’ll see.
It provides a syscall interface, can launch processes, read/write files (in a very simple filesystem).
Here’s a video where I run it natively on my old Dell Inspiron 6400 laptop (and Warp 3 later in the video, because why not):
https://movq.de/v/893daaa548/los86-p133-warp3.mp4
(Sorry for the skewed video. It’s a glossy display and super hard to film this.)
It starts with the laptop’s boot menu and then boots into the kernel and launches a shell as PID 1. From there, I can launch other processes (anything I enter is a new process, except for the exit at the end) and they return the shell afterwards.
And a screenshot running in QEMU:
↳
In-reply-to
»
For Example:
⤋ Read More
after thinking and researching about it, yep, I agree that WebFinger is a good idea.
For example reading here: https://bsky.social/about/blog/4-28-2023-domain-handle-tutorial
I wasn’t considering some scenarios, like multiple accounts for a single domain (See ‘How can I set and manage multiple subdomain handles?’ in the link above)
Haha! I love the idea of this place! feels like BBS made a baby with Twtxt
[lang=en] Random idea: twtxt.txt files should be named tw.txt instead.
↳
In-reply-to
»
Fuck me dead, what a giant piece of shit. On my Linux work laptop I have the problem that some unknown snakeoil "security" junk is dropping any IPv4 connections to ports 80 and 443. All other ports and IPv6 seem unaffected. I get an immediate "connection refused" when trying to estabslish a connection.
⤋ Read More
Thank you, @movq@www.uninformativ.de! Luckily, I can disable it. I also tried it, no luck, though. But the problem is, I don’t really know how much snakeoil actually runs on my machine. There is definitely a ClownStrike infestation, I stopped the falcon sensor. But there might be even more, I’ve no idea. From the vague answers I got last time, it feels like even the UHD/IT guys don’t know what is in use. O_o
Yeah, it is definitely something on my laptop that rejects connections to IPv4 ports 80 and 443. All other devices here can access the stuff without issue, only this work machine is unable to. The “Connection refused” happens within a few milliseconds.
Unfortunately, I do not have the slightest idea how it works. But maybe I can look into that tomorrow. Kernel modules are a very good hint, thank you! <3
You’re right, it might be some sort of fail-safe mechanism. But then, why just block IPv4 and not also IPv6? But maybe because the VPN and company servers require IPv4, there is zero IPv6 support. (Yeah, don’t ask, I don’t understand it either.)
Fuck me dead, what a giant piece of shit. On my Linux work laptop I have the problem that some unknown snakeoil “security” junk is dropping any IPv4 connections to ports 80 and 443. All other ports and IPv6 seem unaffected. I get an immediate “connection refused” when trying to estabslish a connection.
I had this problem four weeks ago on Friday morning the very first time at home. On Thursday evening, everything was perfectly fine. Eventually, I plugged in the LAN cable in the office and everything got automatically fixed. Nobody can explain what’s happening.
Then, last week Friday morning out of the blue, the same issue was back. So, I went to the office yesterday and it got fixed again by plugging in the network cable. This evening, I have exactly the same bloody problem again.
What the hell is going on? Does anyone have any ideas? I’m certainly not an expert, but I don’t see anything suspicious in iptables or nft rules. I also do not see anything showing up in /var/log/kern.log. Even tried to stop firewalld, flush the iptables and nft rules, but that didn’t result in any changes.
↳
In-reply-to
»
@sorenpeter hey!
I'm watching that now your .txt is pointing to https://darch.dk/twtAgent.php
⤋ Read More
Yes it work: 2024-12-01T19:38:35Z twtxt/1.2.3 (+https://eapl.mx/twtxt.txt; @eapl) :D
The .log is just a simple append each request. The idea with the .cvs is to have it tally up how many request there have been from each client as a way to avoid having the log file grow too big. And that you can open the .cvs as a spreadsheet and have an easy overview and filtering options.
Access to those files are closed to the public.
↳
In-reply-to
»
@sorenpeter hey!
I'm watching that now your .txt is pointing to https://darch.dk/twtAgent.php
⤋ Read More
@eapl.mx@eapl.mx Yes, the idea is to add User Agent support to #Timeline.
Right now it just adds every request to a growing log file, but I have also been working on a way to analyse it, so it only saves the time of the latest request.
I’m not sure how to make it part of timeline itself, since it requeses that you redirect/rewrite from twtAgent.php to the acctual twtxt.txt
Help with making Timeline send proper User Agents to others would be much appreciated:)
You were mentioned in: https://eapl.mx/twtxt.txt#:~:text=2024-12-01T05:42:13Z
@sorenpeter@darch.dk hey!
I’m watching that now your .txt is pointing to https://darch.dk/twtAgent.php
What are you trying? Catching the Headers as in https://twtxt.readthedocs.io/en/latest/user/discoverability.html ? (I think it’s a clever idea BTW)
And is it something you plan to add to timeline?
@sorenpeter@darch.dk hey!
I’m watching that now your .txt is pointing to https://darch.dk/twtAgent.php
What are you trying? Catching the Headers as in https://twtxt.readthedocs.io/en/latest/user/discoverability.html ? (I think it’s a clever idea BTW)
And is it something you plan to add to timeline?
@sorenpeter@darch.dk hey!
I’m watching that now your .txt is pointing to https://darch.dk/twtAgent.php
What are you trying? Catching the Headers as in https://twtxt.readthedocs.io/en/latest/user/discoverability.html ? (I think it’s a clever idea BTW)
And is it something you plan to add to timeline?
https://terokarvinen.com/2021/calendar-txt/ keep your calendar in a simple text file. I love the idea #cli
↳
In-reply-to
»
Giving paper notebooks another try. I love paper notebooks. The problem is that I'm very chaotic writing my ideas.
⤋ Read More
@movq@www.uninformativ.de I’m all in on paper. In fact I noted down a todo item today on a physical sheet of paper when I was on the phone with a workmate. It then occurred to me that I could have just written it in a scratch file.
The parchment, on the other hand, might be a bit wasteful for just temporary ideas that are not perfectly layed out yet.
Giving paper notebooks another try. I love paper notebooks. The problem is that I’m very chaotic writing my ideas.
Easy run: 3.13 miles, 00:09:51 average pace, 00:30:54 duration
nice chill run. first day where my resting heart rate was back down to low 50s. no idea what was going on because i did not feel sick but maybe it was just all the stress from life and a crazy october?
#running
↳
In-reply-to
»
Thank you, @eapl.me! No need to apologize in the introduction, all good. :-)
⤋ Read More
Regarding section 4 about feed discovery: Yeah, non-HTTP transport protocols are an issue as they do not have
User-Agentheaders. How exactly do you envision thediscovery_urlto work, though?
This is from a twt of mine from January 2022:
https://www.uninformativ.de/files/twtxt/2022%2D01%2D22%2D%2Dfollow%2Dendpoint.md
(This idea gets lost all the time, so I put it into a file now. 😅)
Not sure if this is what @eapl.me@eapl.me had in mind, obviously.
↳
In-reply-to
»
@eapl.me here are my replies (somewhat similar to Lyse's and James')
⤋ Read More
@sorenpeter@darch.dk Section 7 on emojis: Exactly that, it’s an avatar for text interfaces. The metadata name needs tweaking, but that’s a cool idea. If I implemented this in my client, I’d make the text avatar overridable by the user, though. Otherwise I’d probably only see boxes for everbody in my terminal. :-D
↳
In-reply-to
»
Thanks @lyse! I'm replying here https://text.eapl.mx/reply-to-lyse-about-twtxt
⤋ Read More
Thank you, @eapl.me@eapl.me! No need to apologize in the introduction, all good. :-)
Section 3: I’m a bit on the fence regarding documenting the HTTP caching headers. It’s a very general HTTP thing, so there is nothing special about them for twtxt. No need for the Twtxt Specification to actually redo it. But on the other hand, a short hint could certainly help client developers and feed authors. Maybe it’s thanks to my distro’s Ngninx maintainer, but I did not configure anything for the Last-Modified and ETag headers to be included in the response, the web server just already did it automatically.
The more that I think about it while typing this reply, the more I think your recommendation suggestion is actually really great. It will definitely beneficial for client developers. In almost all client implementation cases I’d say one has to actually do something specifically in the code to send the If-Modified-Since and/or If-None-Match request headers. There is no magic that will do it automatically, as one has to combine data from the last response with the new request.
But I also came across feeds that serve zero response headers that make caching possible at all. So, an explicit recommendation enables feed authors to check their server setups. Yeah, let’s absolutely do this! :-)
Regarding section 4 about feed discovery: Yeah, non-HTTP transport protocols are an issue as they do not have User-Agent headers. How exactly do you envision the discovery_url to work, though? I wouldn’t limit the transports to HTTP(S) in the Twtxt Specification, though. It’s up to the client to decide which protocols it wants to support.
Since I currently rely on buckket’s twtxt client to fetch the feeds, I can only follow http(s):// (and file://) feeds. But in tt2 I will certainly add some gopher:// and gemini:// at some point in time.
Some time ago, @movq@www.uninformativ.de found out that some Gopher/Gemini users prefer to just get an e-mail from people following them: https://twtxt.net/twt/dikni6q So, it might not even be something to be solved as there is no problem in the first place.
Section 5 on protocol support: You’re right, announcing the different transports in the url metadata would certainly help. :-)
Section 7 on emojis: Your idea of TUI/CLI avatars is really intriguing I have to say. Maybe I will pick this up in tt2 some day. :-)
This morning (and a little bit of the afternoon) the idea of having a full referenced archive of twtxts on the web has consumed me a bit. I am talking about something similar to the email archives one see online, but for twtxts, and a more personal level. Such archive would be available, even if the involved feeds are long gone, because feeds will be treated as received emails.
↳
In-reply-to
»
Righto, @eapl.me, ta for the writeup. Here we go. :-)
⤋ Read More
@eapl.me@eapl.me here are my replies (somewhat similar to Lyse’s and James’)
Metadata in twts: Key=value is too complicated for non-hackers and hard to write by hand. So if there is a need then we should just use #NSFS or the alt-text file in markdown image syntax
if something is NSFWIDs besides datetime. When you edit a twt then you should preserve the datetime if location-based addressing should have any advantages over content-based addressing. If you change the timestamp the its a new post. Just like any other blog cms.
Caching, Yes all good ideas, but that is more a task for the clients not the serving of the twtxt.txt files.
Discovery: User-agent for discovery can become better. I’m working on a wrapper script in PHP, so you don’t need to go to Apaches log-files to see who fetches your feed. But for other Gemini and gopher you need to relay on something else. That could be using my webmentions for twtxt suggestion, or simply defining an email metadata field for letting a person know you follow their feed. Interesting read about why WebMetions might be a bad idea. Twtxt being much simple that a full featured IndieWeb sites, then a lot of the concerns does not apply here. But that’s the issue with any open inbox. This is hard to solve without some form of (centralized or community) spam moderation.
Support more protocols besides http/s. Yes why not, if we can make clients that merge or diffident between the same feed server by multiples URLs
Languages: If the need is big then make a separate feed. I don’t mind seeing stuff in other langues as it is low. You got translating tool if you need to know whats going on. And again when there is a need for easier switching between posting to several feeds, then it’s about building clients with a UI that makes it easy. No something that should takes up space in the format/protocol.
Emojis: I’m not sure what this is about. Do you want to use emojis as avatar in CLI clients or it just about rendering emojis?
↳
In-reply-to
»
I've been thinking of a few improvements for the next generation of twtxt spec, let me know if these are useful or interesting :) https://text.eapl.mx/a-few-ideas-for-a-next-twtxt-version
⤋ Read More
Righto, @eapl.me@eapl.me, ta for the writeup. Here we go. :-)
Metadata on individual twts are too much for me. I do like the simplicity of the current spec. But I understand where you’re coming from.
Numbering twts in a feed is basically the attempt of generating message IDs. It’s an interesting idea, but I reckon it is not even needed. I’d simply use location based addressing (feed URL + ‘#’ + timestamp) instead of content addressing. If one really wanted to, one could hash the feed URL and timestamp, but the raw form would actually improve disoverability and would not even require a richer client. But the majority of twtxt users in the last poll wanted to stick with content addressing.
yarnd actually sends If-Modified-Since request headers. Not only can I observe heaps of 304 responses for yarnds in my access log, but in Cache.FetchFeeds(…) we can actually see If-Modified-Since being deployed when the feed has been retrieved with a Last-Modified response header before: https://git.mills.io/yarnsocial/yarn/src/commit/98eee5124ae425deb825fb5f8788a0773ec5bdd0/internal/cache.go#L1278
Turns out etags with If-None-Match are only supported when yarnd serves avatars (https://git.mills.io/yarnsocial/yarn/src/commit/98eee5124ae425deb825fb5f8788a0773ec5bdd0/internal/handlers.go#L158) and media uploads (https://git.mills.io/yarnsocial/yarn/src/commit/98eee5124ae425deb825fb5f8788a0773ec5bdd0/internal/media_handlers.go#L71). However, it ignores possible etags when fetching feeds.
I don’t understand how the discovery URLs should work to replace the User-Agent header in HTTP(S) requests. Do you mind to elaborate?
Different protocols are basically just a client thing.
I reckon it’s best to just avoid mixing several languages in one feed in the first place. Personally, I find it okay to occasionally write messages in other languages, but if that happens on a more regularly basis, I’d definitely create a different feed for other languages.
Isn’t the emoji thing “just” a client feature? So, feed do not even have to state any emojis. As a user I’d configure my client to use a certain symbol for feed ABC. Currently, I can do a similar thing in tt where I assign colors to feeds. On the other hand, what if a user wants to control what symbol should be displayed, similar to the feed’s nick? Hmm. But still, my terminal font doesn’t even render most of emojis. So, Unicode boxes everywhere. This makes me think it should actually be a only client feature.