↳
In-reply-to
»
Finally I propose that we increase the Twt Hash length from
⤋ Read More
7 to 12 and use the first 12 characters of the base32 encoded blake2b hash. This will solve two problems, the fact that all hashes today either end in q or a (oops) 😅 And increasing the Twt Hash size will ensure that we never run into the chance of collision for ions to come. Chances of a 50% collision with 64 bits / 12 characters is roughly ~12.44B Twts. That ought to be enough! -- I also propose that we modify all our clients and make this change from the 1st July 2025, which will be Yarn.social's 5th birthday and 5 years since I started this whole project and endeavour! 😱 #Twtxt #Update
@eapl.me@eapl.me I honestly believe you are overreacting here a little bit 🤣 I completely emphasize with you, it can be pretty tough to feel part of a community at times and run a project with a kind of “democracy” or “vote by committee”. But one thing that life has taught me about open source projects and especially decentralised ecosystems is that this doesn’t really work.
It isn’t that I’ve not considered all the other options on the table (which can still be), it’s just that I’ve made a decision as the project lead that largely helped trigger a rebirth of the use of Twtxt back in July 1 2020. There are good reasons not to change the threading model right now, as the changes being proposed are quite disruptive and don’t consider all the possible things that could go wrong.
We havet an AI assistant at work, new version came out today “nearby restaurant recommendations” mentioned. Gotta try that!
Ask it where I can get a burger, knowing there’s 3 spots that had it on the menu, AI says there’s none. Ask it to list all the restaurants nearby it can check… it knows 3, of the 10 or so around, but 1/3, even has a burger, on the menu.
Ask it to list the whole menu at restaurant 1: it hallucinates random meals, none of which they had (I ate there).
Restaurant 2 (the one most people go to, so they must have at least tested it with this one): it lists the soup of the day and ¾ meals available. Incomplete, but better than false.
Restaurant 3: it says “food” and gives a general description of food. You have to be fucking kidding me!
“BuT cAnInE, tHe A(G)i ReVoLuTiOn Is NoW”
Trinity Desktop Environment R14.1.4 released
The Trinity Desktop Environment, the modern-day continuation of the KDE 3.x series, has released version R14.1.4. This maintenance release brings new vector wallpapers and colour schemes, support for Unicode surrogate characters and planes above zero (for emoji, among other things), tabs in kpdf, transparency and other new visual effects for Dekorator, and much more. TDE R14.1.4 is already available for a variety of Linux distributions, and c … ⌘ Read more
Gaza blockade depletes World Food Programme stocks + 1 more story
North Korea confirms sending troops to Russia as a defense pact; Gaza blockade leaves World Food Programme out of supplies, risking starvation for millions. ⌘ Read more
I just fixed a bug in tt’s reply to parent feature. Previously, when the message tree looked like the following
Message
├╴Reply 1
│ └╴Subreply
└╴Reply 2
and “Reply 2” was selected, pressing A to reply to the parent should have picked “Message”. However, a reply to “Reply 2” was composed instead. The reason was a precausiously introduced safety guard to abort the parent search which stopped at “Subreply”, because its subject didn’t match “Reply 2”’s. It was originally intended to abort on a completely different message conversation root. Just in case. Turns out that this thoght was flawed.
Fixing bugs by only removing code is always cool. :-)
↳
In-reply-to
»
Can you beat me at the circle game? 😂 https://neal.fun/perfect-circle/
⤋ Read More
Can you automate the drawing with a script? On X11, you can:
#!/bin/sh
# Position the pointer at the center of the dot, then run this script.
sleep 1
start=$(xdotool getmouselocation --shell)
eval $start
r=400
steps=100
down=0
for step in $(seq $((steps + 1)) )
do
# pi = 4 * atan(1)
new_x=$(printf '%s + %s * c(%s / %s * 2 * (4 * a(1)))\n' $X $r $step $steps | bc -l)
new_y=$(printf '%s + %s * s(%s / %s * 2 * (4 * a(1)))\n' $Y $r $step $steps | bc -l)
xte "mousemove ${new_x%%.*} ${new_y%%.*}"
if ! (( down ))
then
xte 'mousedown 1'
down=1
fi
done
xte 'mouseup 1'
xte "mousemove $X $Y"
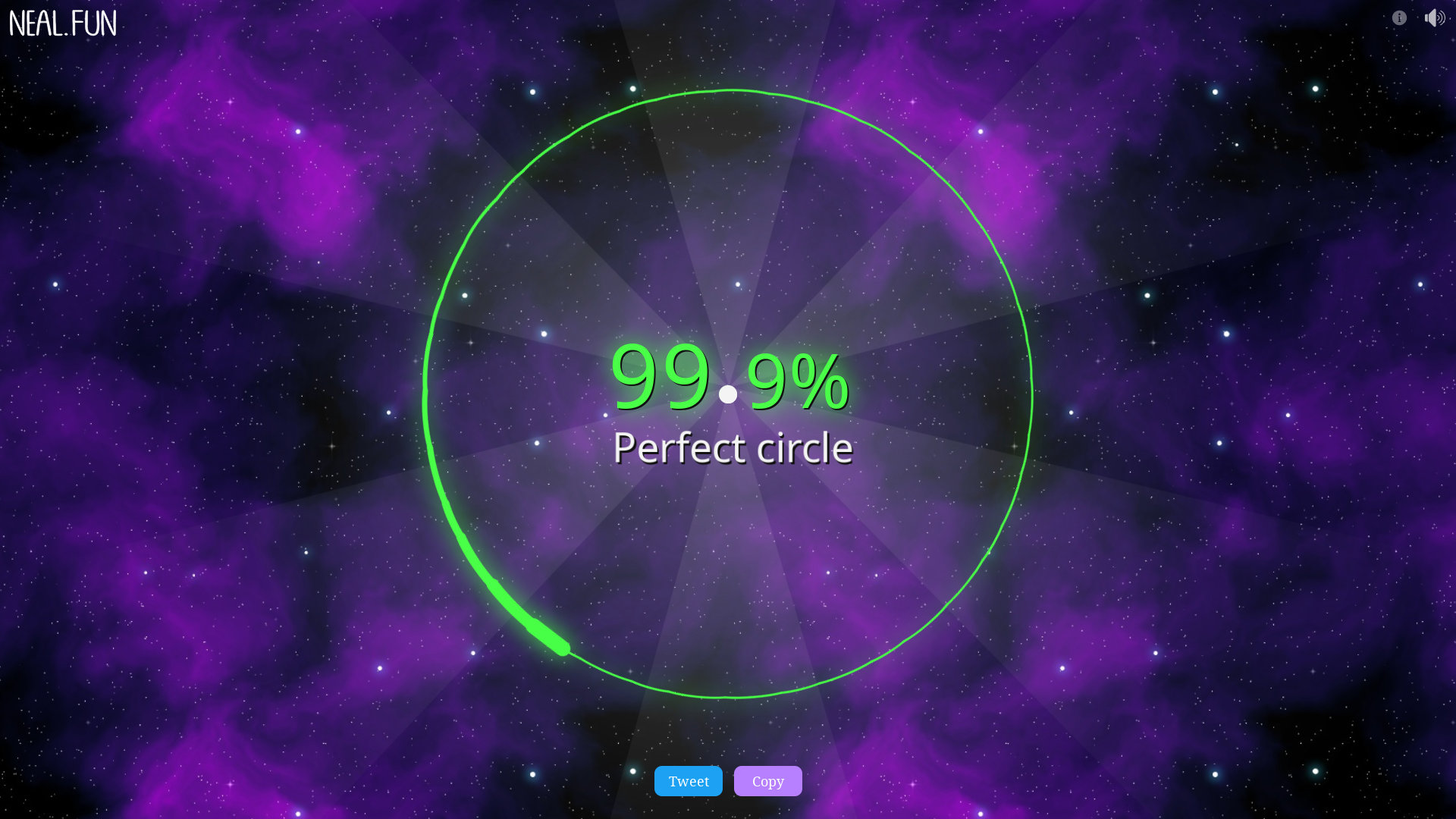
Interestingly, you can abuse the scoring system (not manually, only with a script). Since the mouse jumps to the locations along the circle, you can just use very few steps and still get a great score because every step you make is very accurate – but the result looks funny:
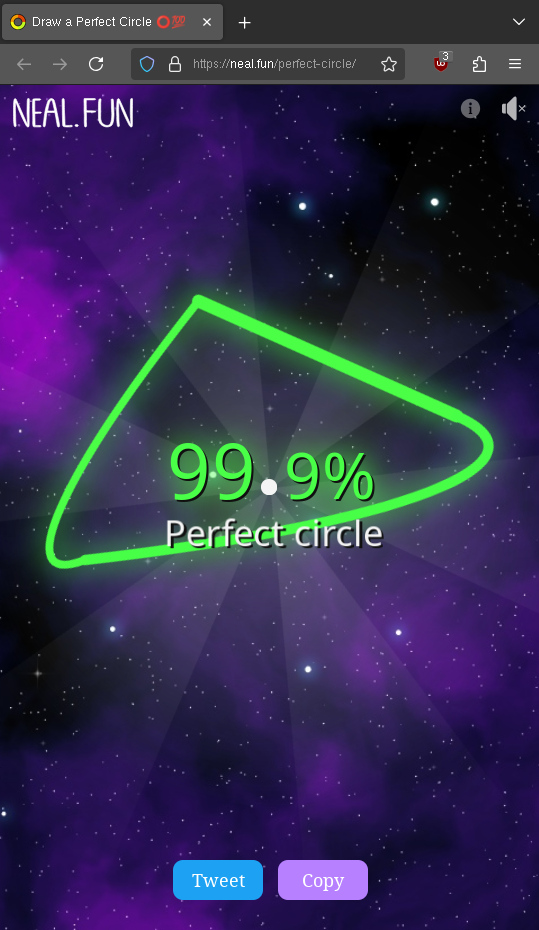
🥴
Atualizaei meu gopher com um passo a passo para compartilhar a tela no sway: gopher://vaporhole.xyz/1/~orahcio
test test 1 2 3
This is something for @movq@www.uninformativ.de and old OS hobbyists alike: FreeDOS 1.4! Get it while it’s hot!
Regex Isn’t Hard - Tim Kellogg 👈 this is a pretty good conscience article on regexes, and I agree, regex isn’t that hard™ – However I think I can make the TL;DR even shorter 😅
Regex core subset (portable across languages):
Character sets
• a matches “a”
• [a-z] any lowercase
• [a-zA-Z0-9] alphanumeric
• [^ab] any char but a or b
Repetition (applies to the preceding atom)
• ? zero or one
• * zero or more
• + one or more
Groups
• (ab)+ matches “ab”, “abab”, …
• Capture for extract/substitute via $1 or \1
Operators
• foo|bar = foo or bar
• ^ start anchor
• $ end anchor
Ignore non‑portable shortcuts: \w, ., {n}, *?, lookarounds.
↳
In-reply-to
»
#event:abc123 Go Meetup – Sat Apr 27, 3pm @ Darling Harbour
⤋ Read More
#event:abc123 RSVP: yes +1
Hmmm there’s a bug somewhere in the way I’m ingesting archived feeds 🤔
sqlite> select * from twts where content like 'The web is such garbage these days%';
hash = 37sjhla
feed_url = https://twtxt.net/user/prologic/twtxt.txt/1
content = The web is such garbage these days 😔 Or is it the garbage search engines? 🤔
created = 2024-11-14T01:53:46Z
created_dt = 2024-11-14 01:53:46
subject = #37sjhla
mentions = []
tags = []
links = []
sqlite>
↳
In-reply-to
»
@lyse It wasn’t our building, yeah, luckily. But I’m pretty scared it might happen some day. I think I’ll put more effort into preparing for that. But whatever I do, it would be horrific to lose all your stuff and the memories attached to it …
⤋ Read More
@prologic@twtxt.net @bmallred@staystrong.run Ah, I just found this, didn’t see it before:
https://restic.net/#compatibility
So, yeah, they do use semver and, yes, they’re not at 1.0.0 yet, so things might break on the next restic update … but they “promise” to not break things too lightheartedly. Hm, well. 😅 Probably doesn’t make a big difference (they don’t say “don’t use this software until we reach 1.0.0”).
↳
In-reply-to
»
Some A hole has been trying to pull every single Twtxt feed that existed/still exists since forever. How do I know? Welp' They've been querying my Timeline™ instance for all of it, every single twtxt file and twt Hash they can find. 😆🤦 It must have been going on for days and I have just noticed... + it's all coming from the same ASN
⤋ Read More
AS136907 HWCLOUDS-AS-AP HUAWEI CLOUDS
@prologic@twtxt.net This shi_ is as fun as it is frustrating! 😆 the bot is poking at me from a different ASN now, Alibaba’s.
- Short term solution: I’ve geo-locked my Timeline instance since I’m the only one using it (and I only do so for reading twts when I’m away from terminal).
- Long term: I took a look at your Caddy WAF but couldn’t figure things out on my own; until then, I’ll be poking at Caddy-Defender, maybe throw in a Crowdsec for lols… #FUN
Google is a monopolist in online advertising tech, judge says
Google acted illegally to maintain a monopoly in some online advertising technology, a federal judge ruled on Thursday, adding to legal troubles that could reshape the $1.86 trillion company and alter its power over the internet. Judge Leonie Brinkema of the U.S. District Court for the Eastern District of Virginia said in a 115-page ruling that Google had broken the law to build its dominance over the largely … ⌘ Read more
Signs of life detected on distant planet + 1 more story
Plus, WHO finalizes pandemic treaty ⌘ Read more
↳
In-reply-to
»
The original twt is unavailable. It may have been edited or deleted, or is from an unknown or muted feed.
⤋ Read More
@david@collantes.us If I run
printf '%s\n%s\n%s' 'https://aelaraji.com/twtxt.txt' '2025-04-16T22:49:11+00:00' "Am I tripping or `rsync` is actually THIS effing faster than `scp`!!? 🫨" | b2sum -l 256 | awk '{ print $1 }' | xxd -r -p | base32 | tr -d '=' | tr 'A-Z' 'a-z' | tail -c 8
I have xqfsv6a. It is raw text
But… If I change de date to 2025-04-16T22:49:11Z I have si4er3q.
Even though I really do like the shell, I always use Dolphin to mount my digicam SD card and copy the photos onto my computer. I finally added a context menu item in Dolphin to create a forest stroll directory with the current date in order to save some typing:

The following goes in ~/.local/share/kservices5/ServiceMenus/galmkdir.desktop:
[Desktop Entry]
Type=Service
X-KDE-ServiceTypes=KonqPopupMenu/Plugin,inode/directory
Actions=Waldspaziergang;
[Desktop Action Waldspaziergang]
Name=Heutigen Waldspaziergang anlegen…
Icon=folder-green
Exec=~/src/gelbariab/galmkdir "%f"
In order to update the KDE desktop cache and make this action menu item available in Dolphin, I ran:
kbuildsycoca5
The referenced galmkdir script looks like that:
#!/bin/sh
set -e
current_dir="$1"
if [ -z "$current_dir" ]; then
echo "Usage: $0 DIRECTORY" >&2
exit 1
fi
dir="$(kdialog \
--geometry 350x50 \
--title "Heutigen Waldspaziergang anlegen" \
--inputbox "Neues Verzeichnis in „$current_dir“ anlegen:" \
"waldspaziergang-$(date +%Y-%m-%d)")"
mkdir "$current_dir/$dir"
dolphin "$current_dir/$dir"
This solution is far from perfect, though. Ideally, I’d love to have it in the “Create New” menu instead of the “Actions” menu. But that doesn’t really work. I cannot define a default directory name, not to mention even a dynamic one with the current date. (I would have to update the .desktop file every day or so.) I also failed to create an empty directory. I somehow managed to create a directory with some other templates in it for some reason I do not really understand.
Let’s see how that works out in the next days. If I like it, I might define a few more default directory names.
↳
In-reply-to
»
@prologic @bender @eapl.me I think opening another file is a bad idea because it adds complexity to the clients, breaks the single feed and I think keeping legacy clients will be more complex to add new features in the future. A modern approach is important.
I'll be honest, I'm a bit tired of the fight around the direct message. Perhaps, we can remove it as an extension and use the alternative @prologic . My suggestion apparently doesn't like to the community. I have no problem with remove it.
⤋ Read More
@andros@twtxt.andros.dev how often do you send a private message on the Fediverse? How often do you send PGP/SMIME encrypted emails? Are there other tools that are more suitable for the task? If implementing direct/private messages on twtxt scratches an itch (you know, that hobbyist itch we all get from time to time), then don’t give up so easily. Worse comes to worse, and your feed becomes too noisy, people can simply unfollow/mute.
I really don’t care about direct messages here, but I might be on that bottom 1%!
She was chatting with friends in a Lyft. Then someone texted her what they said
Comments ⌘ Read more
First global fee targets ship emissions + 1 more story
High US-China tariffs disrupt trade, worry businesses; major nations agree on first global fee for ship emissions ⌘ Read more
↳
In-reply-to
»
Based on a recent study of the brains of mice I estimated the human brain to have 200B cells/neurons and 50,000T connections. We have several orders of magnitude to go before we reach that kind of scale with these fucking stupid Big LLMs 🤣 And the best part of all? 🧐 It is estimated that the human brain only consumes the equivalent of 5 Watts of power !!! 🤣🤣🤣
⤋ Read More
Yeah same order of magnitude 👌 No relation mice other than the recent study that precisely measured the number of cells and connections in 1 cubic mm of brain tissue.
Pinta 3.0 brings major GTK4 overhaul
Over 15 years ago, I wrote about the launch of a Paint.NET clone for Linux, called Pinta, written in GTK. That was merely version 0.1, and over time, it’s become somewhat of a staple for many Linux users. The project just released version 3, which is a major revision, moving the application over to GTK4 and Libadwaita. Built on the robust GTK 4 toolkit and the sleek Libadwaita, Pinta 3.0 brings a redesigned user interface that’s faster, more responsive, and … ⌘ Read more
AI problems, top to bottom:
1: Open AI nerds, believe fine tuning a language model algorithm, will eventually produce an AGI god.
2: Subpar artists and techbros who can’t code, convinced AI image bashing and vibe coding, will help convince the dumber parts of Internet, they are a real deal.
3: Parasites, using AI to scam people, because they just want passive income, selling crap, made by an automated process.
Side: Adobe&co, killing Flash/old web, pricing new artists and developers out, to face learning curves of free tools, or use AI, peddled as solution.
↳
In-reply-to
»
I updated wordwrap.[ch] to more closely match the interface for string(2); it's now just that plus a margin. I also updated litclock and marquee to match. http://a.9srv.net/src/index.html
⤋ Read More
@anth@a.9srv.net Hahaha, for a second I thought that you implemented word splitting according to Swiss (.ch) rules. :-D
Btw, both manpage links string(2) and getields(2) (it’s missing an f) point into nothingness: http://a.9srv.net/src/wordwrap.2.html
I can’t help but notice line 9: http://a.9srv.net/src/wordwrap.c
And I reckon your finger slipped one key to the right for quore: http://a.9srv.net/src/litclock.1.html
Cool stuff! :-)
FreeDOS 1.4 released
With FreeDOS being, well, DOS, you’d think there wasn’t much point in putting out major releases and making big changes, and you’d mostly be right. However, being a DOS clone doesn’t mean there isn’t room for improvement within the confines of the various parts and tools that make up DOS, and that’s exactly where FreeDOS focuses its attention. FreeDOS 1.4 comes about three years after 1.2. This version includes an updated FreeCOM, Install program, and HTML Help system. This also includes i … ⌘ Read more
@prologic@twtxt.net I’m not sure if that’s an intended behaviour but twtxt.net’s home page doesn’t load more than 13 twts, no more pagination/infinite scrolling…
Page 1/1 of 13 Twts
hello friends i spent a couple hours today using a random string generator by charm CLI called hotdiva2000 to make a script that 1) generates a static index.html page 2) the page is a prompt generator where all the prompts are from hotdiva2000!!!!!
this makes more sense if you look at it check it out
↳
In-reply-to
»
I wonder if my current Linux installation will actually make it to 20 years:
⤋ Read More
$ head -n 1 /var/log/pacman.log
[2015-10-16 17:08] [PACMAN] Running 'pacman -r /mnt -Sy --cachedir=/mnt/var/cache/pacman/pkg base base-devel'
Mine is 4,5 years behind!
This is a reminder to have a look to S.M.A.R.T. data I guess O:)
↳
In-reply-to
»
We should look at this thread
https://github.com/snarfed/bridgy-fed/issues/1873
#twtxt
⤋ Read More
↳
In-reply-to
»
guys help how do i unmute a twt i accidentally hit the wrong button
⤋ Read More
@kat@yarn.girlonthemoon.xyz It’s very well hidden, it took me a while to find that. Go to “Settings” in the menu bar up top → “Profile and Privacy” (already selected) → on the right at “User Info” → “1 Muted” → click the link with the minus in the circle at the message you want to unmute.
↳
In-reply-to
»
@movq Not according to the output of
⤋ Read More
./yarnc debug <your feed url>:
OH wait! 😳 Why am I storing the timestamp as created = 2025-04-07T19:59:51Z ?! 😱 @movq@www.uninformativ.de’s feed shows:
2025-04-07T19:59:51+00:00 I wonder if my current Linux installation will actually make it to 20 years:
$ head -n 1 /var/log/pacman.log
[2011-07-07 11:19] installed filesystem (2011.04-1)
It’s not toooo far into the future.
It would be crazy … 20 years without reinstalling once … phew. 🥴
Hmmmm
↳
In-reply-to
»
@prologic What happened here – did I edit my twt or is this hash wrong? 🥴
⤋ Read More
@movq@www.uninformativ.de Not according to the output of ./yarnc debug <your feed url>:
znf6csa 2025-04-07T19:59:51+00:00 I wonder if my current Linux installation will actually make it to 20 years:
$ head -n 1 /var/log/pacman.log
[2011-07-07 11:19] installed filesystem (2011.04-1)
It’s not toooo far into the future.
It would be crazy … 20 years without reinstalling once … phew. 🥴
↳
In-reply-to
»
@prologic What happened here – did I edit my twt or is this hash wrong? 🥴
⤋ Read More
Doesn’t look like it Hmmm
sqlite> select * from twts where content LIKE '%Linux installation%';
hash = znf6csa
feed_url = https://www.uninformativ.de/twtxt.txt
content = I wonder if my current Linux installation will actually make it to 20 years:
$ head -n 1 /var/log/pacman.log
[2011-07-07 11:19] installed filesystem (2011.04-1)
It’s not toooo far into the future.
It would be crazy … 20 years without reinstalling once … phew. 🥴
created = 2025-04-07T19:59:51Z
subject = (#znf6csa)
mentions = []
tags = []
links = []
I wonder if my current Linux installation will actually make it to 20 years:
$ head -n 1 /var/log/pacman.log
[2011-07-07 11:19] installed filesystem (2011.04-1)
It’s not toooo far into the future.
It would be crazy … 20 years without reinstalling once … phew. 🥴
@prologic@twtxt.net, from IRC:
- Saving preferences is failing. Specifically trying to save “Open Links” on the same window. For sure it isn’t happening. Check errors on browser’s console.
- Search results pagination is broken. Search for “twtxt.net” and see it. Also, picking oldest/newest makes no difference on that search query.
↳
In-reply-to
»
This weekend (as some of you may now) I accidently nuke this Pod's entire data volume 🤦♂️ What a disastrous incident 🤣 I decided instead of trying to restore from a 4-month old backup (we'll get into why I hadn't been taking backups consistently later), that we'd start a fresh! 😅 Spring clean! 🧼 -- Anyway... One of the things I realised was I was missing a very critical Safety Controls in my own ways of working... I've now rectified this...
⤋ Read More
@prologic@twtxt.net Not sure if the confirmation helps at all. You just condition yourself to immediately press y on a daily basis.
Apart from that, aborting the removal should probably terminate the function with a non-zero exit code, something like return 1.
↳
In-reply-to
»
This weekend (as some of you may now) I accidently nuke this Pod's entire data volume 🤦♂️ What a disastrous incident 🤣 I decided instead of trying to restore from a 4-month old backup (we'll get into why I hadn't been taking backups consistently later), that we'd start a fresh! 😅 Spring clean! 🧼 -- Anyway... One of the things I realised was I was missing a very critical Safety Controls in my own ways of working... I've now rectified this...
⤋ Read More
So I re-write this shell alias that I used all the time alias dkv="docker rm" to be a much safer shell function:
dkv() {
if [[ "$1" == "rm" && -n "$2" ]]; then
read -r -p "Are you sure you want to delete volume '$2'? [Y/n] " confirm
confirm=${confirm:-Y}
if [[ "$confirm" =~ ^[Yy]$ ]]; then
# Disable history
set +o history
# Delete the volume
docker volume rm "$2"
# Re-enable history
set -o history
else
echo "Aborted."
fi
else
docker volume "$@"
fi
}